







vLLM介绍
在大模型部署这个领域,其实已经形成了相对清晰的生态分工。之前我们接触过llama.cpp和Ollama,它们各自有明确的定位:
llama.cpp主要面向资源受限的环境,比如个人电脑、边缘设备等。它的优势在于对硬件要求低,能够在CPU上运行大模型,对于个人开发者和小型应用来说非常友好。
Ollama可以理解为LlamaCPP的用户友好版本,提供了更简洁的API和更便捷的模型管理,但本质上还是基于LlamaCPP的核心。
然而,这两个方案都有一个共同的局限性:在大规模并发场景下表现不佳。当面临数百个用户同时访问,或者需要在多GPU环境下发挥最大性能时,它们就显得力不从心了。
VLLM正是为了填补这个空白。它从设计之初就瞄准了多GPU、高并发的应用场景。这不是简单的性能优化,而是架构层面的重新设计。现在流行的所有量化或加速技术,vLLM几乎都由集成,比如:
- 使用 PagedAttention 实现动态kv cache(核心)
- 量化:GPTQ、AWQ、INT4、INT8 和 FP8
- 优化 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成
- 最先进的服务吞吐量
vLLM核心优化
kv cache问题
我们之前文章有讲到kv cache的技术原理
但是在kv cache方案中采用的是连续内存存储,
系统会按模型最大上下文长度分配内存,导致短序列也占用大量永远用不到的空间。这导致了空间浪费。
由于KV cache的存储效率低下,原本可以并行处理多个请求的显存,现在只能处理单个或少数几个请求。这就像停车场里每个车位都被过度预留空间,导致实际能停的车辆大大减少。
vLLM解决方案:PagedAttention
PagedAttention的核心思想是将每个序列的键值缓存划分成更小、更易于管理的“页面”或块。每个块包含固定数量标记的键值向量。这样,在注意力机制计算过程中,键值缓存的加载和访问效率更高。
PagedAttention的核心是以下两个工作,让我用"我爱大模型"这个具体例子来详细解释每个环节是如何工作的。
1. 分块:几乎零浪费的KV缓存
PagedAttention将这个缓存按固定大小划分成多个"页面"或"块"。
具体实现: 假设我们设置每个页面可以存储3个token的KV缓存,那么生成"我爱大模型"的过程中会这样分配:
- Page 0:存储"我"、“爱”、"大"三个token的Key和Value向量
- Page 1:存储"模"、"型"两个token的KV缓存,第3个位置暂时空闲
每个页面实际存储的不是字符本身,而是对应的高维向量。比如"我"这个token会产生一个512维的Key向量和一个512维的Value向量
对比kv cache,若我们的设定的允许输入1024个token,我爱大模型会一次性分配1024个空间,从而有1019个空间的浪费。PagedAttention这种方式只需要6个空间即可存储

