







引言
人工智能技术正以前所未有的速度发展,多模态学习作为AI领域的一个重要分支,正在不断突破技术限制。清华大学最新开源的CogAgent模型,在多模态AI研究中展现了独特的视觉GUI Agent功能和高分辨率处理能力,代表了AI领域的一大进步。
-
Huggingface模型下载:https://huggingface.co/THUDM/cogagent-chat-hf
-
AI快站模型免费加速下载:https://aifasthub.com/models/THUDM/cogagent-chat-hf
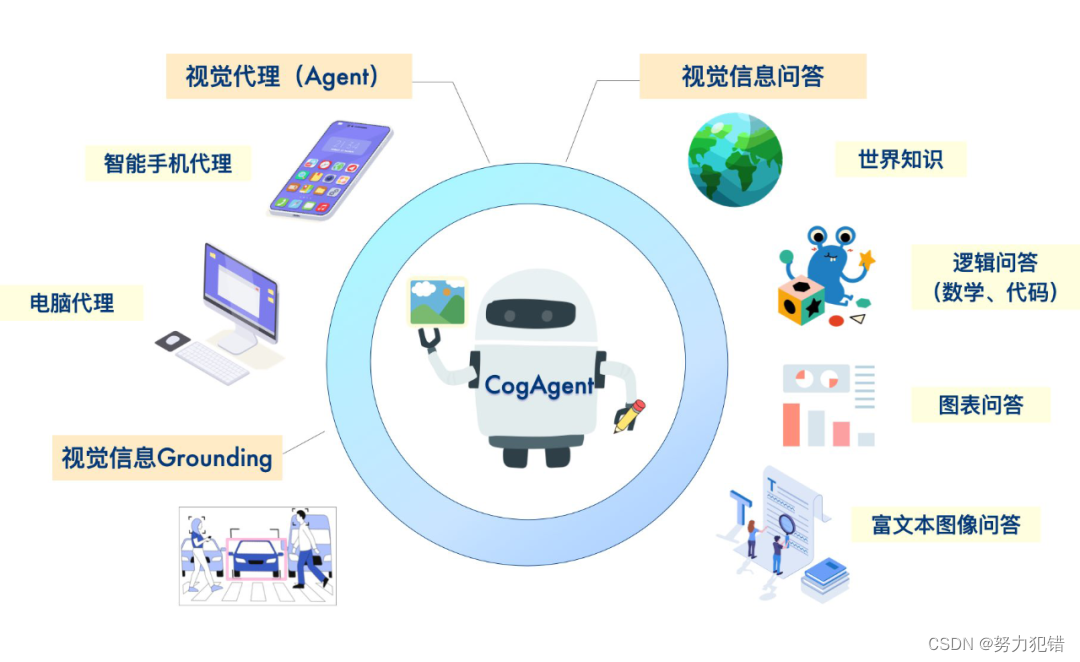
多模态AI的新突破:视觉GUI Agent
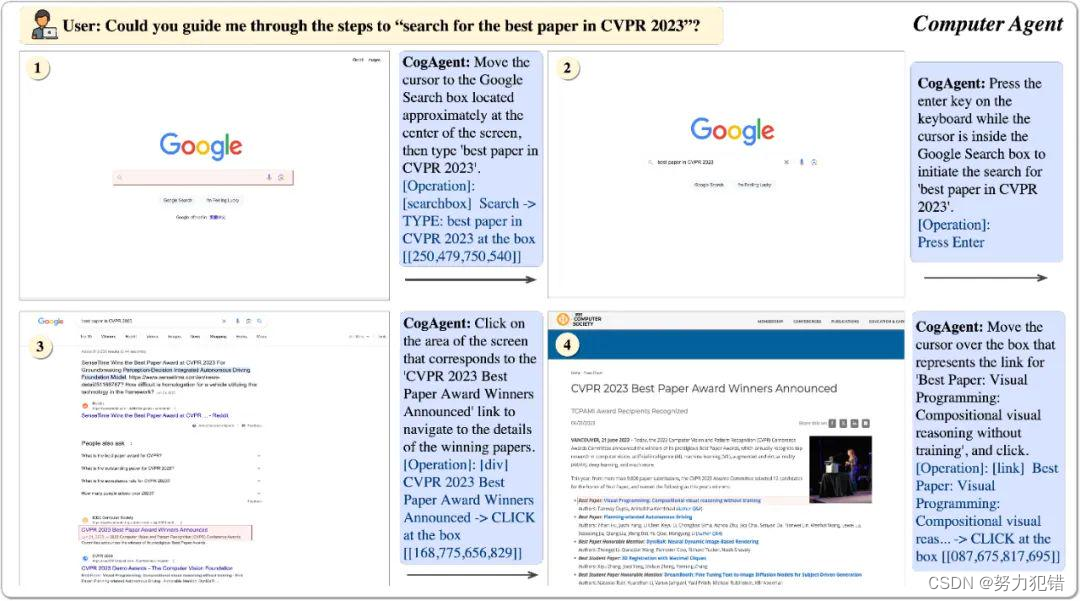
CogAgent模型的独特之处在于其视觉GUI Agent的能力,它使用视觉模态而非传统的文本模态对GUI界面进行感知。这种方法更符合人类的直觉交互方式,即通过视觉感知并做出决策。传统的基于语言的Agent,如LLM,受限于其输入形式,无法直接处理非文本信息。CogAgent的视觉GUI Agent则突破了这一限制,能够直接解析和响应GUI环境。多模态大模型CogAgent,可以实现基于视觉的GUI Agent。下图展现了其工作路径与能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









