






DQN基本概念(第六章)
DQN的诞生是为了使得状态空间连续,存在无穷个状态,并降低存储空间的要求。
两大创新点:经验回放、固定q目标
首先,为了在连续的状态空间计算价值函数,使用一个近似进行替代
Q
θ
(
s
,
a
)
≈
Q
π
(
s
,
a
)
Q_{\theta} (s,a)≈ Q^{\pi} (s,a)
Qθ(s,a)≈Qπ(s,a)
深度Q网络(Deep Q-Network,DQN)算法的核心是维护 Q 函数并使用其进行决策。
Q
π
(
s
,
a
)
Q^{\pi}(s,a)
Qπ(s,a)为在该策略
π
\pi
π 下的动作价值函数,每次到达一个状态
s
t
s_t
st 之后,遍历整个动作空间,使用让
Q
π
(
s
,
a
)
Q^{\pi}(s,a)
Qπ(s,a)最大的动作作为策略:
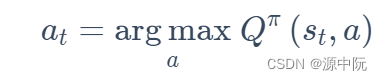
DQN采用bellman方程迭代更新,更新为:
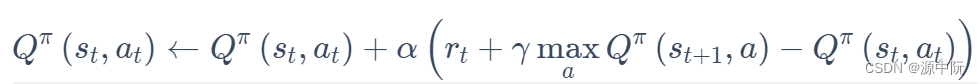
State Value Function
Policy Evaluation(策略评估)
在 value-based 的方法里面,我们学习的不是策略,我们要学习的是一个 critic(评论家)。
评论家的输出值取决于状态和演员
State Value Function Estimation
主要包含Monte-Carlo(MC)与Temporal-difference(TD),TD的方法主要基于下式:
