






文章从MLP(多层感知机)开始 :
多层感知机本质上是矩阵之间的乘法加上激活函数的非线性拟合。
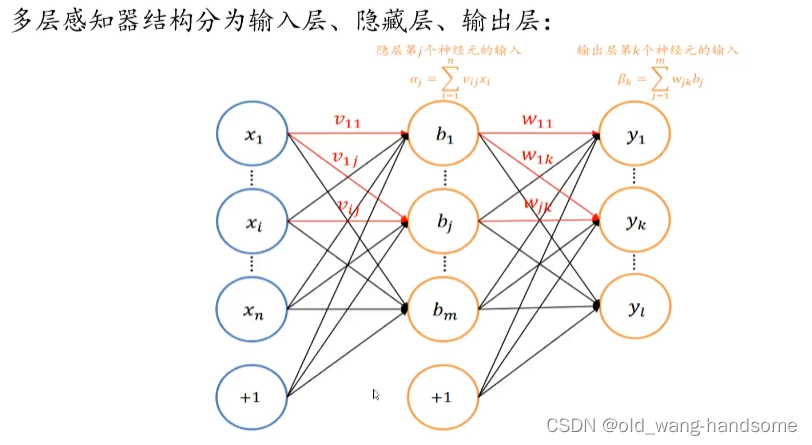
上图是典型的画法,写成公式就是F(X)=g(X*W+b) 图片来源(4.5多层感知机_哔哩哔哩_bilibili)
现在再了解一下one-hot编码,做nlp的同学们想必都非常了解,这里简单解释一下:
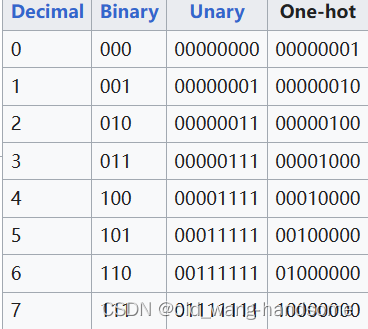
我们先采用最简单的one-hot编码,不进行什么花里胡哨的嵌入矩阵,词相近等等技术,那么假设有10个数字,我们就采用10维的向量,这样就可以保证每一个数字就有对应的向量与之一一映射,假设67个数字,那么就可以用67维的向量来表示,对吧,这很简单,那么数字1就可以表示为向量000000.....000001,数字2就表示为0000000....000010。
前提知识了解后,现在我们开始再上一个台阶:
在文章《Do Machine Learning Models Memorize or Generalize?》Do Machine Learning Models Memorize or Generalize? (pair.withgoogle.com)中有这些实验:我们将随机序列 1 个 0 和 1,并训练我们的模型来预测前三位数字中是否有奇数,例如:000110010110001010111001001011 是 0,而 010110010110001010111001001011 是 1,采用MLP来进行判断,本质上,这里只要前三个是有用的数据,而其他的是干扰项。
实验就设计为一个向量,向量就是000110010110001010111001001011等数字为输入,经过单层感知机,也就是 F(X)=g(X*W+b),其中X就是上面的数字,W为32*32的矩阵,g是relu激活函数,实验的结果是32维的向量,这个向量刚好是one-hot数字,根据向量就可以看判断的个数是多少了。这样一个简单的实验平平无奇,但是当我们训练的过程中我们会发现:
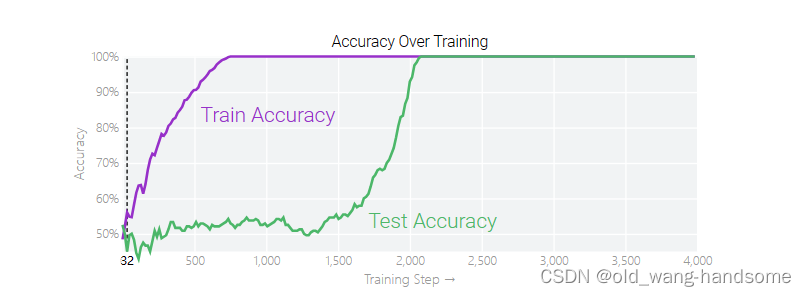
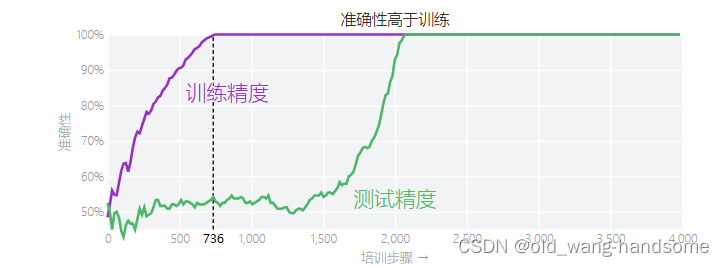
随着训练的过程的增加,训练集的准确程度再很早就收敛了,但是只要当训练很久才会再测试集上提高准确度,模型在训练了很长时间后似乎突然开窍。这种现象,即在拟合训练数据后很久才突然发生——被称为 grokking。

上图是经典的一张图
这一现象很有趣,我们庖丁解牛这一现象,想一想W里面的参数是什么样子的???
