






近年来,跨域学习和跨模态学习在多个应用领域中取得了显著的进展。尽管不同领域和模态之间的数据分布差异和标注数据稀缺常常带来挑战,但越来越多的研究集中在如何通过自监督学习和无监督领域适应技术来解决这些问题。
自监督学习作为一种无需大量标注数据的方法,能够有效地从未标注数据中提取有用特征,并在跨域或跨模态设置中增强模型的迁移能力和泛化能力。此外,如何处理源域和目标域之间的差异,使得模型能够在 多领域或跨模态间有效迁移,成为提升模型性能的关键。
基于这些共同的研究问题,本文将介绍四篇在跨域学习、跨模态适应以及自监督表示学习方面取得创新成果的论文,分别探讨了时间序列、图像分类、视网膜血管分割等任务中的挑战和解决方案。接下来,我们将详细讨论这些论文的贡献与创新。
论文1:

创新点:
(1)提出了CrossTimeNet框架进行跨领域自监督预训练:该框架专门设计用于时间序列数据的自监督学习,能够有效处理不同领域间的数据差异,提高跨领域的知识迁移能力,进而提升时间序列模型的泛化性和预测性能。
(2)采用预训练语言模型与损坏恢复自监督目标:通过使用预训练语言模型作为主干网络,利用已有的知识捕捉时序依赖性,并通过恢复损坏输入的自监督优化目标,提升了时间序列数据的表征能力,特别是在捕捉双向上下文信息方面表现突出。
(3)设计了跨领域实例统一的离散化Tokenization机制:提出了一种新的 时间序列离散化Tokenizer,能够将连续的时间序列转化为离散的token,通过这一过程有效弥合跨领域数据的差异,从而实现不同领域间的统一表示,增强了模型的跨领域适用性和鲁棒性。
论文2:

创新点:
(1)我们提出了一种新的跨域方面迁移问题,用于方面类别检测,其中源域和目标域的特征空间、数据分布和输出空间可能都不相同。
(2)我们结合用户行为信息和评论文本信息,构建了一个异构图,旨在提升方面类别检测性能并解决冷启动问题。
(3)我们提出了一种创新的模型——可追溯的异构图表示学习(THGRL),用于解决跨域方面迁移问题。THGRL不仅能够自动嵌入图的异构性(即不同类型的信息),还能够表征全局图形模式及其拓扑信息,用于表示学习。通过使用THGRL,我们将不同领域的特征空间投影到一个共同的空间,同时保持数据分布和输出空间的差异。
(4)最后,我们通过在多个真实世界电商数据集上的实验验证了所提出的方法。为了帮助其他学者复现实验结果,我们通过GitHub发布了这些数据集。根据我们所知,这是首个与用户行为信息相关的方面类别检测数据集。
论文3:

创新点:
(1)我们提出了一种创新的 无监督领域适应(UDA) 框架,用于 OCT 和 OCTA 图像中的 RV分割。
(2)该UDA框架基于 表征风格转移解耦 和 协同一致性学习,可以有效地应用于具有大领域差异的场景。我们在 OCT 和 OCTA 图像中的RV分割任务上验证了我们的框架。
(3)进行了大量的比较实验,包括定量和定性分析,结果显示,所提出的管道在公开的 OCTA-500 数据集上相较于代表性的最先进方法(SOTA)取得了优越的性能。
论文4:
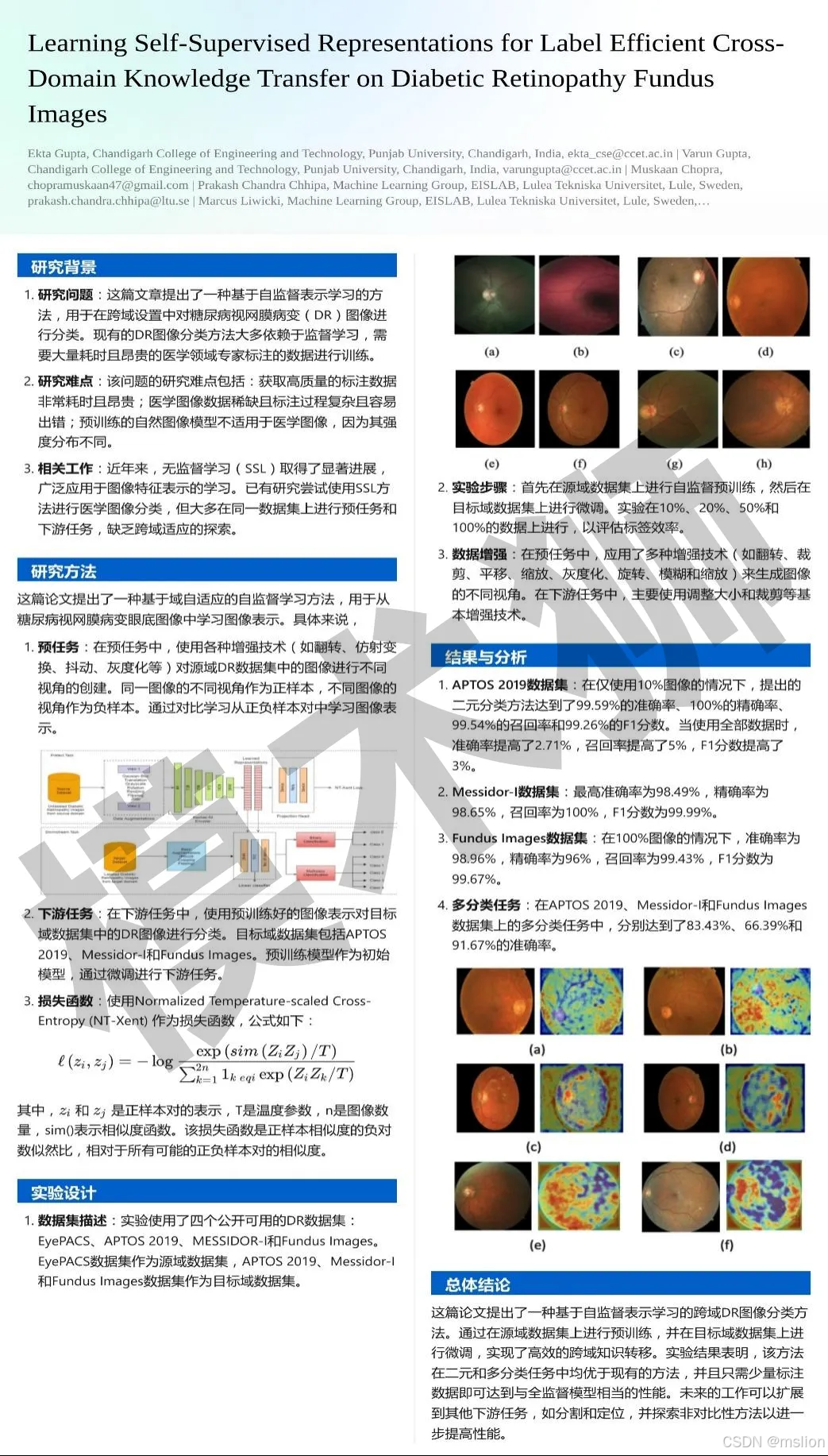
创新点:
(1)本研究提出了一种基于领域自适应的自监督学习方法,用于从糖尿病视网膜病变(DR)眼底图像中学习图像表征。
(2)该方法通过在跨领域环境中对来自未标注数据集的糖尿病视网膜病变图像表征进行自监督学习,其有效性已在图1中得到验证。
(3)结果表明,所提出的方法在糖尿病视网膜病变分类方面优于现有方法。

















 1291
1291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