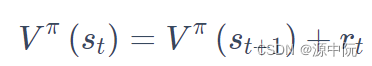
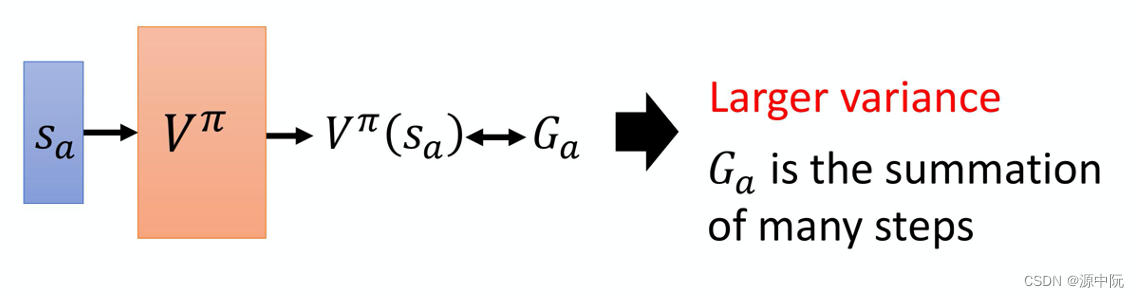
MC 最大的问题就是方差很大。常用TD方法
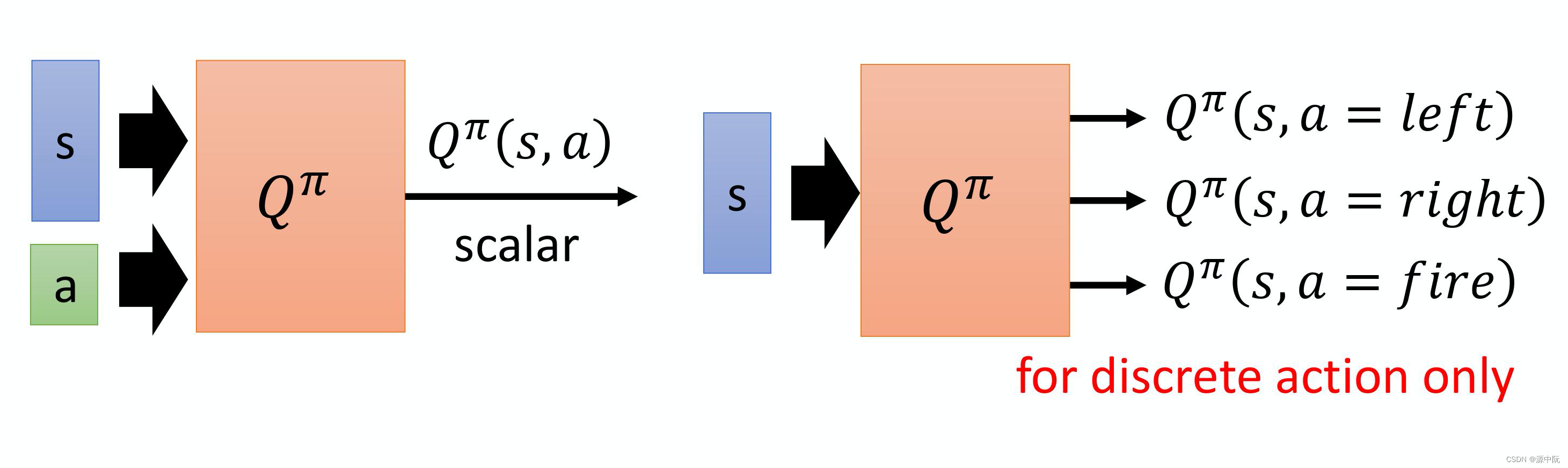
State-action Value Function(Q-function)
1.状态价值函数的输入是一个状态,根据状态去计算出累计奖励,输出是好几个值
2.状态-动作价值函数的输入是一个状态、动作对,输出是一个标量,指累积奖励的期望值。
为什么 Q π ( s , a ) Q^{\pi}(s,a) Qπ(s,a)决定出来的 π ′ {\pi}^{'} π′一定会比 π \pi π好
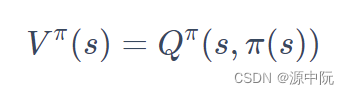
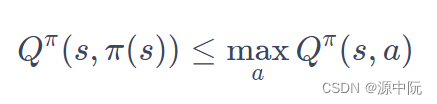
V
π
(
s
)
≤
Q
π
(
s
,
π
′
(
s
)
)
=
E
[
r
t
+
V
π
(
s
t
+
1
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
t
)
]
≤
E
[
r
t
+
Q
π
(
s
t
+
1
,
π
′
(
s
t
+
1
)
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
t
)
]
=
E
[
r
t
+
r
t
+
1
+
V
π
