







目标跟踪:SORT & Deep SORT
一、SORT 算法介绍
1.1、主要思想
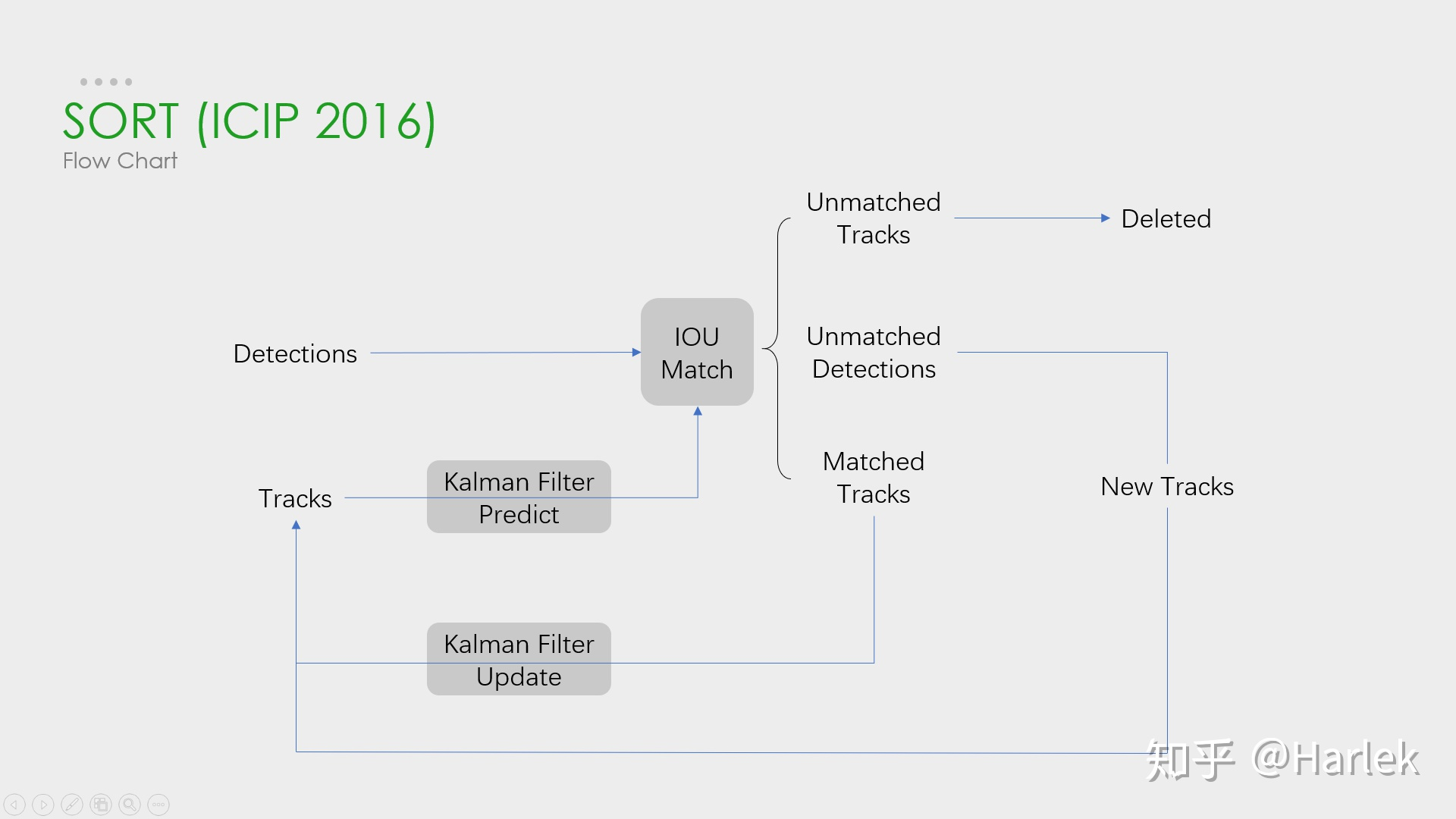
- 基于检测的结果使用基于
卡尔曼滤波与带权重的匈牙利匹配算法(KM 算法)的方法来进行跟踪,具体步骤如下图所示:- 首先,使用卡尔曼滤波(线性速度模型)对跟踪对象在当前帧的位置和速度等进行预测
- 然后,使用带权重(IoU 距离)的匈牙利算法将预测后的
tracks和当前帧中的detecions进行匹配(Note: 假设视频中两帧之间物体移动不会过多,当IoU小于一定数值0.3时,不认为是同一个目标;也就是1-IoU距离大于0.7时,不认为是同一目标) - 最后,将匹配上的跟踪框和检测框进行卡尔曼滤波更新;将未匹配上的检测框加入
tracks;将未匹配上的跟踪框删除
1.2、主要问题
SORT 算法利用卡尔曼滤波算法预测检测框在下一帧的状态,将该状态与下一帧的检测结果进行匹配,实现目标的追踪:
- 一旦物体受到遮挡或者其他原因没有被检测到,卡尔曼滤波预测的状态信息将无法和检测结果进行匹配,该追踪片段将会提前结束(
解决方案:延长 tracker 的生命周期,保留 tracker 的 feature,增加卡尔曼滤波预测的精度)- 遮挡结束后,车辆检测可能又将被继续执行,那么SORT只能分配给该物体一个新的ID编号,代表一个新的追踪片段的开始。所以SORT的缺点是:受遮挡等情况影响较大,会有大量的 ID 切换
- DeepSORT 解决方案:后面每执行一步时,都要执行一次
当前帧被检测物体外观特征与之前存储的外观特征的相似度计算,这个相似度将作为一个重要的判别依据(不是唯一的,还要结合马氏距离对其进行限制)
二、DeepSORT 算法介绍
2.1、主要思想
DeepSORT 的优化主要就是级联匹配+IoU匹配(缓解遮挡,减少漏匹配)、新轨迹确认(减少误检)和 Track 状态管理(延长生命周期),主要创新点如下:
- 增加 Unmatched Tracks 的
生命周期- 增加 Tracks 的轨迹
状态管理(不确定态、确定态、删除态),连续 3 帧都匹配上才由不确定态转为确定态的 Track,大于生命周期的时候删除掉- 增加
级联匹配,确认态 的 Tracks 使用级联匹配(reid+马氏距离作为运动信息的约束),不确定态 的 Tracks 和 Unmatched Tracks 和 Unmatched Detections 通过IoU再做二次匹配- Note:可以根据检测框的
高度 h 做一个限制,忽略过远、过小的目标

2.2、状态估计和轨迹管理
a、状态估计
