






关注公众号,发现CV技术之美
近日,第 13 届 ICLR(International Conference on Learning Representations)国际学习表征会议公布了论文录用结果。本次大会共收到 11,565 篇有效论文投稿,录用率为 32.08%。
ICLR 是人工智能和深度学习领域的重要国际学术会议之一,会议聚焦于表征学习(通常称为深度学习)的前沿研究,涵盖深度学习理论、表征学习方法、计算机视觉、自然语言处理、强化学习、优化算法、硬件实现以及在音频、语音、机器人、生物学等多个领域的应用。ICLR 2025将于4月24日至28日在新加坡博览中心举行。
今年,腾讯优图实验室共有6篇论文被录用,内容涵盖多模态大语言模型、视觉-语言跨模态学习、人脸识别等研究方向,展示了腾讯优图实验室在人工智能领域的技术能力和研究成果。
以下为腾讯优图实验室的入选论文概览:
01
SaRA:基于渐进式稀疏低秩自适应的高效扩散模型微调方法
SaRA: High-Efficient Diffusion Model Fine-tuning with Progressive Sparse Low-Rank Adaptation
Teng Hu (上交), Jiangning Zhang, Ran Yi (上交), Hongrui Huang (上交), Yabiao Wang, Lizhuang Ma (上交)
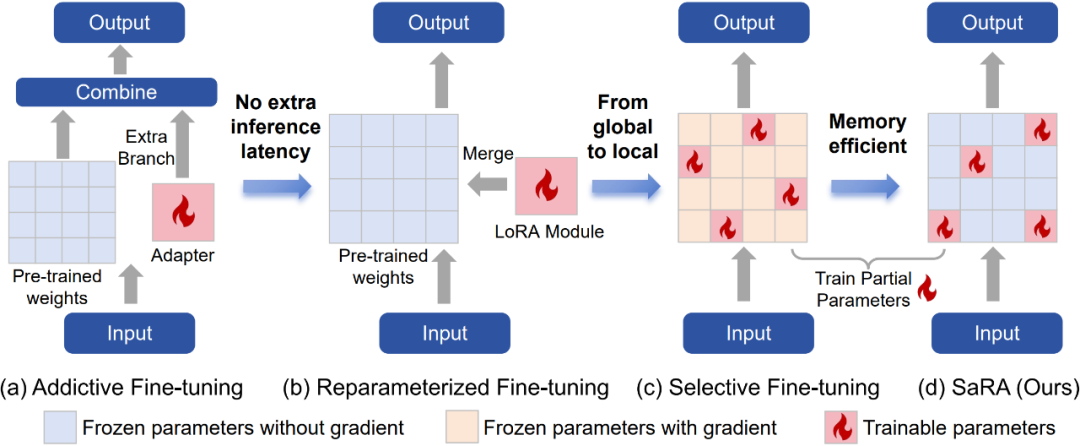
近年来,扩散模型的发展在图像和视频生成任务中取得了重大进展,像Stable Diffusion系列这样的预训练模型发挥了关键作用。受模型剪枝的启发(模型剪枝通过去除不重要的参数来减轻大型预训练模型的负担),我们提出了一种新颖的模型微调方法,以充分利用这些原本无效的参数,并使预训练模型具备新的特定任务能力。在这项工作中,我们首先研究了预训练扩散模型中参数的重要性,发现绝对值最小的10%到20%的参数对生成过程并无贡献。基于这一观察结果,我们提出了一种名为SaRA的方法,该方法重新利用这些暂时无效的参数,这相当于优化一个稀疏权重矩阵来学习特定任务的知识。为了减轻过拟合问题,我们提出了一种基于核范数的低秩稀疏训练方案,以实现高效的微调。此外,我们设计了一种新的渐进式参数调整策略,以充分利用重新训练/微调后的参数。最后,我们提出了一种新颖的无结构反向传播策略,该策略显著降低了微调过程中的内存成本。我们的方法增强了预训练模型在下游应用中的生成能力,并且在保持模型泛化能力方面优于诸如LoRA等传统微调方法。我们通过对Stable Diffusion模型进行微调实验来验证我们的方法,实验结果表明有显著的改进。SaRA还具有一个实际优势,即只需修改一行代码就能高效实现,并且可以与现有方法无缝兼容。
论文链接:
https://export.arxiv.org/abs/2409.06633
02
VEGA:图文混合多模态阅读理解