(
s
t
+
2
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
t
)
]
≤
E
[
r
t
+
r
t
+
1
+
Q
π
(
s
t
+
2
,
π
′
(
s
t
+
2
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
t
)
]
=
E
[
r
t
+
r
t
+
1
+
r
t
+
2
+
V
π
(
s
t
+
3
)
∣
s
t
=
s
,
a
t
=
π
′
(
s
t
)
]
≤
⋯
≤
E
[
r
t
+
r
t
+
1
+
r
t
+
2
+
⋯
∣
s
t
=
s
,
a
t
=
π
′
(
s
t
)
]
=
V
π
′
(
s
)
\begin{aligned} V^{\pi}(s) & \leq Q^{\pi}\left(s, \pi^{\prime}(s)\right) \\ &=E\left[r_{t}+V^{\pi}\left(s_{t+1}\right) \mid s_{t}=s, a_{t}=\pi^{\prime}\left(s_{t}\right)\right] \\ & \leq E\left[r_{t}+Q^{\pi}\left(s_{t+1}, \pi^{\prime}\left(s_{t+1}\right)\right) \mid s_{t}=s, a_{t}=\pi^{\prime}\left(s_{t}\right)\right] \\ &=E\left[r_{t}+r_{t+1}+V^{\pi}\left(s_{t+2}\right) \mid s_{t}=s, a_{t}=\pi^{\prime}\left(s_{t}\right)\right] \\ & \leq E\left[r_{t}+r_{t+1}+Q^{\pi}\left(s_{t+2}, \pi^{\prime}\left(s_{t+2}\right) \mid s_{t}=s, a_{t}=\pi^{\prime}\left(s_{t}\right)\right]\right.\\ &=E\left[r_{t}+r_{t+1}+r_{t+2}+V^{\pi}\left(s_{t+3}\right) \mid s_{t}=s, a_{t}=\pi^{\prime}\left(s_{t}\right)\right] \\ & \leq \cdots \\ & \leq E\left[r_{t}+r_{t+1}+r_{t+2}+\cdots \mid s_{t}=s, a_{t}=\pi^{\prime}\left(s_{t}\right)\right] \\ &=V^{\pi^{\prime}}(s) \end{aligned}
Vπ(s)≤Qπ(s,π′(s))=E[rt+Vπ(st+1)∣st=s,at=π′(st)]≤E[rt+Qπ(st+1,π′(st+1))∣st=s,at=π′(st)]=E[rt+rt+1+Vπ(st+2)∣st=s,at=π′(st)]≤E[rt+rt+1+Qπ(st+2,π′