我们在700到900轮左右的训练后就发现训练集的准确程度就收敛了,此时W内是杂乱无章的,虽然训练集的loss损失是不大,但是测试时似乎还是在瞎猜一样。
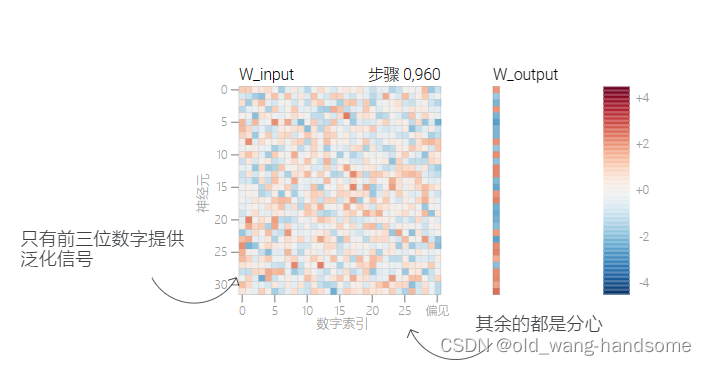
当我们继续训练到2000轮之后,我们会惊奇的发现test的loss迅速降低,同时伴随着W的有规律变化。
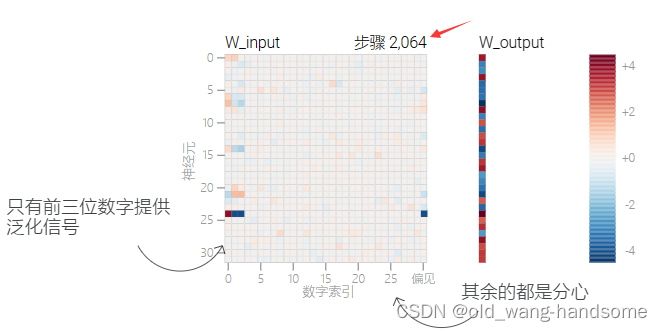
在前1000轮时,该模型看起来密集且嘈杂,在下面的图表中分布着许多高量级权重(显示为深红色和蓝色方块)。当模型获得完美的测试精度时,我们看到所有与分散注意力的数字相关的权重都以非常低的值变灰,模型只专注于前三位数字。
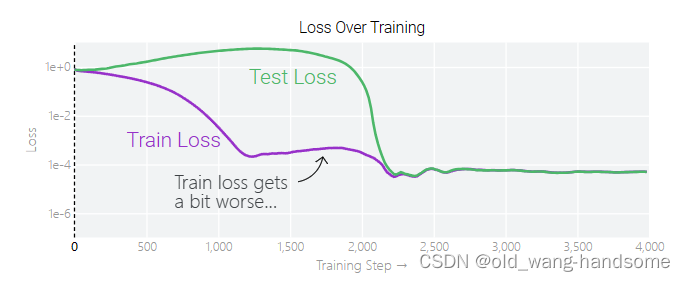
分离开训练和测试的loss,我们还会发现先一个点是在grokking前,训练集的loss是进行了一点点的上升,这一点我十分好奇,在原文中的解释是——在模型泛化之前,训练损失略微增加(输出准确略微降低),因为它在减小与输出正确标签相关的损失的同时,也在降低权重,从而获得尽可能小的权重。
这一个现象使得我很好奇,同时文章的也提到:“
「顿悟」是一种偶然现象——如果模型大小、权重衰减、数据大小以及其他超参数不合适,它就不会出现。
当权重衰减过小时,模型无法摆脱对训练数据的过拟合。
增加更多的权重衰减会推动模型在记忆后进行泛化。进一步增加权重衰减会导致测试数据和训练数据的不准确率提高;模型直接进入泛化阶段。”
