







本文介绍一篇 ICCV 2019 的论文『 Disentangling Monocular 3D Object Detection』。详细信息如下:

论文链接:https://arxiv.org/abs/1905.12365
项目链接:https://research.mapillary.com/publication/MonoDIS/
01
动机
相比于较为成熟的2D目标检测技术,3D目标检测尚处于发展之中。而在3D目标检测领域,基于单目相机的方法又远远落后于基于多传感器融合的方法。使用单目相机做3D目标检测是个“ill-posed”问题,因为三维场景到二维图像的映射过程引入了模糊性。
当前使用神经网络解决单目相机3D检测问题大多存在两个特性:1.需要对3D目标框的长、宽、高、深度、角度、位置进行编码,这些属性的单位、范围不统一,若直接使用它们构造损失函数,一定程度上会影响网络的收敛过程;2.首先训练2D目标检测器,然后将3D目标检测模块集成进来,这种分阶段训练的方式并不是最优的。
基于上述问题,作者将3D目标框的属性参数在损失函数层面上分组,解耦它们之间的依赖关系,解决了这些属性在单位、范围上的不一致问题,减轻了网络收敛难度,使得2D目标检测网络和3D目标检测网络能够一起训练,达到端到端训练的目的。
针对2D目标检测任务,作者还引入了一种基于sIOU(signed Interp-over-Union)的损失函数提高性能;针对3D目标检测任务,作者引入了一个损失项用于得到3D目标框的检测置信度。
02
网络结构
基于单目相机的3D检测任务,即输入单张RGB图片,输出目标在相机坐标系下的3D框属性,如下图所示:

作者提出的MonoDIS网络可以分为Backbone、2D检测器和3D检测器3部分,下面分别介绍。
2.1 Backbone
Backbone的结构如下图所示:
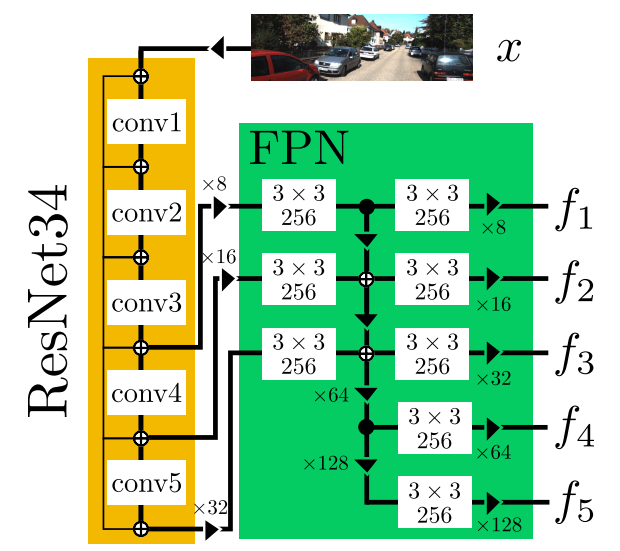
由上图可以看出,Backbone由ResNet34和FPN(Feature Pyramid Network)组成。在ResNet34中,使用InPlaceABN( iABNsync)+LeakyReLU替代BatchNorm+ReLU结构,其中LeakyReLU的negative slope为0.01。
这么做的目的是在不影响网络性能的前提下降低GPU显存的消耗,从而可以尝试较大的batch size或者较大的输入图片分辨率。Backbone的输入为RGB图像,输出为5种尺度的特征,分别记作 {f1,…,f5}。
2.2 2D目标检测
与RetinaNet中的检测部分类似,在Backbone输出的每个 后面接一个2D检测模块,2D检测模块的结构如下图所示:
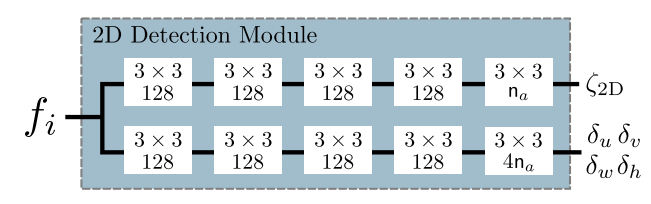
对于每个anchor输出5个信息,记作 ,使用这些信息构造预测框的属性:
表示2D预测框的置信度,记作 ;
表示预测框的中心点坐标,记作 , 表示这个anchor对应的cell在图像坐标系下的坐标, 表示这个anchor的预定义尺寸;
表示预测框的尺寸,记作
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1957
1957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