Learning Interleaved Image-Text Comprehension in Vision-Language Large Models
Chenyu Zhou(厦大), Mengdan Zhang, Peixian Chen, Chaoyou Fu(南大), Yunhang Shen, Xiawu Zheng(厦大), Xing Sun, Rongrong Ji(厦大)
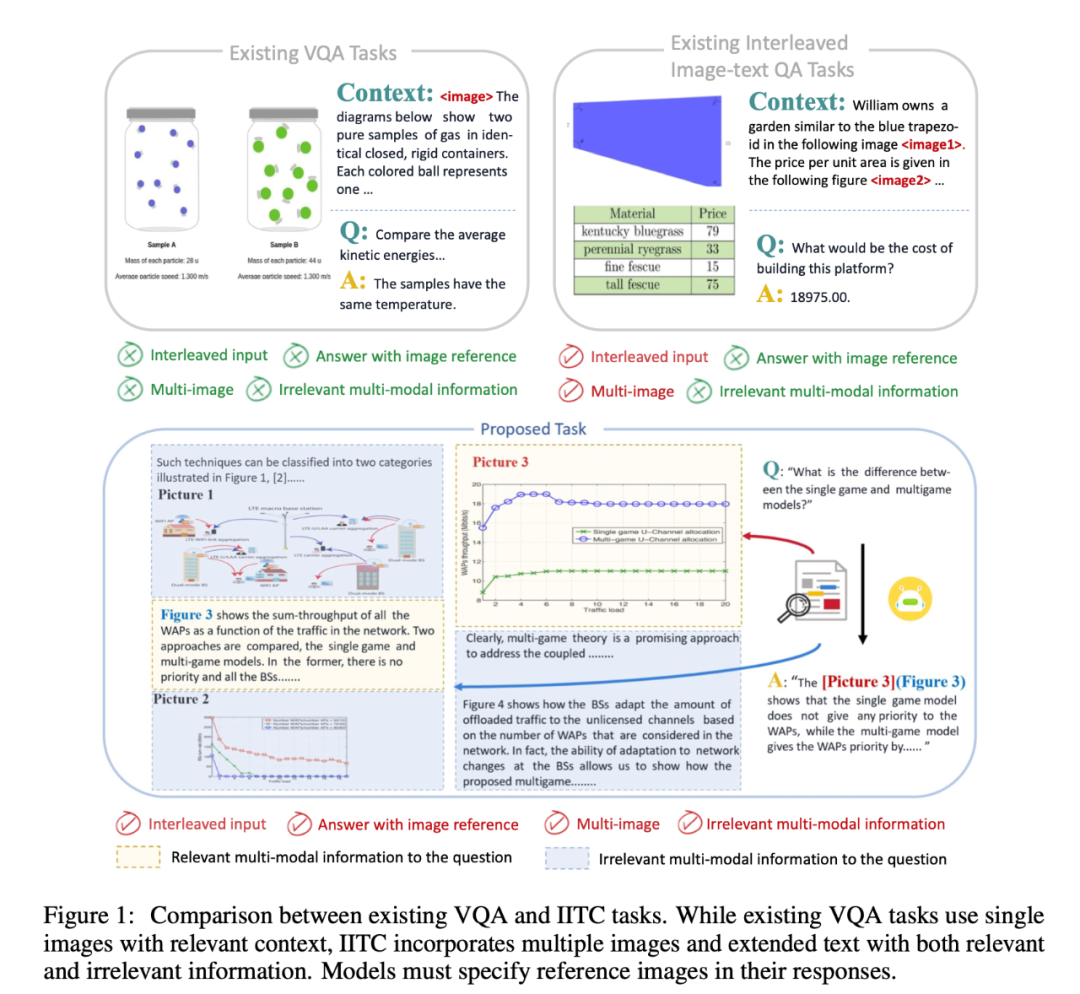
多模态大语言模型(MLLMs)的高速发展彰显了其在处理图文信息方面的强大潜力。然而,目前的多模态模型和方法主要集中于处理基础视觉问答(VQA)任务,这些任务通常只涉及与问题强相关的有限图片和文本信息。在实际应用中,尤其是文档理解领域,模型经常需要处理更为复杂的图文混合输入,这些输入不仅长度更长,而且可能包含冗余甚至误导性的信息。现有的主流MLLMs在处理此类复杂任务时表现不佳,且缺乏相应的Benchmark来评估模型在这些任务上的性能。我们提出了一个全新的多模态任务——图文混合阅读理解(Interleaved Image-Text Comprehension, IITC)。该任务要求模型处理包含复杂图文交错信息的输入,并在回答问题时明确指出其参考的图片。为了有效评估和提升模型在IITC任务上的表现,我们构建了VEGA数据集。该数据集专注于科学论文的理解,包含超过50,000篇科学论文的图文数据。我们对MLLM模型在VEGA数据集上进行了微调,并采用了一种多尺度、多任务的训练策略,得到VEGA-Base模型。实验结果显示,该模型在IITC任务中的图像关联准确率方面达到了85.8%,为IITC任务建立了一个强有力的Baseline。目前,VEGA数据集已全部开源,包含593,000条论文类型训练数据,2个不同任务的2,326条测试数据。
论文链接:
https://github.com/zhourax/VEGA
03
RocketEval:基于评分清单的高效自动化大语言模型评估
RocketEval: Efficient Automated LLM Evaluation via Grading Checklist
Tianjun Wei(城大), Wei Wen, Ruizhi Qiao, Xing Sun, Jianghong Ma(哈工深)
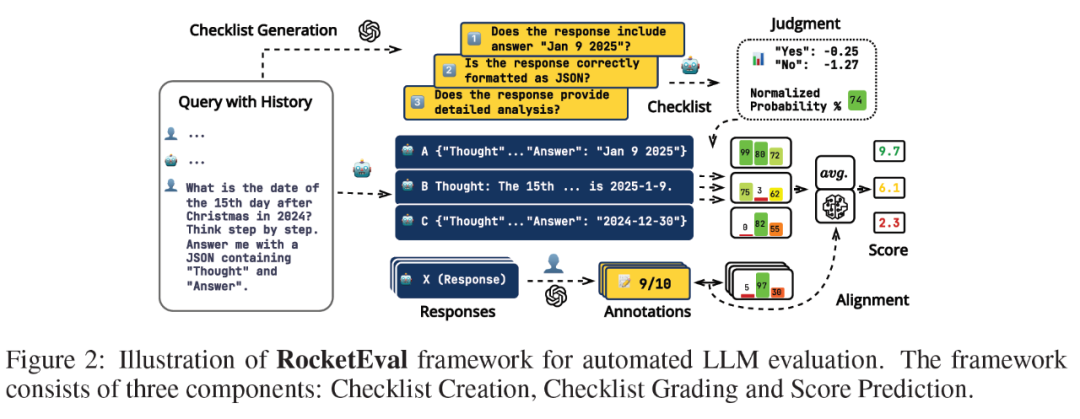
在多样化和具有挑战性的场景中评估大型语言模型(LLMs),对于将其与人类偏好对齐至关重要。为了减轻与人工评估相关的成本负担,利用强大的LLM作为评判者已成为一种受欢迎的方法。然而,这种方法面临几个挑战,包括高昂的费用、对隐私和安全的担忧以及可重复性。在本文中,我们提出了一种简单、可重复且准确的自动化评估方法,通过使用轻量级LLM作为评判者,名为RocketEval。最初,我们发现轻量级和强大LLM在评估任务中的性能差异主要源于它们缺乏进行全面分析的能力,而这也并不容易通过链式思维推理等技术来提升。