这里就要提到权重衰减这一概念:

12 权重衰退【动手学深度学习v2】_哔哩哔哩_bilibili
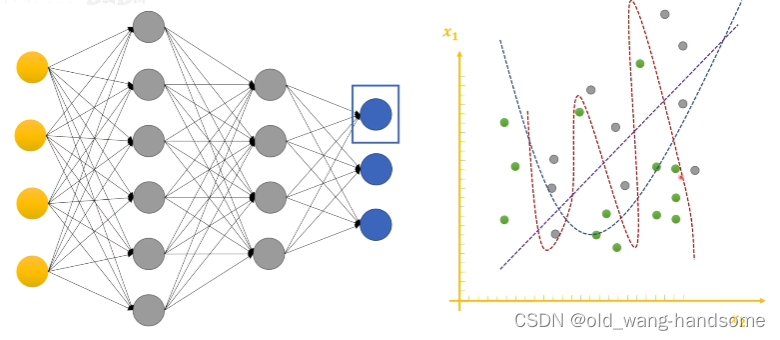
权重衰减就是为了限制W不叫其过拟合的一种常规手段,上图的公式和下图的三个曲线其实很好的解释这样做法。我们单独拆解一个神经元时,单个神经元的目标就是找到一条线(当然这是简单的描述,本质是一个分界线)会呈现我们下图我们看到有三条曲线,三条曲线分别对三个状态。直线对应的是欠拟合,而红色的波浪线对应的是过拟合,最后类似二次函数的曲线是我们最终希望的拟合函数。
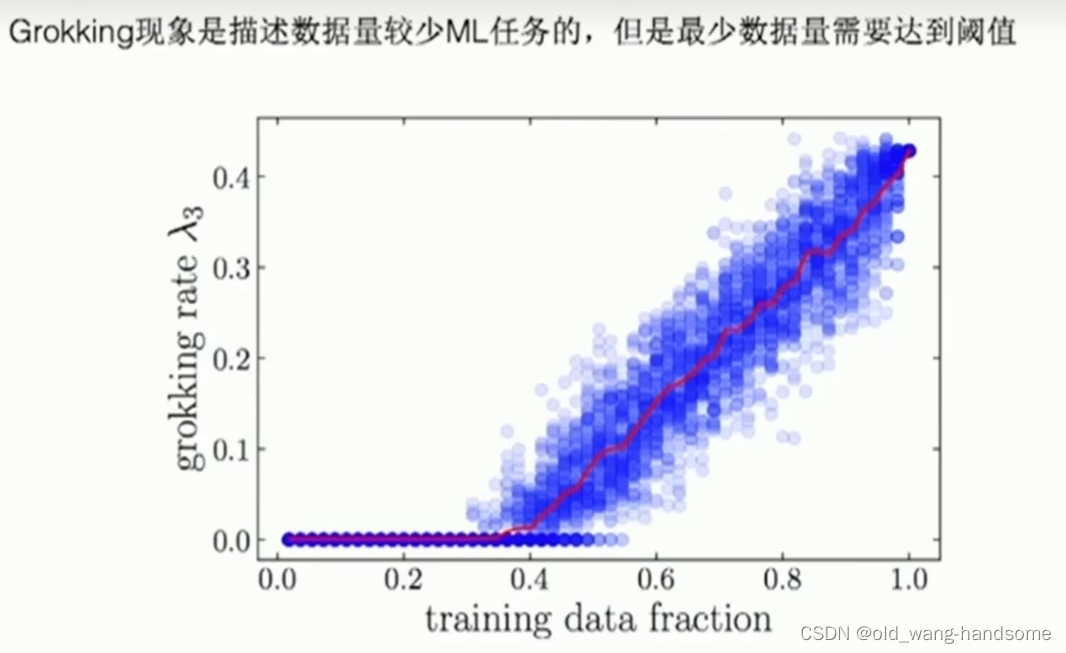
回到我们刚刚的数数字实验中,模型出现的grokking和W参数中出现的除数字外相关的权重都变为0(近似)有强相关。同时模型能否出现grokking,必须依赖于模型进行过权重衰减,并且也高度依赖数据大小的限制,下图是只有当训练数据占比大于40%时才可能出现grokking。 而权重衰减的本质数学特征是在生成拟合函数的过程中不断的去惩罚泰勒展开过程中大于1的高次项,其目的就是防止函数在训练集上拟合的过于优秀,而损失其在测试集上的泛化型。
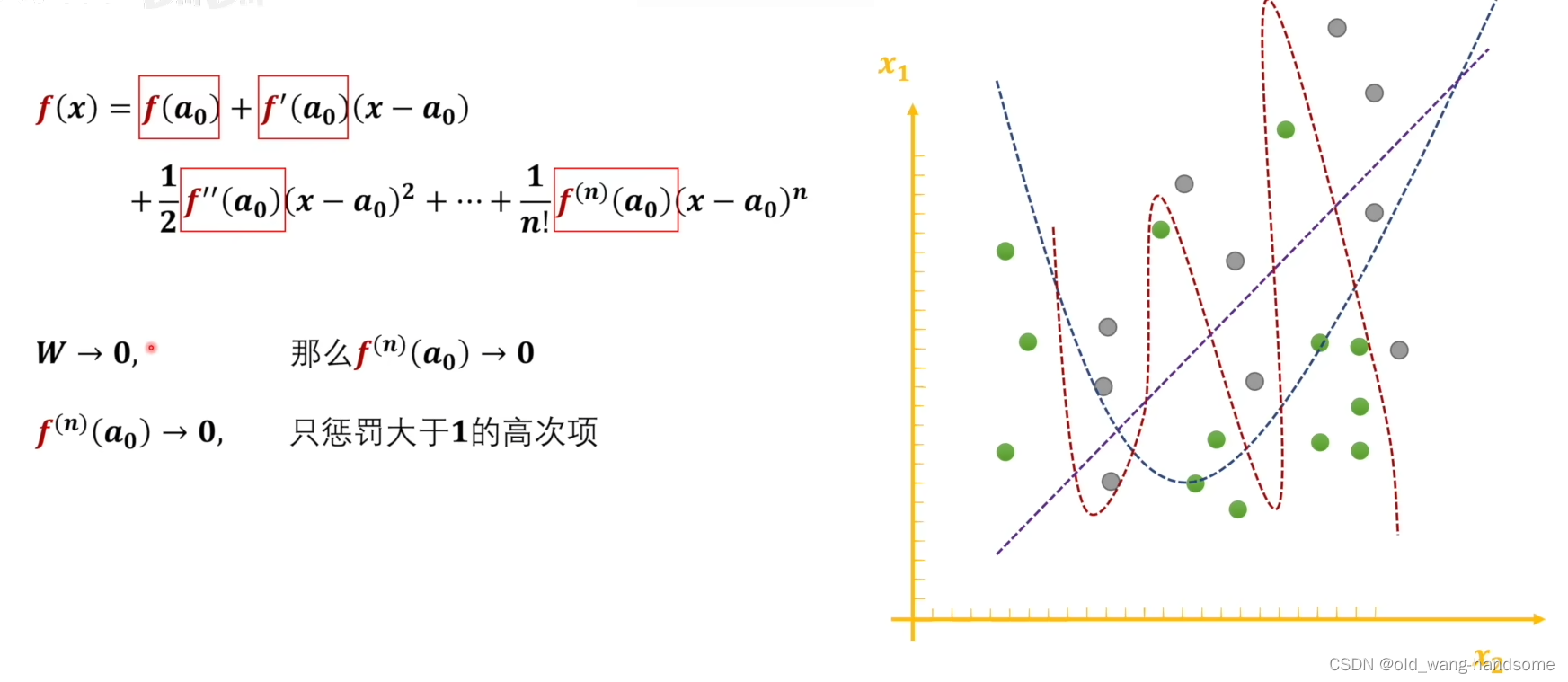