- 使用 8 维的状态空间 ( x , y , r , h , x ˙ , y ˙ , r ˙ , h ˙ ) (x, y, r, h, \dot{x},\dot{y}, \dot{r}, \dot{h}) (x,y,r,h,x˙,y˙,r˙,h˙),其中 ( x , y ) (x, y) (x,y) 代表 bbox 的中心点, r r r 代表 bbox 的宽高比, h h h 代表 bbox 的高, ( x ˙ , y ˙ , r ˙ , h ˙ ) (\dot{x},\dot{y}, \dot{r}, \dot{h}) (x˙,y˙,r˙,h˙) 代表变量在图像坐标上的相对速度
- 使用具有等速运动和线性观测模型的标准卡尔曼滤波器,将以上 8 维状态作为物体状态的直接观测模型
- 具体可参考:目标跟踪:卡尔曼滤波状态估计与更新
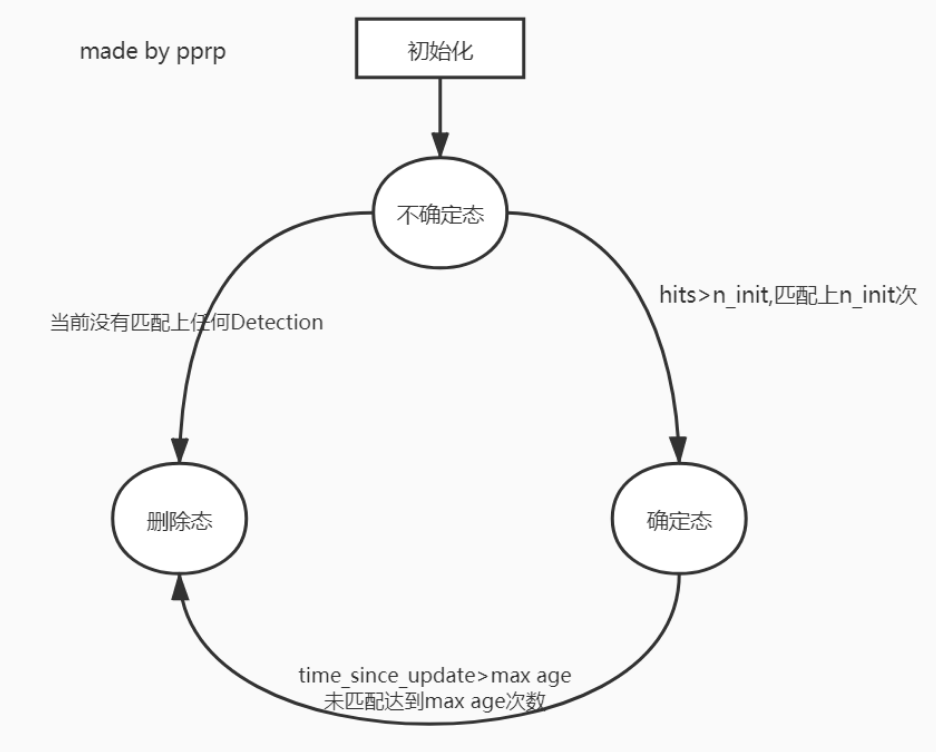
b、轨迹管理
- 不确定态: 如果当前帧的 detection 和上一帧的 tracks 没有匹配上,那么将对这个 detection 进行初始化,转变为新的 track,状态设置为不确定
- 确定态: 只有满足连续三帧都成功匹配到同一 detection,才能将不确定态的 track 转化为确定态的 track
- 删除态:
- 处于不确定态:未满足连续三帧都成功匹配到同一 detection
- 处于确定态:
time_since_update > max_age,超过最大生命周期,被认为离开图片区域,将从轨迹集合中删除 - time_since_update 在卡尔曼滤波器 predict 的时候递增,在轨迹和 detection 关联的时候重置为 0
- 关于为什么新轨迹要连续三帧命中才确认? 个人认为是为了避免误检,新轨迹的产生遵循更严格的条件
- 轨迹管理可参考: 目标跟踪:轨迹管理
2.3、数据关联匹配
- 匹配问题主要是匹配轨迹 Track 和观测结果 Detection 进行匹配,经常是使用匈牙利算法(或者
KM算法)来解决,该算法求解对象是一个代价矩阵,所以关键是求代价矩阵 cost_matrix- deepsort 中代价矩阵有二种:运动特征使用
IoU 距离来衡量,外观特征使用余弦距离 + 马氏距离约束来衡量- Detection 和 Track 进行匹配的所有可能情况:
- Matched Tracks:前后两帧都有目标,能够匹配上
- Unmatched Detections:图像中突然
出现新目标的时候,Detection 无法在之前的 Track 找到匹配的目标,为这个 detection 分配一个新的 track,初始状态为unconfirmed,连续三帧都跟踪匹配上,则转换为confirmed状态- Unmatched Tracks:追踪的目标
超出图像区域、被遮挡、检测算法漏检等暂时消失,Track 无法与当前任意一个 Detection 匹配,如果连续失配max_age次,该目标将从轨迹中删除- 具体
代价矩阵及最优关联匹配算法可参考:目标跟踪:数据关联
a、运动特征(马氏距离)

- 使用平方马氏距离来度量上一帧跟踪框在当前帧的值(经过卡尔曼滤波预测的 Tracks) 和当前帧观测值(Detections)之间的距离,由于两者使用的是高斯分布来进行表示的,很适合使用马氏距离来度量

