






Google最新开源的Gemma3-27B模型凭借其128K长上下文支持、多模态能力和接近闭源模型的性能表现,已成为企业级AI部署的热门选择。vLLM 0.7.4最新版已支持Gemma3-27B大模型!结合NVIDIA L20显卡的48GB大显存和vLLM推理框架的高吞吐特性,本文将详解从环境搭建到服务调优的全流程,助你快速实现高效推理。
一、环境准备
1.1 硬件配置
| 服务器 | 数量 | CPU | 内存(TB) | 系统版本 |
| NVIDIA L20 48GB * 8 | 1 | INTEL 8458P *2 | 2 | Ubuntu 20.04 |
1.2 系统环境
| 软件名称 | 版本 | 备注 |
| NVIDIA Driver | 550.54.14 | GPU驱动 |
| CUDA | 12.4 | Cuda |
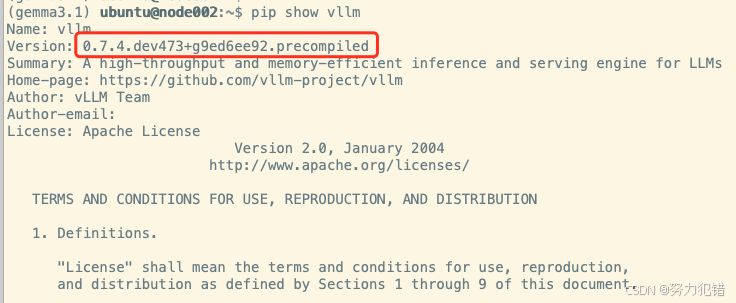
| vLLM | 0.7.4.dev473+g9ed6ee92.precompiled | LLM推理引擎 |
1.3 Gemma3-27B模型下载
- 方式一:通过HuggingFace 下载
仓库地址:https://huggingface.co/google/gemma-3-27b-it
- 方式二:通过HuggingFace镜像站-AI快站下载
仓库地址:https://aifasthub.com/google/gemma-3-27b-it
#下载AI快站下载器
wget https://fast360.xyz/images/hf-fast.sh
chmod a+x hf-fast.sh
#下载模型文件
./hf-fast.sh google/gemma-3-27b-it模型文件大小为43G。
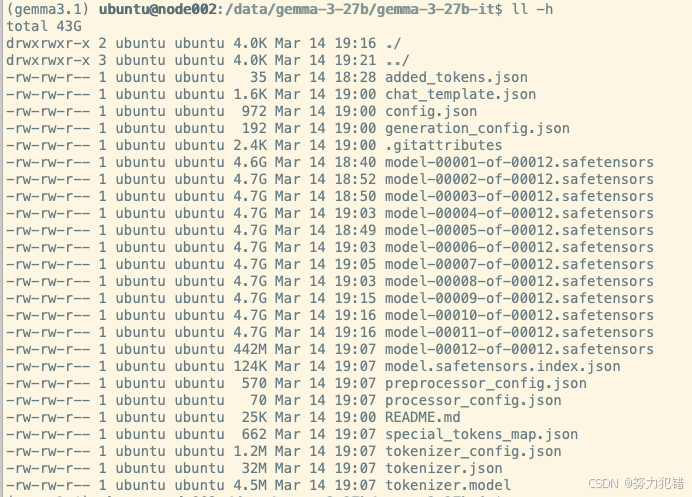
1.4 系统初始化
请参考之前文章:生产环境H200部署DeepSeek 671B 满血版全流程实战(一):系统初始化-CSDN博客
二、安装vLLM
2.1 创建虚拟环境
为避免依赖冲突,使用Conda创建独立环境:
conda create -n gemma3 python=3.12
conda activate gemma32.2 安装最新版vLLM
这里我们使用Git安装最新版vLLM,以获取最新的功能和优化。
#使用阿里云pip源来加速下载
pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple/
git clone https://github.com/vllm-project/vllm.git
cd vllm
VLLM_USE_PRECOMPILED=1 pip install --editable . -i https://mirrors.aliyun.com/pypi/simple/由于vLLM代码更新较快,编译安装最新版vLLM会因为本地 Git 分支与上游仓库不同步,如果遇到类似 "Local main branch is not up-to-date with upstream" 的错误:
Building wheels for collected packages: vllm
Building editable for vllm (pyproject.toml) ... error
error: subprocess-exited-with-error
× Building editable for vllm (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [114 lines of output]
/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/torch/_subclasses/functional_tensor.py:275: UserWarning: Failed to initialize NumPy: No module named 'numpy' (Triggered internally at /pytorch/torch/csrc/utils/tensor_numpy.cpp:81.)