通过将评估任务重新构建为一个使用特定实例清单的多方面问答,我们展示了轻量级LLM有限的判断准确性主要是由于高不确定性和位置偏见。为了应对这些挑战,我们引入了一种基于清单打分的自动化评估流程,旨在适应多种场景和问题。该流程包括创建清单、由轻量级大型语言模型对这些清单进行打分,以及重新加权清单评分以与监督信号进一步对齐。我们在自动化评估基准测试——MT-BENCH和WILDBENCH数据集上进行的实验显示,当使用Gemma-2-2B作为评判者时,RocketEval与人类偏好的相关性高达0.965,与GPT-4o相当。此外,RocketEval在大规模评估和比较场景下提供了超过50倍的节省成本。
04
ToVE:基于视觉专家知识迁移的高效视觉-语言学习
ToVE: Efficient Vision-Language Learning via Knowledge Transfer from Vision Experts
Yuanchen Wu(上海大学), Junlong Du, Ke Yan, Shouhong Ding, Xiaoqiang Li(上海大学)
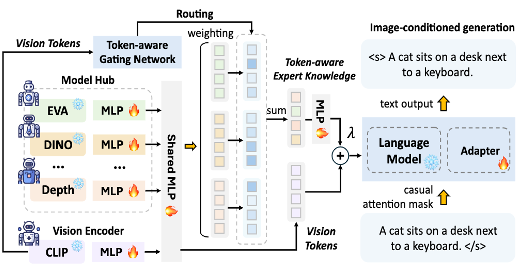
视觉-语言跨模态学习需要具备强大视觉感知能力,例如细粒度的物体识别和空间感知。近期研究通常依赖于在大量数据集上训练庞大的模型来拓展这些能力。本文提出了一种新框架ToVE,通过从视觉专家转移知识以实现高效的视觉-语言学习。具体而言,ToVE基于冻结的CLIP编码器为语言生成提供视觉令牌,并引入了多个视觉专家和一个细粒度的令牌感知门控网络,用以动态地将专家知识路由到视觉标记中。在知识转移阶段,本文提出了一种“残差知识转移”策略,不仅保留了视觉令牌的泛化能力,还能通过分离贡献较低的专家来提高推理效率。此外,本文还探索将专家知识合并到单个CLIP编码器中,获得知识增强的CLIP编码器,在推理过程中无需引入专家即可生成表征更强大的视觉令牌。实验结果表明,在图像描述、视觉问答、空间感知等各种视觉-语言任务中,ToVE在训练数据量减少两个数量级的情况下,仍能取得具有竞争力的性能。
05
UIFACE: 通过模型内在能力增强合成人脸识别的类内多样性
UIFace: Unleashing Inherent Model Capabilities to Enhance Intra-Class Diversity in Synthetic Face Recognition
Xiao Lin∗, Yuge Huang∗, Jianqing Xu, Yuxi Mi(复旦大学), Shuigeng Zhou(复旦大学), Shouhong Ding
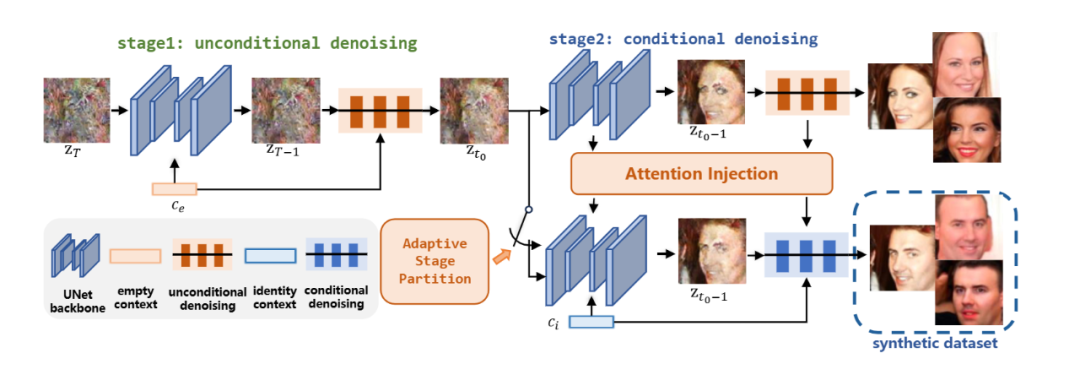
