







写在前面的话:TD3只是改进训练用的算法,并不改变神经网络的结构。
1 DPG 的高估问题
由于DPG强化学习笔记:连续控制 & 确定策略梯度DPG_UQI-LIUWJ的博客-CSDN博客中也存在自举,所以也会面临高估问题。

2 目标网络(DDPG)
为了解决自举造成的高估,我们使用目标网络来计算价值网络的TD目标。
训练中需要的两个目标网络:
他们与价值网络、策略网络的结构完全相同,只是参数不同。
TD目标是用目标网络计算得到的:
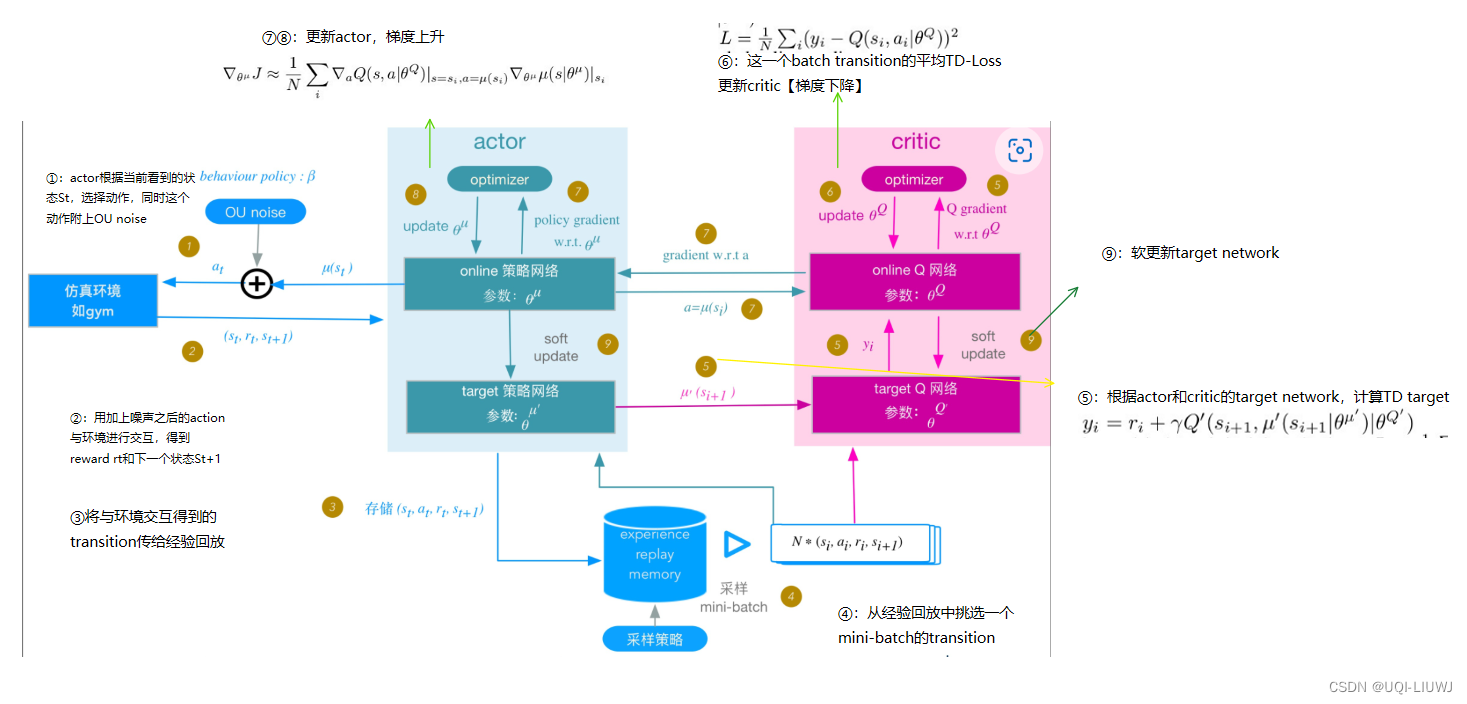
整体流程图如下:

- 用TD目标
作为
的目标,更新价值网络w
- 然后和DPG一样的方式,更新策略网络
- 最后对两个目标网络进行软更新
——>这种方法可以在一定程度上缓解高估,但是实验表明高估仍然很严重。
2.1 DDPG
Deep Deterministic Policy Gradient
DPG的基础上+target network

强化学习笔记 Ornstein-Uhlenbeck 噪声和DDPG_UQI-LIUWJ的博客-CSDN博客
3 截断双Q学习clipped double Q-learning
使用一对策略网络和目标网络的话,虽然能够在一定程度上解决高估问题,但这样也会带来高方差。
这种方法使用两个价值网络和一个策略网络
这三个神经网络分别对应了一个目标网络
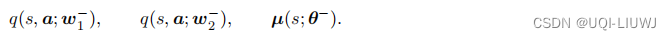
流程如下:
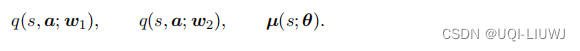