对此,我个人从权重衰减的理解 就是grokking的出现是一个从欠拟合到过拟合再通过权重衰减而到达预期拟合的一个过程,当然有人会提出疑问,为什么在通过欠拟合到过拟合的过程中不会经历一次预期拟合呢? 其实这里就体现到了一个超参数的重要性。由于前期训练过程中训练集的loss的权重是大于对高次项的惩罚权重的,由此训练的过程会尽可能的向训练集的更低loss去靠拢,因此这一过程会直接进入过拟合;而当训练集的loss趋于稳定时,高次项的惩罚会开始起作用。但是有一个令人意外的现象是,伴随着grokking的出现的同时W内的参数会呈现出规律性。
对此设计了另外一个比较经典的实验,即a+b mod n ,假设a,b是0到66中的一个数,即 a={0,1,...,66} ,b={0,1,...,66} ,显然a+b mod n 也在{0,1,...,66}中,实验类比于刚刚的数数字实验,采用一个 24 个神经元的单层 MLP,公式为
其中由于a和b有67种可能,所以分别用两个67维向量表示a,b这两个随机数,由于采用24个神经元,所以W1的维度就是67*24,同时W2为24*67,来保证输出被映射为一个67位向量。
实验开始前初始化W1(图中W_input)为0

而当训练到达1000轮时,训练集的loss已经收敛但是我们看到W1和W2依旧杂乱无章。

而当达到grokking后(40000轮),W参数开始变得有规律了起来。本质上,这个实验就是一个循环,数字永远都在0到66中循环,这个规律是很明显的。