2. 内存共享:高效利用KV缓存
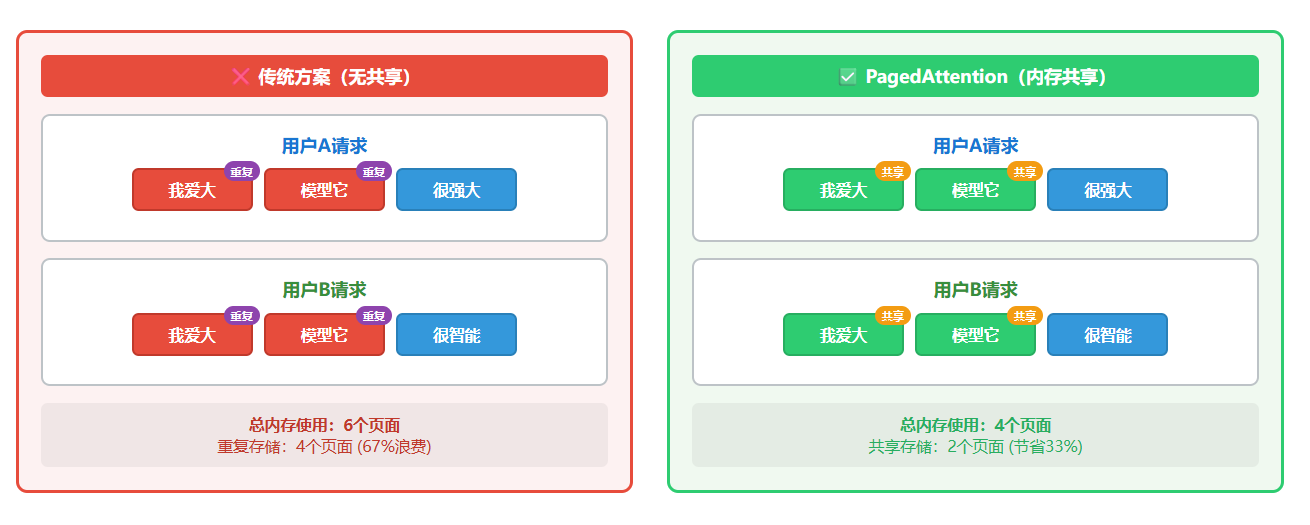
当两个用户同时发起相似的生成请求时:
- 用户A:要生成"我爱大模型,它很强大"
- 用户B:要生成"我爱大模型,它很智能"
假设没有使用前缀匹配算法,那么"我爱大模型它"这个共同前缀被存储两次,造成明显的内存浪费。
而PagedAttention通过 前缀匹配检测实现智能共享,即:
系统自动识别不同请求间的相同token序列。在我们的例子中,"我爱大模型它"这5个token在两个请求中完全相同,可以共享存储。
使用vLLM
环境配置
项目演示在autoDL
- GPU:至少RTX 3090(24GB)或A100(40GB/80GB)
- Linux
- Python 3.9 – 3.12
- CUDA 12.1
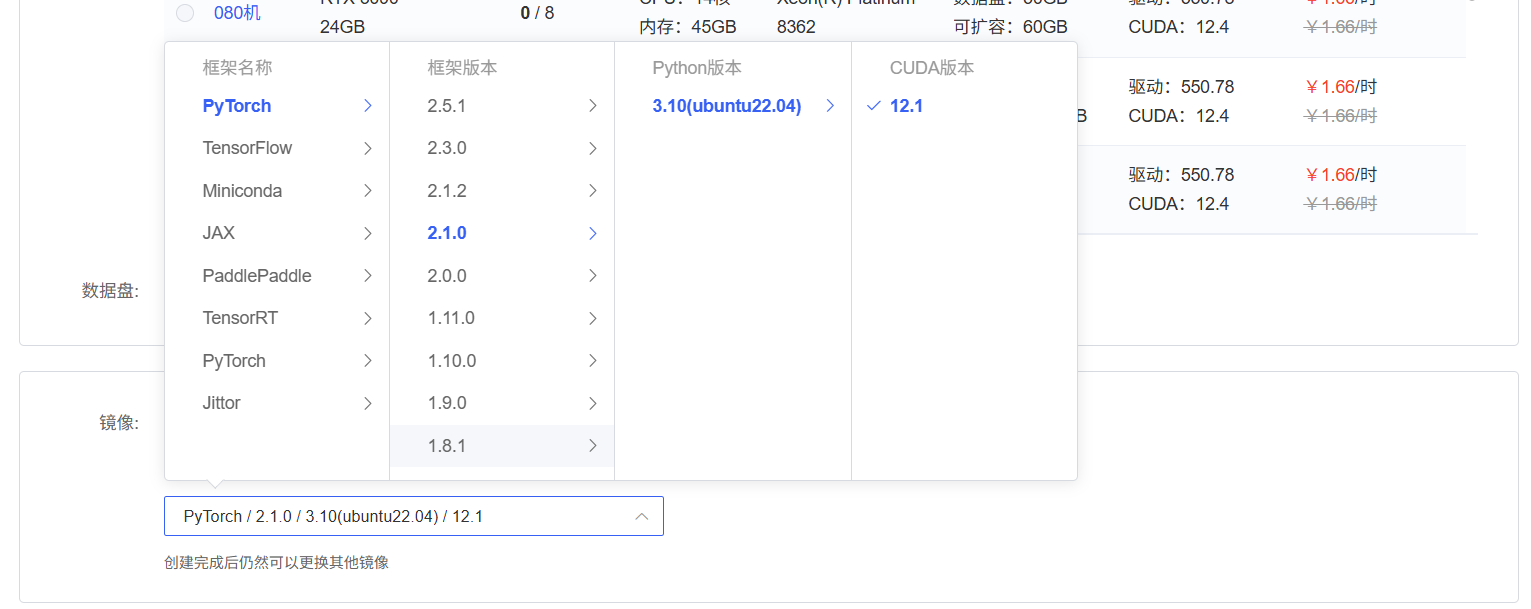
pytorch版本之类可以先随便选一个,保证CUDA版本即可
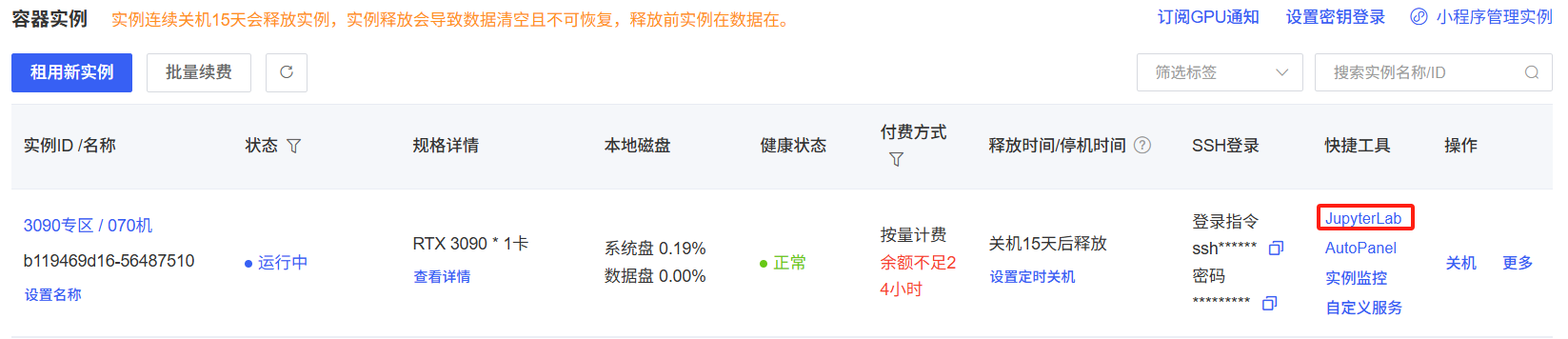
成功租用后点击JupyterLab
安装环境
打开终端,输入命令行
conda create -n myenv python=3.12 -y
conda activate myenv
pip install vllm
# 模型下载,以QWEN为例
pip install modelscope
modelscope download --model Qwen/Qwen3-8B
从下图中我们也可以得知模型保存在了/root/.cache/modelscope/hub/models/Qwen/Qwen3-8B

