







SmoothQuant:大模型量化的高效利器
最近重新看了一些量化的内容,相比QAT,PTQ感觉也大有可为,后续可能也会多多使用一下PTQ。
随着人工智能技术的飞速发展,大型语言模型(LLMs)如GPT、BERT等在技术革新中扮演着至关重要的角色。这些模型凭借强大的自然语言处理能力和广泛的应用前景,推动了人工智能技术的深入发展。然而,随着模型规模的日益增大,计算和存储需求也急剧增加,给实际部署带来了巨大挑战。量化技术作为一种有效的优化手段,为解决这一问题提供了新思路。而SmoothQuant作为一种创新的训练后量化(PTQ)方法,以其独特的优势在压缩与加速之间实现了高效平衡。本文将深入解析SmoothQuant的原理、优势、应用场景以及开源项目,为大家提供全面的了解。
一、SmoothQuant概述
SmoothQuant由麻省理工学院(MIT)的Han Lab提出,是一种针对大模型的训练后量化方法。其核心理念在于平衡激活值和权重的量化难度,通过逐通道缩放平滑激活值分布,减少离群点的影响,从而实现高精度的模型压缩与加速。SmoothQuant的出现,为大型语言模型的量化提供了一种新的解决方案,有助于推动AI技术的广泛应用。
二、SmoothQuant技术原理
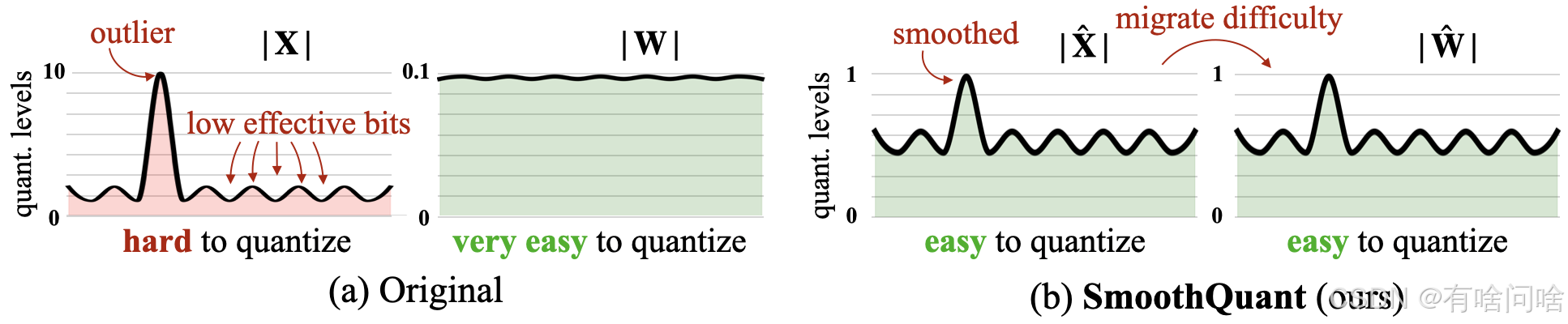
在大模型量化过程中,激活值量化相较于权重量化更具挑战性。激活值通常包含大量离群点,这些离群点会显著拉伸量化范围,增加量化误差,从而影响模型的精度。传统的逐通道量化方法尽管能够保留一定的精度,但与INT8等硬件加速内核不完全兼容,限制了其在实际应用中的推广。
SmoothQuant提出了一种基于平滑因子的逐通道缩放变换方法,通过数学等价的方式将激活值和权重重新分配,以平衡量化难度。具体而言,SmoothQuant对每个通道的激活值进行缩放,以平滑其分布;同时,对权重施加反向缩放,确保模型计算的等价性。这样的设计使得激活值的离群点对量化范围的拉伸作用得以缓解,同时使权重和激活值都能够较好地量化。核心思想是通过选择适当的平滑因子 s j s_j sj来实现激活和权重间的平衡。
平滑因子 s j s_j sj 计算
SmoothQuant中的平滑因子 s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2811
2811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