- 第一个公式:
d
j
d_j
dj 代表第
j
j
j 个
detection, y i y_i yi 代表第 i i i 个track(在测量空间上的投影,跟踪位置均值), S − 1 S^{-1} S−1 代表 d d d 和 y y y 的协方差(在测量空间上的投影,观测值和预测值之间的协方差) - 第二个公式:是一个指示器,比较的是马氏距离和卡方分布的阈值(倒卡方分布计算出来的
95%置信区间),对于四维测量空间 t 1 = 9.4877 t^{1} = 9.4877 t1=9.4877,如果马氏距离小于该阈值,代表成功匹配(可以排除那些没有关联的目标) - 有关马氏距离的实现,定义在 Tracker 类中(
gating_distance)
b、外观特征(余弦距离)
- 使用余弦距离来度量 track 的外观特征和 detection 的外观特征(reid 模型提取 128 维向量)之间的相似性
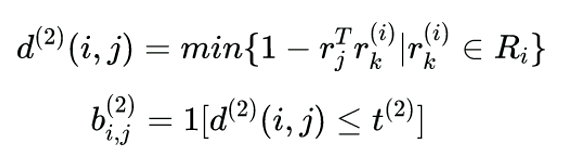
- 第一个公式:
r
j
T
r
k
(
i
)
r_{j}^{T}r_{k}^{(i)}
rjTrk(i) 计算的是 detection 和 track 特征的余弦相似度,而 余弦距离=1-余弦相似度;这里的
R
k
=
{
r
k
(
i
)
}
k
=
1
L
k
R_k = \{r_{k}^{(i)}\}_{k=1}^{L_k}
Rk={rk(i)}k=1Lk就是
gallery,作者限定了 L k L_k Lk 的大小,它最大不超过 100,即最多只能存储目标 k k k 当前时刻前 100 帧中的目标外观特征 - 作者对每一个跟踪目标构建一个gallary,存储每一个跟踪目标成功关联的最近100帧的特征向量。那么第二种度量方式就是计算第i个跟踪器的最近100个成功关联的特征集与当前帧第j个检测结果的特征向量间的
最小余弦距离。计算公式为:(注意:轨迹太长,导致外观发生变化,发生变化后,再使用最小余弦距离作为度量会出问题,所以在计算距离时,轨迹中的检测数量不能太多) - 第二个公式:是一个指示器,用来区分关联是否合理,如果余弦距离小于
t
(
2
)
t^{(2)}
t(2) 则认为匹配上,这个阈值在代码中被设置为
0.2(由参数max_dist控制),属于超参数 - 为何要保存这个列表,而不是将其更新为当前最新的特征呢? 这是为了解决目标被遮挡后再次出现的问题,需要从以往帧对应的特征进行匹配;另外,如果特征过多会严重拖慢计算速度,所以有一个参数
budget用来控制特征列表的长度,取最新的budget个features,将旧的删除掉
c、运动特征和外观特征的融合
-
motion 特征和 appearance 特征是相辅相成的,motion特征(由马氏距离计算获得)提供了物体定位的可能信息,这在