(st+2)∣st=s,at=π′(st)]=E[rt+rt+1+rt+2+Vπ(st+3)∣st=s,at=π′(st)]≤⋯≤E[rt+rt+1+rt+2+⋯∣st=s,at=π′(st)]=Vπ′(s)
因此
V
π
(
s
)
≤
V
π
′
(
s
)
V^{\pi}(s) \leq V^{\pi^{\prime}}(s)
Vπ(s)≤Vπ′(s)
从这边可知,估计某一个策略的Q-fuction,就可以找到另外一个策略
π
\pi
π比原来的策略还要更好。
Fixed Target Network固定目标网络
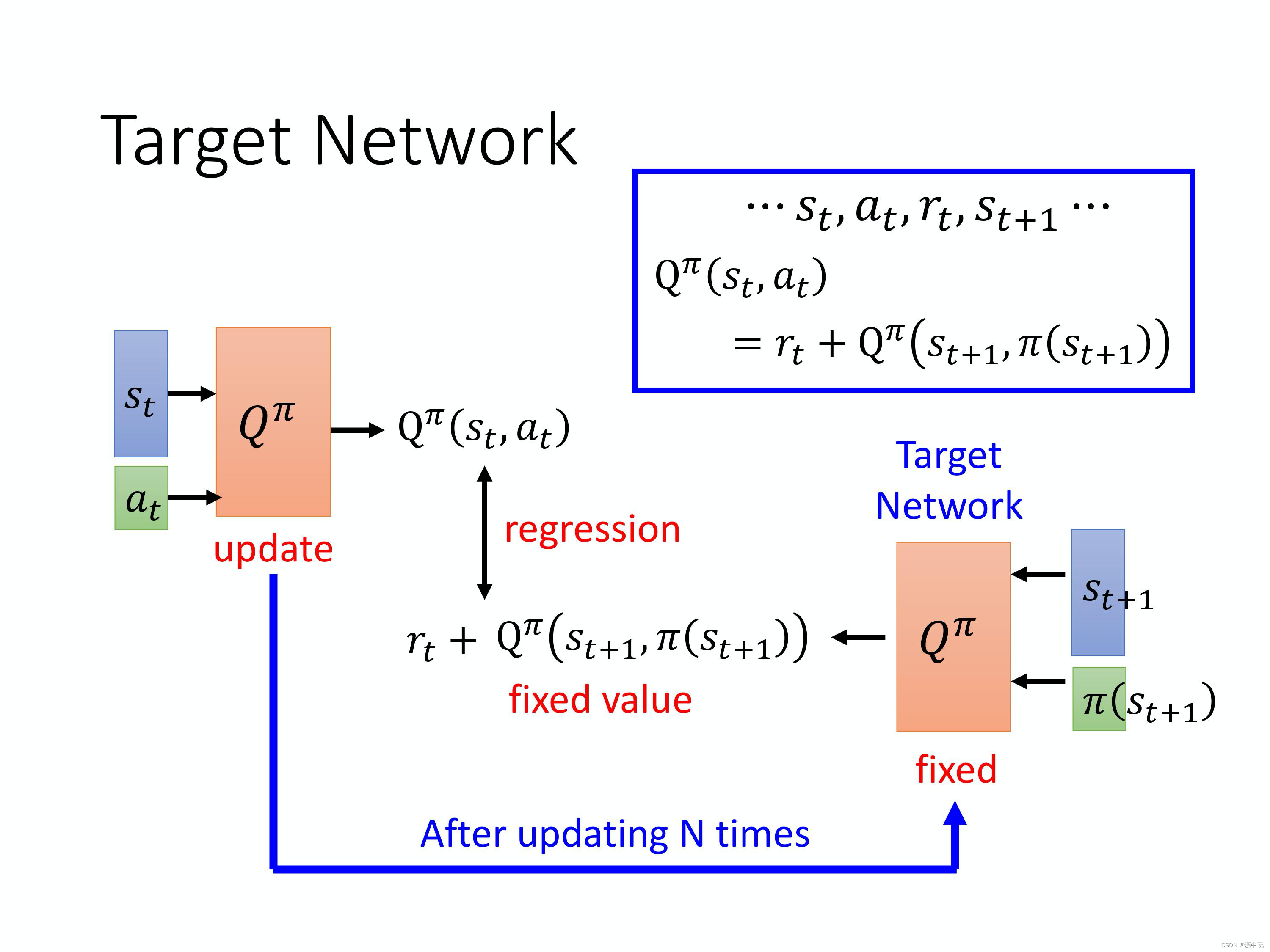
输入状态与动作
s
t
,
a
t
s_t,a_t
st,at,得到奖励后,跳到状态
s
t
+
1
s_{t+1}
st+1,即可得到式:
Q
π
(
s
t
,
a
t
)
=
r
t
+
Q
π
(
s
t
+
1
,
π
(
s
t
+
1
)
)
\mathrm{Q}^{\pi}\left(s_{t}, a_{t}\right)=r_{t}+\mathrm{Q}^{\pi}\left(s_{t+1}, \pi\left(s_{t+1}\right)\right)
Qπ(st,at)=rt+Qπ(st+1,π(st+1))
问题在于,假设这是回归问题,回归的目标一直在变,将导致网络难以稳定。
所以常用的方法是,把图中右边的目标网络固定住,只更新左边q网络的参数,在左边的q网络更新好几次后,再去用更新过的q网络替换这个目标网络。