cpu = _conversion_method_template(device=torch.device("cpu"))
running editable_wheel
creating /tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info
writing /tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info/PKG-INFO
writing dependency_links to /tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info/dependency_links.txt
writing entry points to /tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info/entry_points.txt
writing requirements to /tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info/requires.txt
writing top-level names to /tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info/top_level.txt
writing manifest file '/tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info/SOURCES.txt'
reading manifest template 'MANIFEST.in'
adding license file 'LICENSE'
writing manifest file '/tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm.egg-info/SOURCES.txt'
creating '/tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm-0.7.4.dev474+g3556a414.precompiled.dist-info'
creating /tmp/pip-wheel-4p1g9k_b/.tmp-rnwn8w46/vllm-0.7.4.dev474+g3556a414.precompiled.dist-info/WHEEL
running build_py
running build_ext
Traceback (most recent call last):
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 139, in run
self._create_wheel_file(bdist_wheel)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 340, in _create_wheel_file
files, mapping = self._run_build_commands(dist_name, unpacked, lib, tmp)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 263, in _run_build_commands
self._run_build_subcommands()
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 290, in _run_build_subcommands
self.run_command(name)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/cmd.py", line 357, in run_command
self.distribution.run_command(command)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/dist.py", line 999, in run_command
super().run_command(command)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 1021, in run_command
cmd_obj.run()
File "<string>", line 333, in run
File "<string>", line 319, in get_base_commit_in_main_branch
ValueError: Local main branch (3556a414341033aad1bbb84674ec16b235324b25) is not up-to-date with upstream main branch (b82662d9523d9aa1386d8d1de410426781a1fa3b). Please pull the latest changes from upstream main branch first.
/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/dist.py:1021: _DebuggingTips: Problem in editable installation.
!!
********************************************************************************
An error happened while installing `vllm` in editable mode.
The following steps are recommended to help debug this problem:
- Try to install the project normally, without using the editable mode.
Does the error still persist?
(If it does, try fixing the problem before attempting the editable mode).
- If you are using binary extensions, make sure you have all OS-level
dependencies installed (e.g. compilers, toolchains, binary libraries, ...).
- Try the latest version of setuptools (maybe the error was already fixed).
- If you (or your project dependencies) are using any setuptools extension
or customization, make sure they support the editable mode.
After following the steps above, if the problem still persists and
you think this is related to how setuptools handles editable installations,
please submit a reproducible example
(see https://stackoverflow.com/help/minimal-reproducible-example) to:
https://github.com/pypa/setuptools/issues
See https://setuptools.pypa.io/en/latest/userguide/development_mode.html for details.
********************************************************************************
!!