短期预测中非常有效;appearance特征(由余弦距离计算获得)可以在目标被长期遮挡后,恢复目标的ID编号,减少ID切换次数 -
为了结合两个特征,作者做了一个简单的加权运算。也就是:
c i , j = λ d ( 1 ) ( i , j ) + ( 1 − λ ) d ( 2 ) ( i , j ) c_{i,j} = \lambda d^{(1)}(i,j) + (1- \lambda) d^{(2)}(i,j) ci,j=λd(1)(i,j)+(1−λ)d(2)(i,j) -
这里的 d ( 1 ) ( i , j ) d^{(1)}(i,j) d(1)(i,j) 为马氏距离, d ( 2 ) ( i , j ) d^{(2)}(i,j) d(2)(i,j) 为余弦距离, λ \lambda λ 为权重系数,当 λ = 1 \lambda = 1 λ=1 时,退化为改进版的 SORT,当 λ = 0 \lambda = 0 λ=0 时,退化为仅依靠外观特征进行匹配
-
限制条件:
- 作者也将两个阈值(分别为马氏距离和余弦距离的阈值)综合到了一起,联合判断该某一关联是否合理可行的
-
λ
\lambda
λ 代码中默认为
0,作者认为在摄像头有实质性移动的时候这样设置比较合适,也就是在关联矩阵中只使用外观模型进行计算。但并不是说马氏距离在 Deep SORT 中毫无用处,马氏距离会对外观模型得到的代价矩阵进行限制,忽视掉明显不可行的分配(代价矩阵中过大的值)
b i , j = ∏ m = 1 2 b i , j m b_{i,j} = \prod_{m=1}^{2} b_{i,j}^{m} bi,j=m=1∏2bi,jm - 只有 b i , j = 1 b_{i,j}=1 bi,j=1 的时候才会被认为初步匹配上
-
注意:只有当两个指标都满足各自阈值条件的时候才进行融合。
-
距离度量对短期的预测和匹配效果很好,但对于长时间的遮挡的情况,使用外观特征的度量比较有效。
d、级联匹配(余弦距离+马氏距离限制)
-
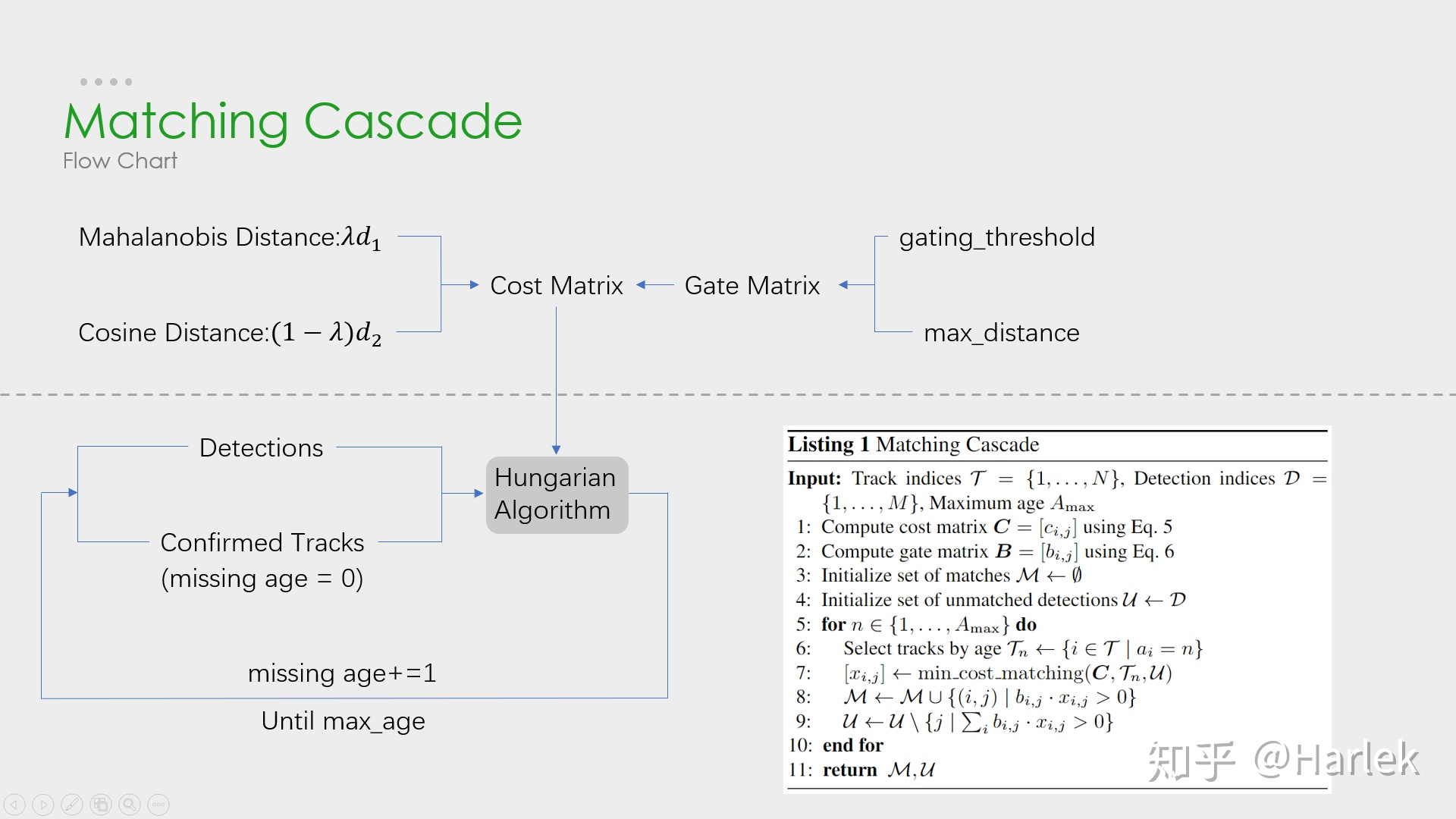
级联匹配是 Deep SORT 区别于 SORT 的一个核心算法,致力于通过
track 消失时间由小到大进行匹配+ reid 特征解决目标被长时间遮挡的情况- 当一个目标长时间被遮挡之后,kalman 滤波预测的不确定性就会大大增加(因为在被遮挡这段时间没有观测对象来调整 update,所以不确定性会增加),状态空间内的可观察性就会大大降低
- 假如此时两个跟踪器
Track竞争同一个Det检测结果的匹配权,往往遮挡时间较长的那条轨迹因为长时间未更新位置信息,追踪预测位置的不确定性更大,即协方差会更大,马氏距离计算时使用了协方差的倒数,因此马氏距离会更小,因此使得检测结果更可能和遮挡时间较长的那条轨迹相关联,这种不理想的效果往往会破坏追踪的持续性 - 为了让当前 Detection 匹配上当前时刻较近的 Track,匹配的时候 Detection