使用方法1:作为 Python 包使用-离线推理
只需要提供 Hugging Face 的模型名称,就可以像调用函数一样进行批量推理。这对于需要进行大量离线推理的 NLP 研究人员和企业来说特别实用。

import vllm
llm = vllm.LLM(model="meta-llama/Meta-Llama-3.1-8B")
output = llm.generate("Tell me a story")
print(output)
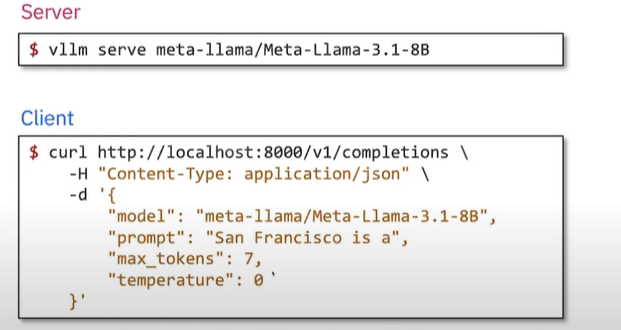
使用方法2:服务器-客户端模式
第二种是通过命令行启动兼容 OpenAI API 的服务。这样就可以无缝从 OpenAI 的 API 迁移到自己的集群上,既保障了数据隐私,又可以进行各种定制化操作。
在生产环境中更为常用,允许多个并发客户端同时向端点发送请求


















 5446
5446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