当模型grokking后,特定的参数变得有规律的时候,我们可以看到参数按照一高一低的有规律的变化,为此又设计了另外一个实验,也就是内置一个固定的W权重,下图为内置的权重,这就相当于内置一个循环。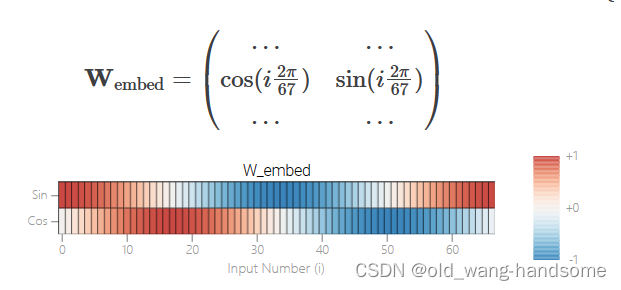
我们可以训练一个更简单的模型,只使用5个神经元,同时构建一个嵌入矩阵,将a和b通过计算在sin和cos上的大小来表达可能的数字。可能上面说的有些绕口,简单理解就是内置一个sin和cos的函数,然后固定这个W_embed,再次训练,公式如下:

其中W_embed为2*67维矩阵,W_in proj 为2*5维矩阵,W_out-proj为5*2维矩阵,继续实验
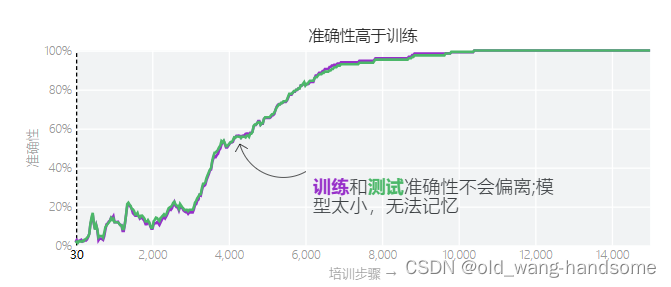
我们可以看到这个过程没有出现grokking,原因是模型太小,直接就拟合成功了,同时在训练的过程中,我们发现分量慢慢的逼近,分到了对应的分量上。
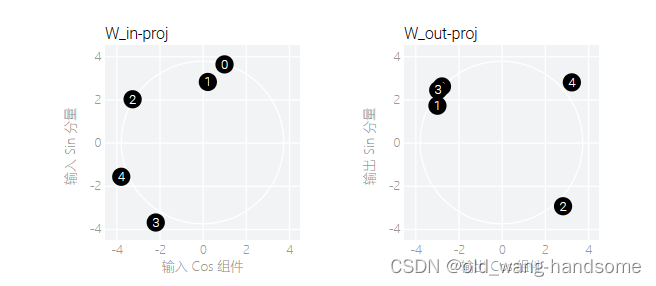

上面的可能较为抽象,没有懂不要紧,总结一下就是24个神经元的MLP在grokking后学习到了周期性,我们为了探究模型是记忆还是理解,所有又进行一个5个神经元的MLP同时内置一个自带的周期的sin/cos权重,来探究一下内部的过程,结论就是24个神经元的MLP在grokking后学习到了sin和cos的周期规律,“理解”了周期的规律或者说是学习到了周期的规律。另一个结论就是grokking的出现可能是一个从欠拟合到过拟合再通过权重衰减而到达预期拟合的一个过程。