优先匹配消失时间较短的 Track(missing_age 从 1 到 100)
-
为什么叫级联匹配?主要是它的匹配过程是一个循环:
- 从
missing age = 0的轨迹(即每一帧都匹配上,没有丢失过的)到missing age = 30的轨迹(即丢失轨迹的最大时间 30 帧)挨个的和检测结果进行匹配 - 也就是说,对于没有丢失过的轨迹赋予优先匹配的权利,而丢失的最久的轨迹最后匹配
- 从
e、查缺补漏匹配(IoU 距离)
- 在匹配的最后阶段还对
unconfirmed tracks和unmatched tracks与unmatched detections进行基于 IoU 的匹配,这可以缓解因为表观突变或者部分遮挡导致的较大变化
2.4、DeepSort 可能改进的点

- 第一点,把 Re-ID 网络和检测网络融合,做一个精度和速度的 trade off,比如后面的
FairMOT - 第二点,对于轨迹段来说,时间越长的轨迹是不是更应该得到更多的信任,不仅仅只是级联匹配的优先级,由此可以引入轨迹评分的机制;引入了
轨迹评分机制,时间越久的轨迹可信度就越高,基于这个评分就可以把轨迹产生的预测框和检测框放一起做一个NMS,相当于是用预测弥补了漏检 - 第三点,从直觉上来说,检测和追踪是两个相辅相成的问题,良好的追踪可以弥补检测的漏检,良好的检测可以防止追踪的轨道飘逸,
用预测来弥补漏检这个问题在 DeepSORT 里也并没有考虑 - 第四点,DeepSORT 里给马氏距离也就是
运动模型设置的系数为 0,也就是说在相机运动的情况下线性速度模型并不 work,所以是不是可以找到更好的运动模型
三、DeepDort 整体流程和代码解析
3.1、DeepSort 算法整体流程

- 级联匹配和 IoU 匹配流程图
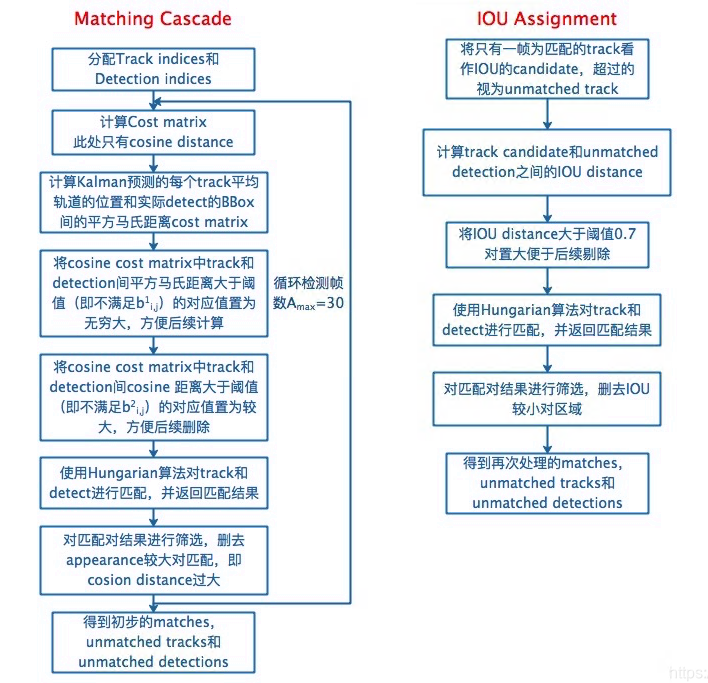
# IoU 最大距离设置:0.7,cos 最大距离设置为 0.2,cost_matrix 中大于 0.7/0.2 的全部置为 0.70001/0.20001,
# 一方面:避免 KM 匹配计算中出现无限大或不合适的值;
# 另一方面:若经过 KM 匹配后某个组合(trk_idx,det_idx)在 cost_matrix 中的值是大于 0.7(max_iou_distance)/0.2(max_cos_distance) 的,
# 这样的组合还是认为是不 match 的,要把组合中的跟踪框和检测框都踢到各自的 unmatch 列表中去
def min_cost_matching(
distance_metric, max_distance,
tracks, detections, track_indices=None, detection_indices=None):
"""Solve linear assignment problem.
