








Disentangling User Interest and Conformity for Recommendation with Causal Embedding
http://staff.ustc.edu.cn/~hexn/papers/www21-dice.pdf
背景
本文依旧是利用因果推断相关理论进行推荐系统纠偏的一篇文章,相关详细例子可以前往deconfounded中的“举个栗子”进行查看。这里进行简述,作者分析在用户购物的过程中,用户点击某个商品,一方面可能是因为他对这个感兴趣,另一方面可能是因为该商品最近比较热门,流行。而如若不加区分的直接从原始数据中进行训练,推荐,会使得推荐系统进入一个恶性循环,因此通常会进行纠偏,而本文是从分解原因的角度进行纠正。
- 本文点击原因分解为用户兴趣(interest)和一致性(conformity),结合因果推断构建推荐系统模型。
- 使用特定于原因的数据捕获两类特征,并构建多任务学习和累积学习从不同原因的数据中进行学习。
- 所提出的DICE框架具有较好的可解释性,并且在非独立同分布的数据上具有较好的鲁棒性
此处的一致性,本人也不是特别理解,从文中判断是和item流行度相对应的特征
方法
将原因分为两类之后,可以构建新的因果图,如下图:
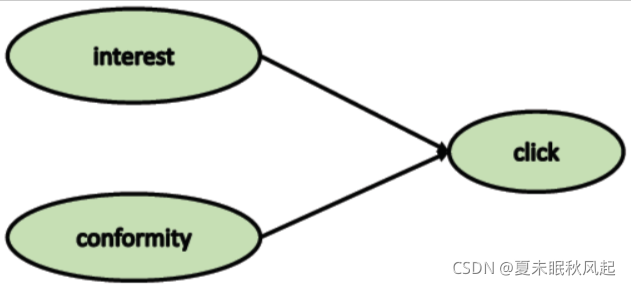
难点:
如果我们需要训练这个结果,需要得到interest单独作为原因的数据和conformity单独作为原因的数据,但是我们用于训练的数据只是单纯的整体数据,是两个耦合在一起的数据,而这难点就在于如何解耦这两个原因
从图中可以发现,该因果图为_对撞结构_,interest和conformity两个节点相互独立,当以点击为条件时,这两个节点相关。作者利用这一点,来构建了以下方案。
方案:
M I M^I MI表示user和item之间的兴趣匹配矩阵, M C M^C MC表示user和item之间的流行度一致性匹配矩阵。相当于将user-item矩阵分成了两个。
case1:负样本b(未点击)的流行度小于正样本a(点击)的流行度
这样的情况可以说明负样本的流行度小于正样本,不过无法说明用户兴趣的相关信息,可以得到以下不等式
M u a C > M u b C M_{ua}^C>M_{ub}^C MuaC>MubC
M u a I + M u a C > M u b I + M u b C M_{ua}^I+M_{ua}^C>M_{ub}^I+M_{ub}^C MuaI+MuaC>MubI+MubC
case2:负样本d的流行度大于正样本c
这样的情况说明即使正样本不是热门样本,也被点击了,说明user对这个item的兴趣很高,可以的达到以下不等式
M u d C > M u c C , M u d I < M u c I M_{ud}^C>M_{uc}^C,M_{ud}^I<M_{uc}^I MudC>MucC,MudI<MucI
M u c I + M u c C > M u d I + M u d C M_{uc}^I+M_{uc}^C>M_{ud}^I+M_{ud}^C MucI+MucC>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