cmd_obj.run()
Traceback (most recent call last):
File "/home/ubuntu/miniconda3/envs/gemma3-2/lib/python3.12/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 389, in <module>
main()
File "/home/ubuntu/miniconda3/envs/gemma3-2/lib/python3.12/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 373, in main
json_out["return_val"] = hook(**hook_input["kwargs"])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/ubuntu/miniconda3/envs/gemma3-2/lib/python3.12/site-packages/pip/_vendor/pyproject_hooks/_in_process/_in_process.py", line 303, in build_editable
return hook(wheel_directory, config_settings, metadata_directory)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/build_meta.py", line 476, in build_editable
return self._build_with_temp_dir(
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/build_meta.py", line 407, in _build_with_temp_dir
self.run_setup()
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/build_meta.py", line 320, in run_setup
exec(code, locals())
File "<string>", line 682, in <module>
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/__init__.py", line 117, in setup
return distutils.core.setup(**attrs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/core.py", line 186, in setup
return run_commands(dist)
^^^^^^^^^^^^^^^^^^
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/core.py", line 202, in run_commands
dist.run_commands()
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 1002, in run_commands
self.run_command(cmd)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/dist.py", line 999, in run_command
super().run_command(command)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 1021, in run_command
cmd_obj.run()
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 139, in run
self._create_wheel_file(bdist_wheel)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 340, in _create_wheel_file
files, mapping = self._run_build_commands(dist_name, unpacked, lib, tmp)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 263, in _run_build_commands
self._run_build_subcommands()
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/command/editable_wheel.py", line 290, in _run_build_subcommands
self.run_command(name)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/cmd.py", line 357, in run_command
self.distribution.run_command(command)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/dist.py", line 999, in run_command