Parameters
----------
distance_metric : Callable[List[Track], List[Detection], List[int], List[int]) -> ndarray
The distance metric is given a list of tracks and detections as well as
a list of N track indices and M detection indices. The metric should
return the NxM dimensional cost matrix, where element (i, j) is the
association cost between the i-th track in the given track indices and
the j-th detection in the given detection_indices.
max_distance : float
Gating threshold. Associations with cost larger than this value are
disregarded.
tracks : List[track.Track]
A list of predicted tracks at the current time step.
detections : List[detection.Detection]
A list of detections at the current time step.
track_indices : List[int]
List of track indices that maps rows in `cost_matrix` to tracks in
`tracks` (see description above).
detection_indices : List[int]
List of detection indices that maps columns in `cost_matrix` to
detections in `detections` (see description above).
Returns
-------
(List[(int, int)], List[int], List[int])
Returns a tuple with the following three entries:
* A list of matched track and detection indices.
* A list of unmatched track indices.
* A list of unmatched detection indices.
"""
if track_indices is None:
track_indices = np.arange(len(tracks))
if detection_indices is None:
detection_indices = np.arange(len(detections))
if len(detection_indices) == 0 or len(track_indices) == 0:
return [], track_indices, detection_indices # Nothing to match.
# -----------------------------------------
# Gated_distance——>gated_metric(tracks, dets, track_indices, detection_indices)
# 1. cosine distance
# 2. 马氏距离(没用它做融合,只用它对 cost_matrix 做了限制,大于 gating_threshold 9.4877 的置为 100000,在下面的 cost_matrix 中置为了 0.70001)
# 得到代价矩阵
# -----------------------------------------
# iou_cost——>iou_cost(tracks, detections, track_indices=None, detection_indices=None)
# 仅仅计算track和detection之间的iou距离
# -----------------------------------------
cost_matrix = distance_metric(tracks, detections, track_indices, detection_indices)
# -----------------------------------------
# gated_distance中设置距离中最高上限,
# 这里最远距离实际是在deep sort类中的max_dist参数设置的
# 默认max_dist=0.2, 距离越小越好
# -----------------------------------------
# iou_cost情况下,max_distance的设置对应tracker中的max_iou_distance,
# 默认值为max_iou_distance=0.7
# 注意结果是1-iou,所以越小越好
# -----------------------------------------
# 将 cost_matrix 中大于 max_distance 的元素的值替换为 max_distance + 1e-5,避免 KM 匹配计算中出现无限大或不合适的值
cost_matrix[cost_matrix > max_distance] = max_distance + 1e-5
# 匈牙利算法或者KM算法
row_indices, col_indices = linear_assignment(cost_matrix)
matches, unmatched_tracks, unmatched_detections = [], [], []
# 这几个 for 循环用于对匹配结果进行筛选,得到匹配和未匹配的结果
for col, detection_idx in enumerate(detection_indices):
if col not in col_indices:
unmatched_detections.append(detection_idx)
for row, track_idx in enumerate(track_indices):
if row not in row_indices:
unmatched_tracks.append(track_idx)
for row, col in zip(row_indices, col_indices):
track_idx = track_indices[row]
detection_idx = detection_indices[col]
