







 本文探讨了端到端Transformer模型在混合精度后量化过程中面临的挑战,包括Encoder和Decoder的自回归逻辑处理,以及如何实施有效的PTQ策略以保持量化后的精度。同时,混合精度决策关注的是实现效率,通常采用Label-free方法。参考了淘系技术部和阿里云关于移动端语音识别的解决方案和技术解读。
本文探讨了端到端Transformer模型在混合精度后量化过程中面临的挑战,包括Encoder和Decoder的自回归逻辑处理,以及如何实施有效的PTQ策略以保持量化后的精度。同时,混合精度决策关注的是实现效率,通常采用Label-free方法。参考了淘系技术部和阿里云关于移动端语音识别的解决方案和技术解读。
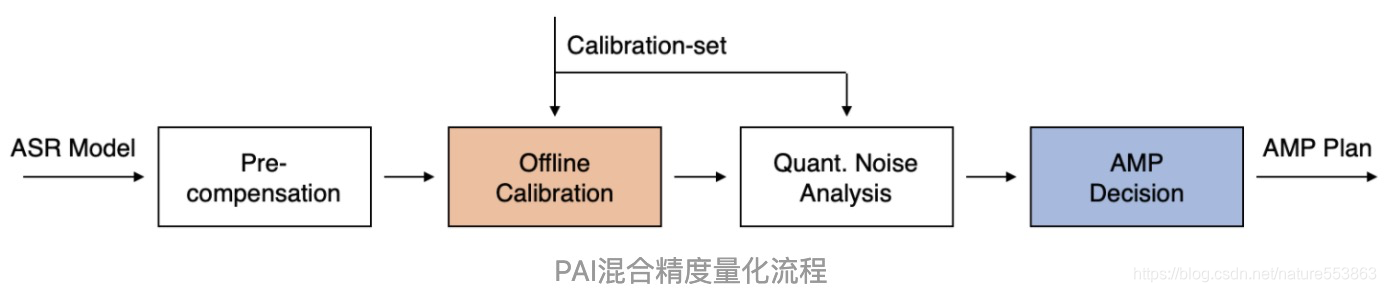
端到端Transformer模型的混合精度后量化,需要克服如下难点:
- Transformer自回归模型,包含了Encoder与Decoder;端到端模型压缩的支持,需要考虑自回归逻辑(Beam Search)的复杂实现;
- 后量化需要考虑合理、有效的PTQ策略(PTQ: Post-training Quantization),确保量化后精度鲁棒性;
- 混合精度决策需要考虑实现的高效性,通常采用Label-free方式;
具体可参考端到端语音识别的移动端解决方案(淘系技术部官方文章)、以及阿里云官方技术解读——"移动端实时语音识别技术方案及应用":
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