super().run_command(command)
File "/tmp/pip-build-env-tl3kug_g/overlay/lib/python3.12/site-packages/setuptools/_distutils/dist.py", line 1021, in run_command
cmd_obj.run()
File "<string>", line 333, in run
File "<string>", line 319, in get_base_commit_in_main_branch
ValueError: Local main branch (3556a414341033aad1bbb84674ec16b235324b25) is not up-to-date with upstream main branch (b82662d9523d9aa1386d8d1de410426781a1fa3b). Please pull the latest changes from upstream main branch first.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building editable for vllm
Failed to build vllm
ERROR: Failed to build installable wheels for some pyproject.toml based projects (vllm)解决办法:进入 vllm 源码目录,强制同步上游分支,确保本地代码与官方仓库完全同步
git fetch origin main
git reset --hard origin/main
git pull --rebase
#重新执行编译安装
VLLM_USE_PRECOMPILED=1 pip install --editable . -i https://mirrors.aliyun.com/pypi/simple/验证安装是否成功:
2.3 安装transformers
pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3三、运行vLLM服务
完成vLLM的安装后,我们就可以启动vLLM服务,加载Gemma3-27B模型,开始进行推理。
1. 激活 vllm 环境,确保在 vllm 的 conda 环境中
conda activate gemma32. 启动 vLLM 服务: 使用 vllm serve 命令启动 vLLM 服务,并加载 Gemma3-27B 模型。
conda activate gemma3
#使用2块L20加载模型
export CUDA_VISIBLE_DEVICES=0,1
vllm serve /data/gemma-3-27b/gemma-3-27b-it --tensor-parallel-size 2 --max-model-len 16384 --port 8102 --trust-remote-code --served-model-name gemma3-27b --enable-chunked-prefill --max-num-batched-tokens 2048 --gpu-memory-utilization 0.95参数说明:
- /path/to/gemma-3-27b-it:Gemma3-27B模型的路径,替换为你实际的路径。
- --tensor-parallel-size 2:使用2块GPU进行模型并行推理,根据实际情况修改。
- --max-model-len 16384:模型支持的最大输入长度。
- --port 8102:服务端口号。
- --trust-remote-code:信任远程代码。
- --served-model-name gemma3-27b:服务名称。
- --enable-chunked-prefill:开启chunked prefill,可以提高推理速度。
- --max-num-batched-tokens 2048:最大batch token数量。
- --gpu-memory-utilization 0.95:GPU显存利用率。
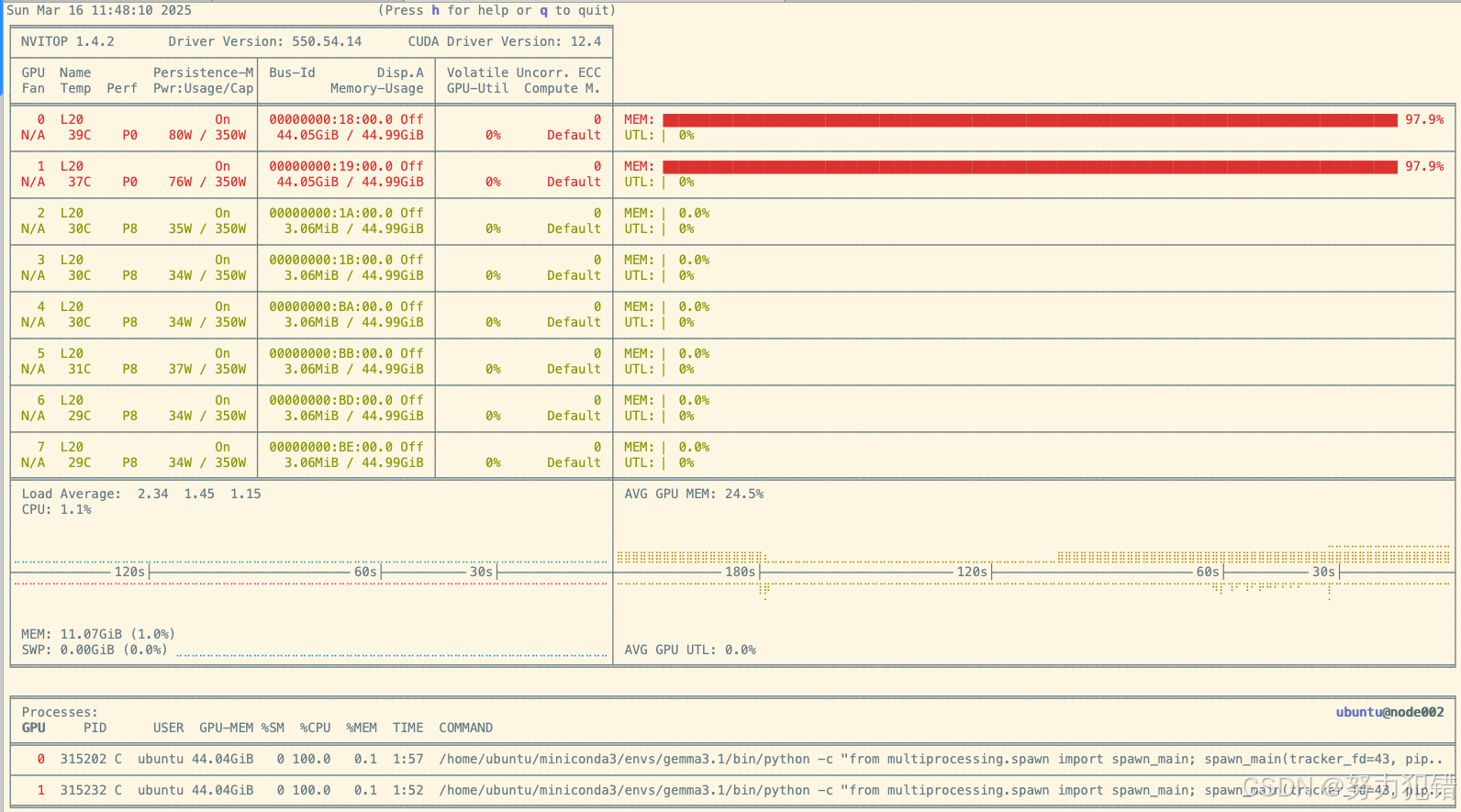
3. Nvitop监控
可以使用Nvitop监控GPU的使用情况。
四、验证服务可用性
启动vLLM服务后,我们可以发送API请求,测试服务是否正常运行。
curl -X POST "http://localhost:8102/v1/chat/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "gemma3-27b",
"messages": [{"role": "user", "content": "写个100字的散文"}]
}'预期结果:返回模型生成的文本内容,表示服务部署成功。
五、总结
本文详细介绍了如何在L20服务器上使用最新版vLLM部署Gemma3-27B模型。通过本文相信你已经成功搭建起了Gemma的推理引擎,可以尽情探索大模型的奥秘。Gemma3-27B模型凭借其强大的语言理解和生成能力,将在各种实际应用场景中发挥重要作用。

















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