# 若经过 KM 匹配后某个组合(trk_idx,det_idx)在 cost_matrix 中的值是大于 0.7(max_iou_distance)/0.2(max_cos_distance) 的,
# 这样的组合还是认为是不 match 的,要把组合中的跟踪框和检测框都踢到各自的 unmatch 列表中去
if cost_matrix[row, col] > max_distance:
unmatched_tracks.append(track_idx)
unmatched_detections.append(detection_idx)
else:
matches.append((track_idx, detection_idx))
# 得到匹配,未匹配轨迹,未匹配检测
return matches, unmatched_tracks, unmatched_detections
3.2、DeepSort 类图总结

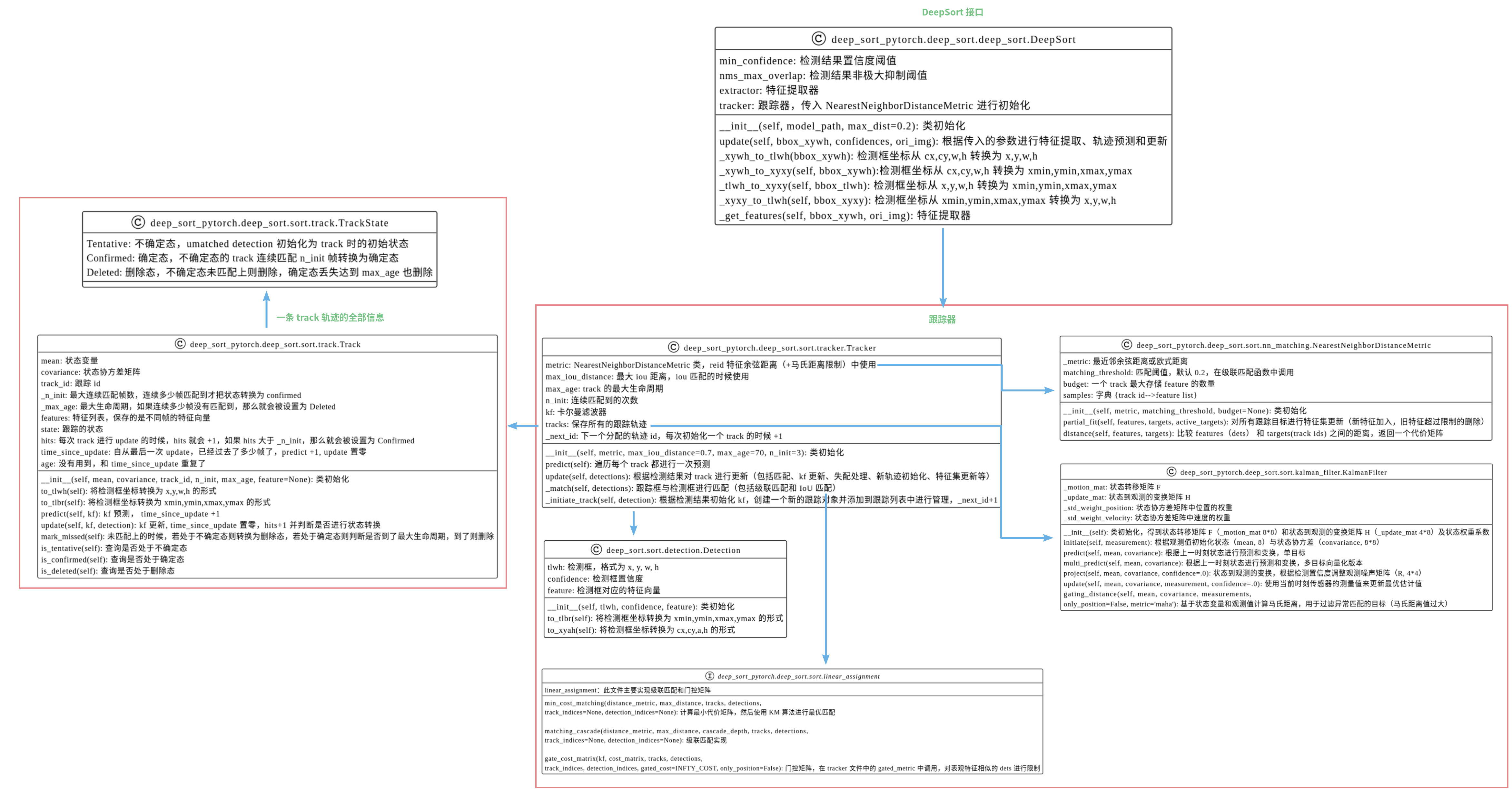
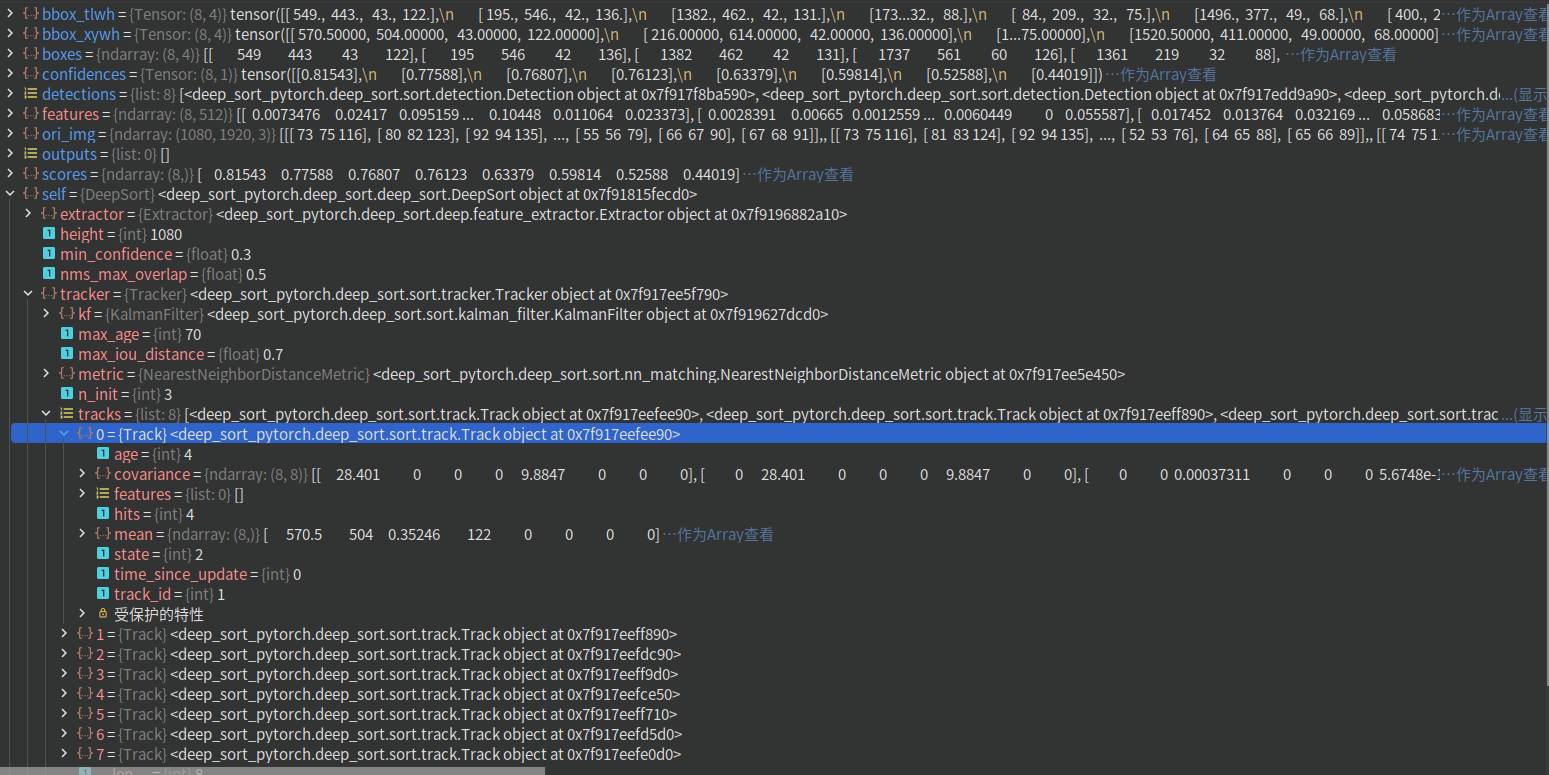
3.3、Deep sort 算法代码逐帧解读
- 先参考上面的类图把 Deep Sort 关键代码过一遍,然后再参考 bolg(非常详细): Deep sort 算法代码逐帧解读
3.4、卡尔曼滤波预测框不准,导致跟踪丢失(优化代价矩阵计算方式)
associate_detections_to_trackers(detections, trackers, iou_threshold=0.1):尝试使用 DIoU


3.5、跟踪目标命中的最小次数从零开始(min_hits=3–>0)


3.6、存在多个检测框,NMS 未过滤掉(更强大的检测器或减小 NMS 匹配阈值)

四、StrongSort
python strong_sort.py MOT17 val --BoT --ECC --NSA --EMA --MC --woC
BoT: Replacing the original feature extractor with BoT
ECC: CMC model
NSA: NSA Kalman filter
EMA: EMA feature updating mechanism
MC: Matching with both appearance and motion cost
woC: Replace the matching cascade with vanilla matching
DeepSORT
+BoT:改进的外观特征提取器
+EMA:带有惯性项的特征更新
+NSA:用于非线性运动的卡尔曼滤波器
+MC:包括运动信息的成本矩阵
+ECC:摄像机运动更正
+woC:不采用级联算法
=StrongSORT
+AF链接(离线处理):仅使用运动信息的全局链接
=StrongSORT+
+GSI内插(后处理):通过高斯过程对检测误差进行内插
=StrongSORT++
五、参考资料
1、多目标跟踪(MOT)入门(*****)
2、详解 DeepSORT 多目标追踪模型(****)
3、关于 Deep Sort 的一些理解(*****)
4、论文翻译:Deep SORT(****)
5、https://github.com/mikel-brostrom/boxmot(*****)
6、https://github.com/Sharpiless/yolov5-deepsort(****)
7、目标跟踪算法:SORT、卡尔曼滤波、匈牙利算法(*****)

















 3198
3198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