Exploration
Epsilon Greedy:1−ε 的概率会按照 Q-function 来决定动作
Boltzmann Exploration:一个期望的动作空间上面的一个的概率分布,再根据概率分布去做采样
Experience Replay(经验回放):
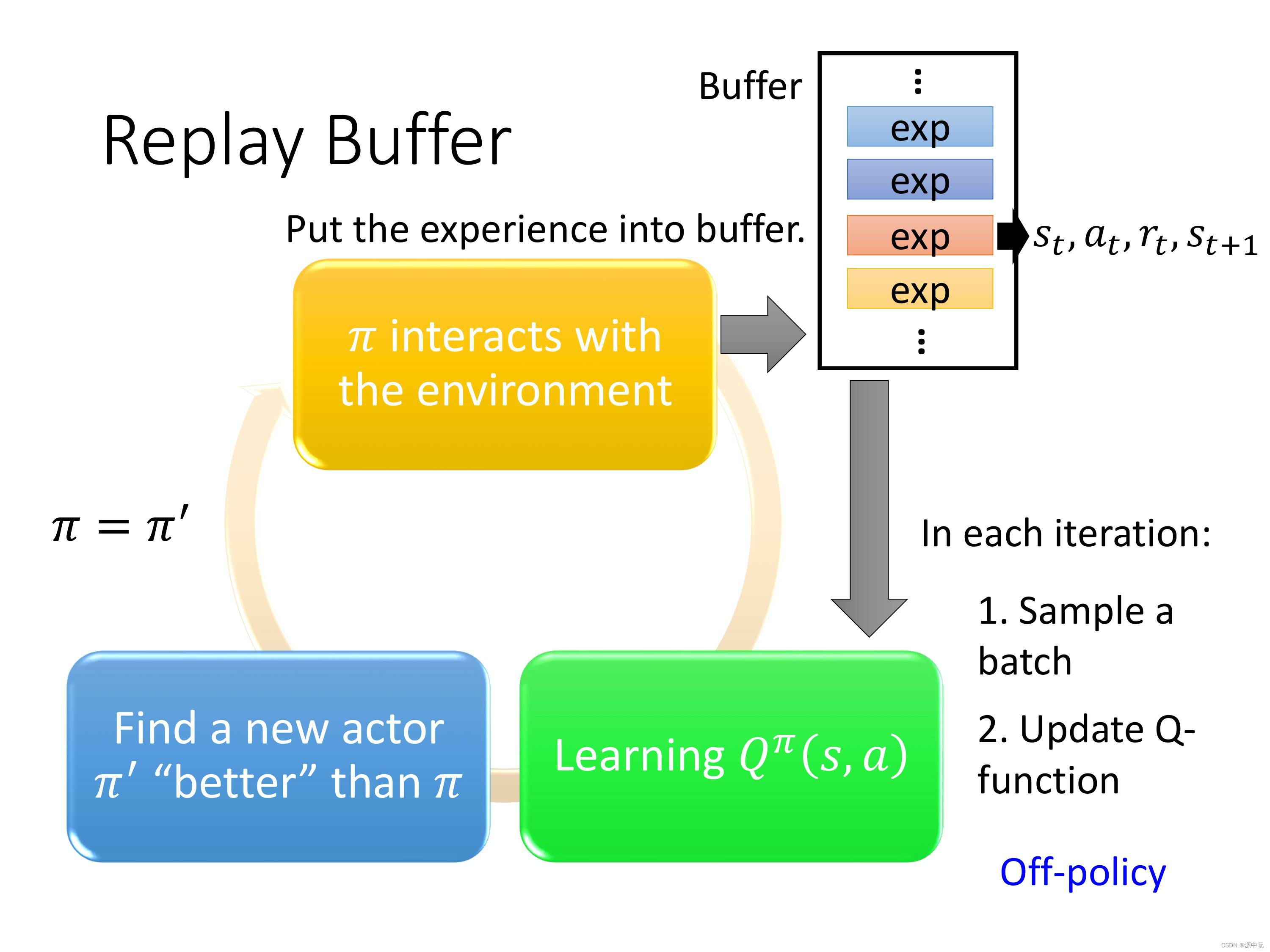
DQN
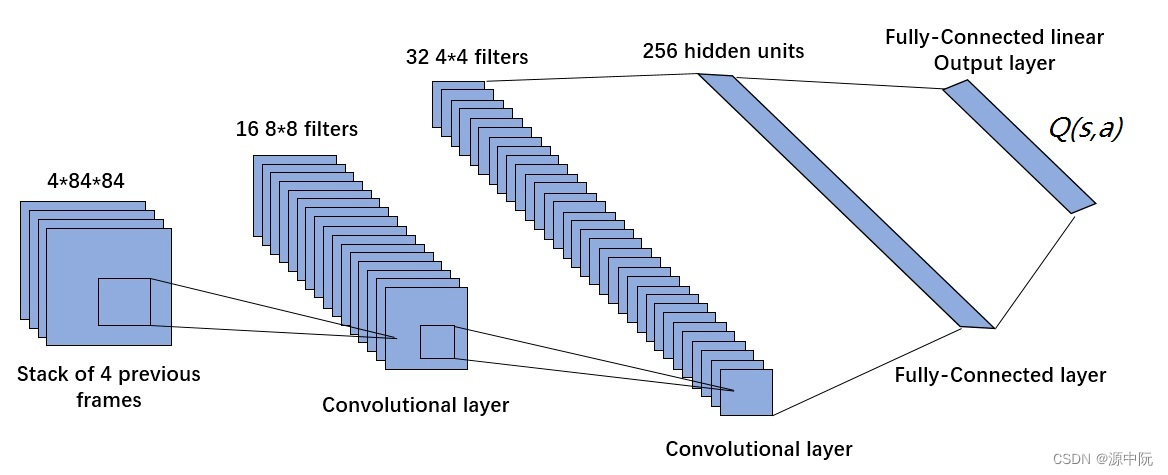
DQN 使用深度卷积神经网络近似拟合状态动作值函数
Q
(
s
,
a
)
Q(s,a)
Q(s,a),其网络结构如上图所示。DQN 模型的输入是距离当前时刻最近的 4 帧图像,该输入经过 3 个卷积层和 2 个全连接层的非线性变化后,最终在输出层输出每个动作对应的 Q 值。
DQN 和 Q-learning 有什么不同
DQN 将 Q-learning 与深度学习结合,用深度网络来近似动作价值函数,而 Q-learning 则是采用表格存储;
DQN 采用了经验回放的训练方法,从历史数据中随机采样,而 Q-learning 直接采用下一个状态的数据进行学习。
Tips of Q-learning(第七章)
Double DQN
1.Q值被高估的原因:
总是会选择reward被高估的动作当作这个max的结果去加上
r
t
r_t
rt,使得q值被高估
DDQN提出解决方法:选动作的 Q-function 跟算值的 Q-function 不是同一个:
(1)假设第一个
Q
−
f
u
n
c
t