- 用目标策略网络计算动作
- 两个目标价值网络的结果:
- 我们取目标价值网络中较小的作为TD目标
- 然后用这个 TD目标来更新价值网络1和价值网络2
- 价值网络1的q(s,a;w)继续用来更新策略网络
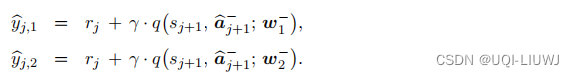
个人觉得,这样设置的作用是用 不参与策略网络更新的价值网络(价值网络2)来约束策略网络导致的高估:
策略网络希望价值网络越大越好(可以近似看成取maxDQN笔记:高估问题 & target network & Double DQN_UQI-LIUWJ的博客-CSDN博客中我们知道,最大化会导致高估);但是我们用另一个价值网络来约束价值网络1,不让他特别地大
3.1 往动作中加入噪声
我们可以把目标策略网络计算动作的操作从
改造成
公式中的
是一个随机变量,表示噪声,它的每一个元素独立随机从截断正态分布中采样
截断正态分布记作,表示均值为0,标准差为σ。但是在[-c,c]之外的变量概率为0
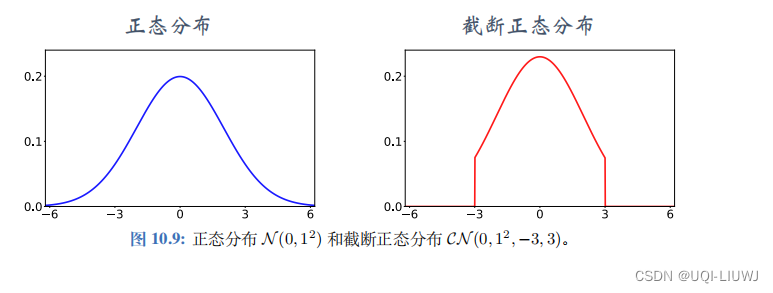
使用截断正态分布而不是正态分布,是为了防止噪声过大
引入了噪声,是为了预估更准确,网络鲁棒性更强些。
3.2 减少更新策略网络和目标网络的频率
- Actor-Critic 用价值网络来指导策略网络的更新。
- 如果价值网络 q 本身不可靠,那么用价值网络 q 给动作打的分数是不准确的,无助于改进策略网络 µ。
- 在价值网络 q 还很差的时候就急于更新 µ,非但不能改进 µ,反而会由于 µ 的变化导致 q 的训练不稳定。
-
实验表明,应当让策略网络 µ 以及三个目标网络的更新慢于价值网络 q 。传统的 Actor-Critic 的每一轮训练都对策略网络、价值网络、以及目标网络做一次更新。
-
更好的 方法是每一轮更新一次价值网络,但是每隔 k 轮更新一次策略网络和三个目标网络。
-
k 是超参数,需要调。
-
4 TD3
使用截断双Q【缓解价值网络的高估】+噪声【平滑作用】+降低策略网络和目标网络更新频率的算法被称为双延时确定策略梯度 (Twin Delayed Deep Deterministic Policy Gradient),缩写是 TD3。
TD3 与 DPG 都属于异策略 (Offff-policy),可以用任意的行为策略收集经验,事后做经验回放训练策略网络和价值网络。
收集经验的方式与原始的训练算法相同,用 at = µ(st; θ) + ϵ 与环境交互,把观测到的四元组 存入经验回放数组。
4.1 训练流程
- 1,每一次从数组中随机抽取一个四元组
- 2,
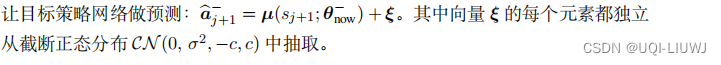
- 3
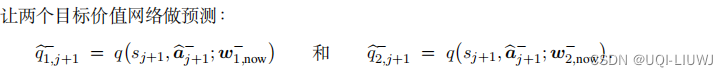
- 4
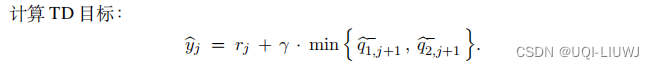
- 5
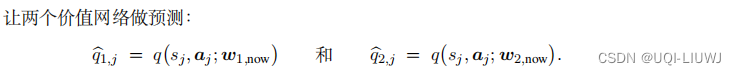
- 6

- 7

- 8 每隔 k 轮更新一次策略网络和三个目标网络:
-

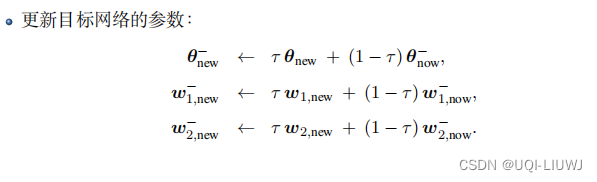
















 1250
1250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