现有的人脸识别技术依赖于大规模真实人脸数据集, 存在隐私风险。通过合成虚拟人脸数据来训练识别模型是解决上述问题的一种有效方案。本文提出了一种新框架UIFace,通过利用模型内在的能力进行多样且一致的人脸图像生成。具体而言,在训练阶段,UIFace引入了空身份嵌入向量来学习数据集中的多样的身份无关属性。在生成阶段,UIFace通过一种新颖的两阶段生成策略,在去噪前期以空身份嵌入向量为条件生成让模型生成图像中身份无关的属性,从而保持合成数据集的多样性。在去噪后期,模型以身份向量为条件生成图像中身份相关的细节。进一步的,本文还探索了基于注意力图差分的自适应阶段划分策略,为每一个样本自适应的进行阶段划分,并且提出了一种注意力注入机制,通过利用来自空身份向量的注意力图来引导条件生成中的采样过程。实验结果表明,UIFace可以使用更少的训练数据和一半大小的合成数据集并取得现有最好的性能。当进一步增加虚拟人脸的数量时,UIFace可以达到与在真实数据集上训练的人脸识别模型相当的性能。
06
MMAD:多模态大模型在工业异常检测任务的全面测评基准
MMAD: A Comprehensive Benchmark for Multimodal Large Language Models in Industrial Anomaly Detection
Xi Jiang(南科大), Jian Li, Hanqiu Deng, Yong Liu, Bin-Bin Gao, Yifeng Zhou, Jialin Li, Chengjie Wang, Feng Zheng(南科大)

在工业检测领域,多模态大语言模型(MLLMs)凭借其强大的语言能力和泛化能力,具有革新实际应用范式的巨大潜力。然而,尽管这些模型在多个领域展现出卓越的问题解决能力,但其在工业异常检测方面的能力尚未得到系统研究。为填补这一空白,我们提出了MMAD——一个面向工业异常检测的全方位基准测试。我们界定了MLLMs在工业检测中的七个关键子任务,并设计了一个创新流程来生成包含8,366张工业图像、39,672个问题的MMAD数据集。基于MMAD,我们对各类前沿MLLMs进行了全面的量化评估。商用模型表现最佳,其中GPT-4o模型的平均准确率达到74.9%。然而这一结果仍远未达到工业应用需求。分析表明,当前MLLMs在回答工业异常缺陷相关问题时仍有显著提升空间。我们进一步探索了两种无需训练的增强策略来提升模型在工业场景下的表现,揭示了未来研究的潜在优化方向。
论文链接:
[Openreview]
https://openreview.net/forum?id=JDIER86r8v
[Huggingface]
https://huggingface.co/datasets/jiang-cc/MMAD
[GitHub]
https://github.com/jam-cc/MMAD
本文转自腾讯优图实验室。

END
欢迎加入「计算机视觉」交流群👇备注:CV


















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