i
o
n
Q-function
Q−function 高估了它现在选出来的动作 a,只要第二个
Q
′
−
f
u
n
c
t
i
o
n
Q^{'}-function
Q′−function没有高估这个动作 a 的值,那你算出来的就还是正常的值。
(2)假设
Q
′
Q^{'}
Q′高估了某一个动作的值,只要前面这个 Q 不要选那个动作出来就没事了,这个就是 Double DQN 神奇的地方。
Dueling DQN
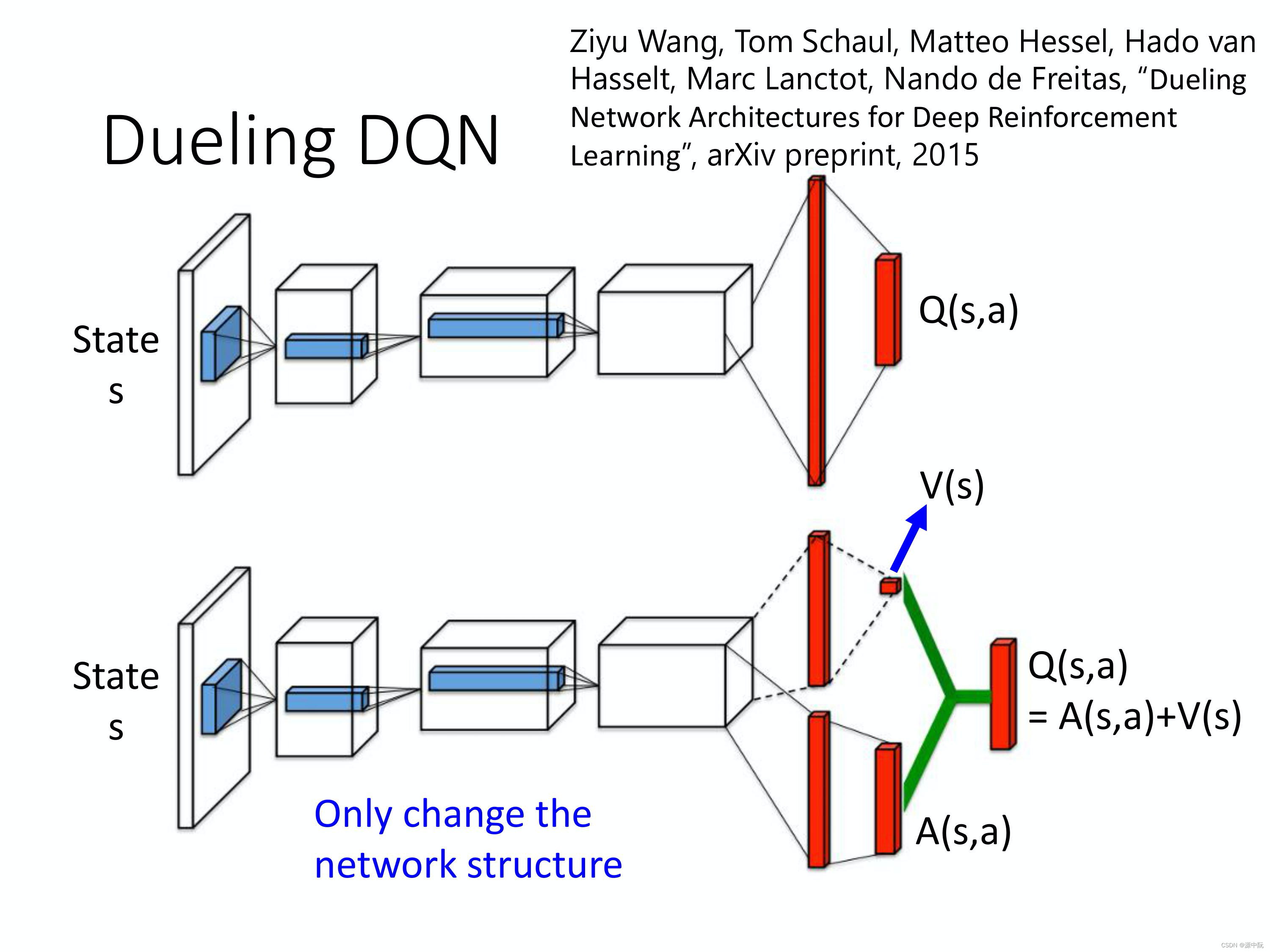
第一条路径会输出一个 scalar,这个 scalar 叫做
V
(
s
)
V(s)
V(s)。因为它跟输入 s 是有关系,所以叫做
V
(
s
)
V(s)
V(s),
V
(
s
)
V(s)
V(s)是一个 scalar。
第二条路径会输出一个 vector,这个 vector 叫做
A
(
s
,
a
)
A(s,a)
A(s,a)。下面这个 vector,它是每一个动作都有一个值。
这样的好处主要是可以使直接改变V的值,估计Q值的过程更加高效。
Prioritized Experience Replay
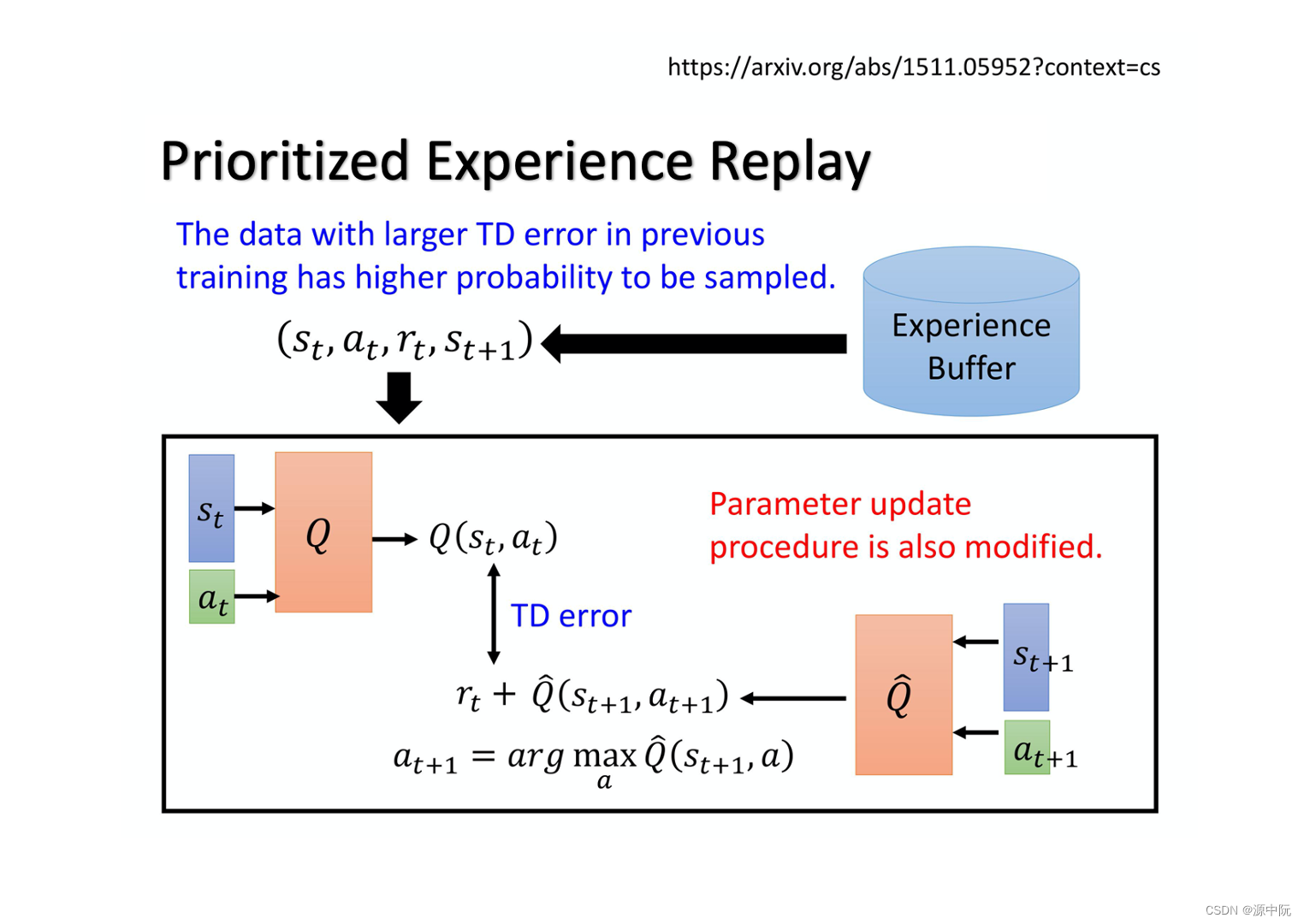
有一些重要数据,提高priority
Balance between MC and TD

Noisy Net
在参数的空间上面加噪声。
Distributional Q-function
对分布(distribution)建模,
