






一 标新立异
- 提出了一种可视化技术,可直观了解“特征提取”和“映射分类”的实现过程,在一定程度上打开了CNN这个黑盒子。意义如下:
① 可以在训练期间观察特征演化并诊断模型中的潜在问题;
② 通过遮挡输入图像的局部像素对“映射分类”的输出结果进行敏感性分析,揭示不同应用场景中某些像素与分类结果的强相关性。
二 北斗之尊
- 反卷积网络(DeconvNet)
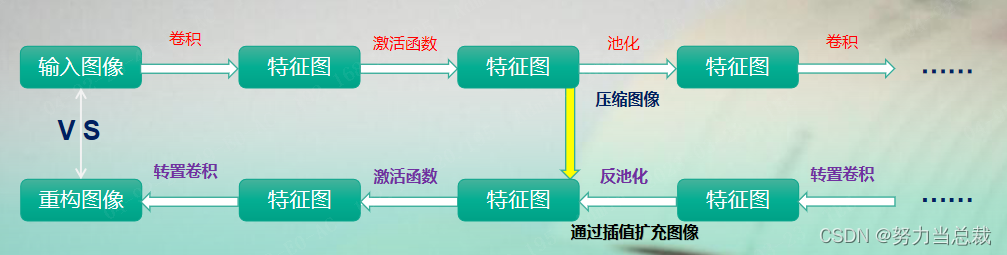
通常来说,在卷积操作中我们会将中间特征层(feature)的激活值持续传递至下一层,直到全连接层映射到样本标记空间(输出结果/类别),但是在反卷积网络中,我们将中间特征层(feature)的激活值映射到输入图像的像素空间,通过对比显示,得到输入图像中的某些像素的模式特征能够使某一个中间层的特征图被激活。
总之,DeconvNet其实就是卷积操作的反操作,即转置卷积、反激活、反池化,将特征映射到像素(卷积是将像素映射到特征形成特征图),如下图所示:
三 庖丁解牛
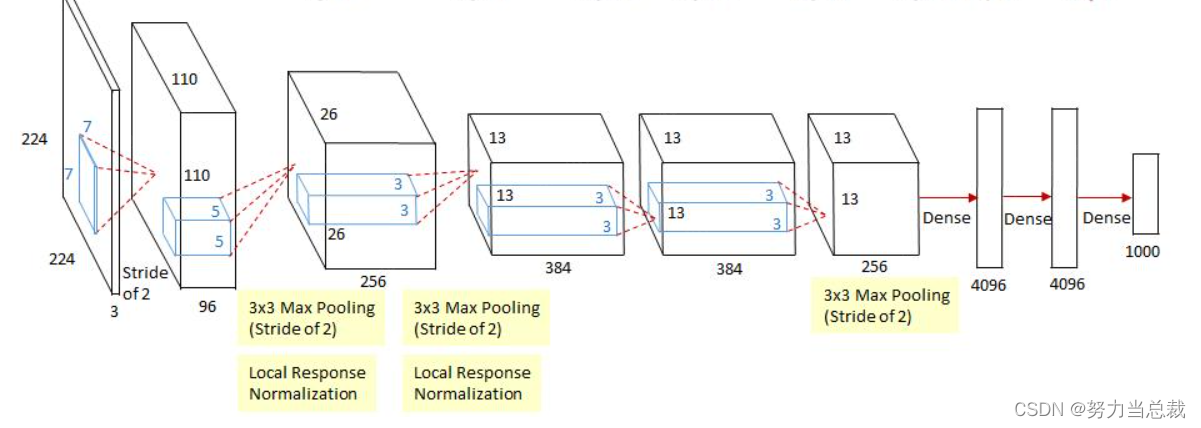
首先请明确,该网络共有8层(5个卷积层 + 3个全连接层),如下图所示:
接下来对每一层进行梳理:
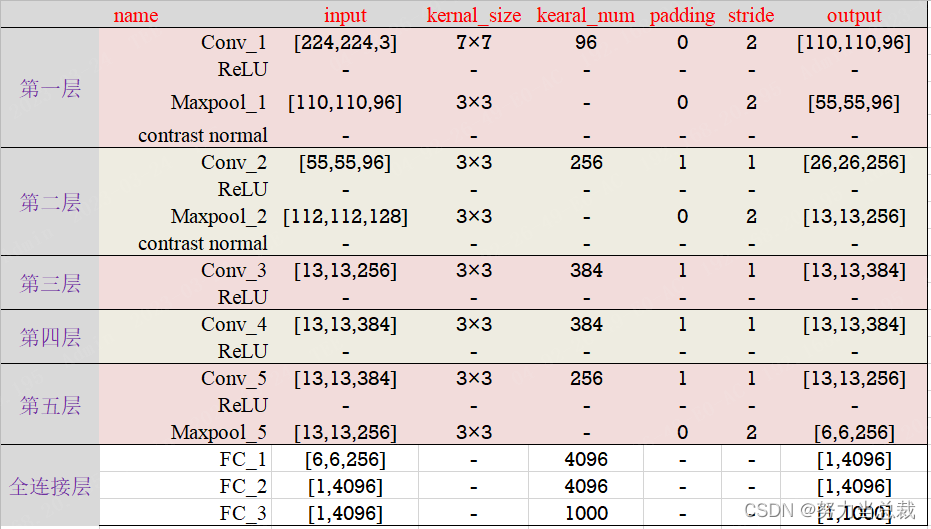
摸鱼的时间越来越短了……上表的解读不再展开,可以参考其他系列模型!
四 学以致用
1、数据集加载、模型训练和预测代码可参考其他系列模型
2、网络结构搭建代码
import torch.nn as nn
import torch
class ZFNet(nn.Module):
def __init__(self, in_channels = 3, num_classes=1000, init_weights=False):
super(ZFNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels, 96, kernel_size=7, stride=2, padding=0),
# [3, 227, 227] → [96, 111, 111]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
# [96, 111, 111] → [96, 55, 55]
nn.Conv2d(96, 256, kernel_size=5, stride=2, padding=1),
# [96, 55, 55] → [256, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# [256, 27, 27] → [256, 13, 13]
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
# [256, 13, 13] → [384, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
# [384, 13, 13] → [384, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
# [384, 13, 13] → [256, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
# [256, 13, 13] → [256, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Flatten(),
nn.Linear(256 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
五 茅塞顿开
先去上个厕所,一个小时起步……

















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











