










设计一个深度学习的模型,其实就设计一个多层的学习模型,而每个层上又有不同的神经元,所有的运算逻辑都是在这些神经元上完成的,每一层的输出作为下一层的输入。
下图是一个典型的,一共有5层的学习模型,包含1个输入层,3个隐藏层,1个输出层,而在每个隐藏层中有包括2个神经元。

输入层:输入一定是所谓的图Tensor结构,可以是输入tensor的各种可能feature运算,比如说是平方,相乘,sin,cos等等,具体是什么要根据实际情况来定
隐藏层:这是执行学习运算逻辑的主要阵地,所谓的深度学习,也就是隐藏层可以是非常深的层次,层次越多所要消耗的资源也越多,但并不见得层次越多效果会越好。每一个隐藏层可以设计自己的学习逻辑,使得神经元对不同的特性感兴趣,这部分也是我们需要主要学习的地方
输出层:是模型的最后一个层次,直接把学习的结果输出为可以被理解的格式,比如说图片识别,这一层可以告诉你图片中物体可能是什么物体的概率。
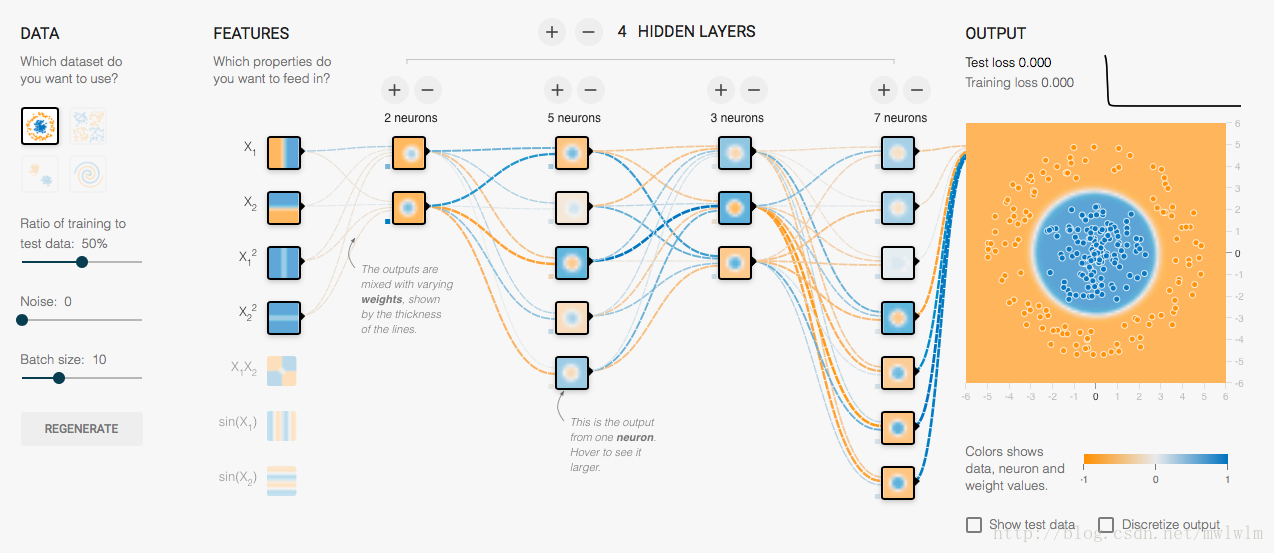
上面这张图是一个有4个隐藏层,每个层有不同数量的神经元,而输入层有四个不同feature数据输入。
读者可以到谷歌推出的神经网络游乐场去完,有助于理解层的概念
http://playground.tensorflow.org
示例代码:
import tensorflow as tf
import numpy as np
def add_layer(inputs,in_size,out_size,activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size,out_size]))
biases = tf.Variable(tf.zeros([1,out_size])+0.1)
Wx_plus_b=tf.matmul(inputs,Weights)
if(activation_function==None):
outputs=Wx_plus_b
else:
outputs=activation_function(Wx_plus_b)
return outputs
x_data= np.linspace(-1,1,300)[:,np.newaxis]
noise=np.random.normal(0,0.05,x_data.shape)
y_data=np.square(x_data)-0.5+noise
xs=tf.placeholder(tf.float32,[300,1],"xs")
ys=tf.placeholder(tf.float32,[300,1],"ys")
l1=add_layer(xs,1,10,activation_function=tf.nn.relu)
prediction= add_layer(l1,10,1,activation_function=None)
loss=tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
init=tf.initialize_all_variables()
sess=tf.Session()
sess.run(init)
for i in range(1000):
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})
if i%20 ==0:
print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))执行结果如下:
0.634071
0.133638
0.121423
0.119904
0.119701
0.119674
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967
0.11967















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