Rainbow
把刚才所有的方法都综合起来就变成 rainbow
针对连续动作的 DQN
Actor-Critic
演员-评论家算法(Actor-Critic Algorithm)是一种结合策略梯度和时序差分学习的强化学习方法,其中:
演员(Actor)是指策略函数
π
θ
(
a
∣
s
)
\pi_{\theta}(a|s)
πθ(a∣s),即学习一个策略来得到尽量高的回报。
评论家(Critic)是指值函数
V
π
(
s
)
V^{\pi}(s)
Vπ(s),对当前策略的值函数进行估计,即评估演员的好坏。
借助于值函数,演员-评论家算法可以进行单步更新参数,不需要等到回合结束才进行更新。
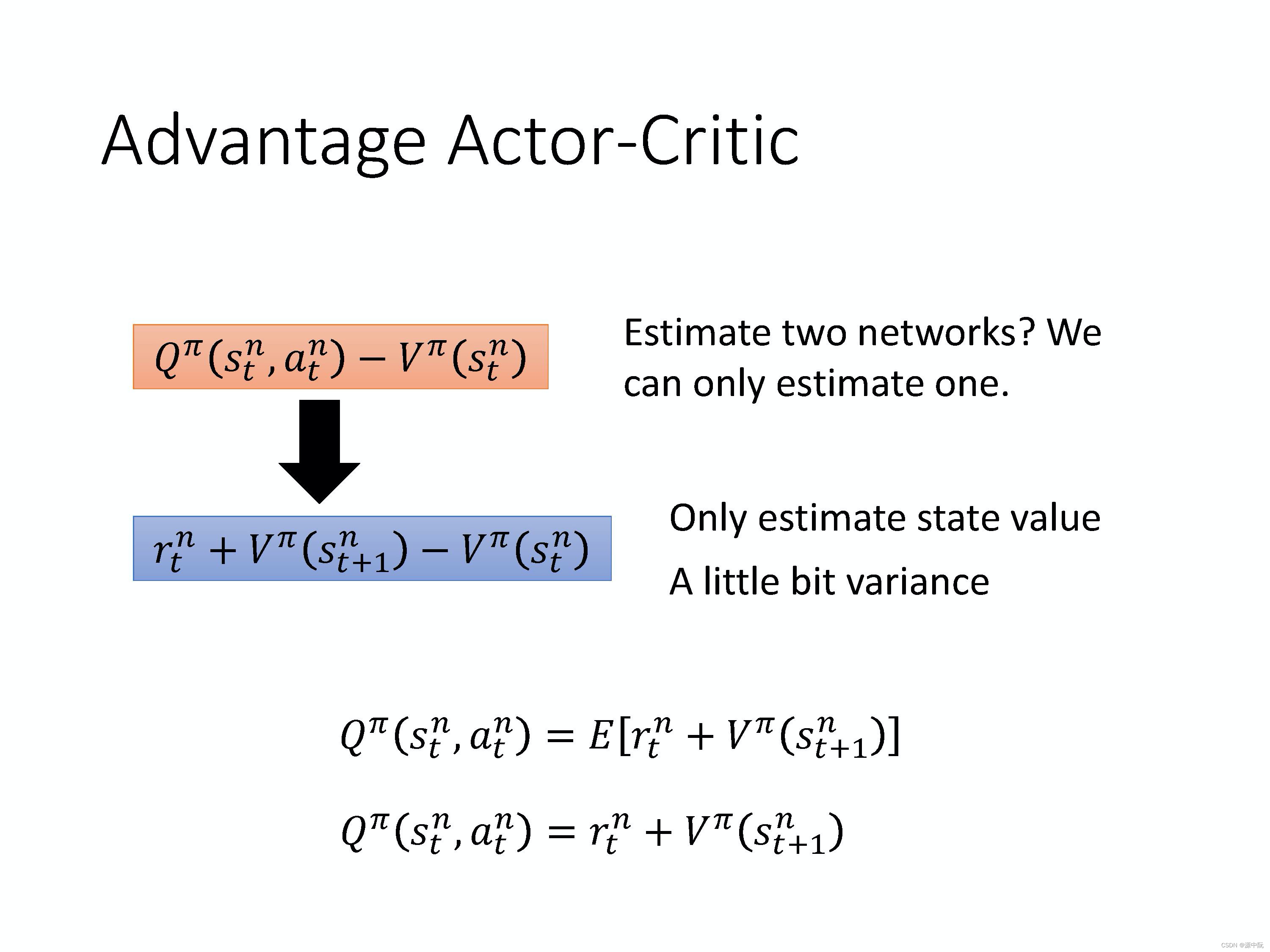
Advantage Actor-Critic
A3C
A3C 这个方法就是同时开很多个 worker,那每一个 worker 其实就是一个影分身。那最后这些影分身会把所有的经验,通通集合在一起。
Pathwise Derivative Policy Gradient
Q-learning 解连续动作的一种特别的方法,也可以看成是一种特别的 Actor-Critic 的方法。
Connection with GAN
收集各式各样的方法,告诉你说怎么样可以把 GAN 训练起来,尝试用在Actor-Critic上















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