好,文章到这里都只是,上面的这些只是铺垫,下面开始我们的主题——谈谈关于大语言模型能力涌现的个人看法
涌现现象:
直白一点说,就是一些简单普通甚至是无意义的操作,在相互作用之后,产生了具有极大意义的行为。例如说山顶的雪化成水,水顺着河流流向大海,海水蒸发成水蒸气进入了大气,而大气又把水气运到了山顶。看似每个环节都很简单,然而它们聚合在一起,却形成了人们赖以生存的水循环系统。
而这种涌现现象被很多时候认定为伪科学。因为主流的理论还是为还原论来解释的,即大任务拆解为小任务后,对小任务的明确会反过来明确大任务。例如车子是个个零部件来铸成的,当每一个生产都完成后,就组装成了车。至于自然界的涌现是伪科学吗?我也不好评论,但是我们先从大模型入手,来探究一下大模型的涌现。
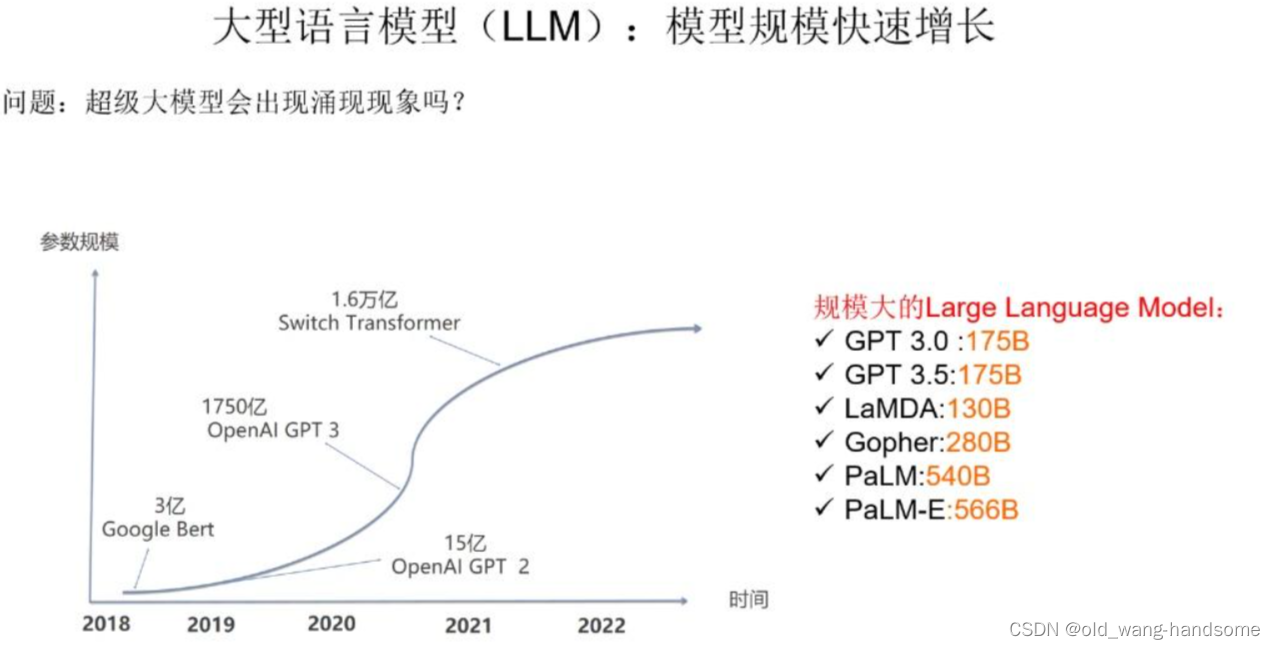
大规模模型一般超过 100B,并且大模型的涌现现象已经被很多人研究了。
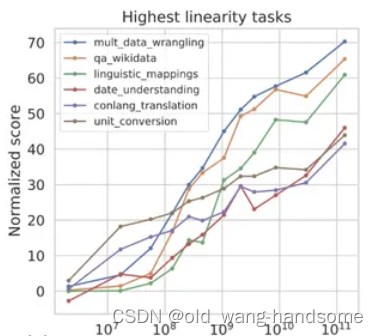
我们看到:大语言模型规模不断增长时,对下游任务有什么影响?对于不同类型的任务,有三种不同的表现,第一类一般是知识密集型任务。这类任务指的是在不超过外部知识的前提下,对内容进行检索,类似于背课文,默写单词。直白点就是学习了知识的总量。随着模型和数据规模的不断增长,任务效果也持续增长,这其实显而易见的,随着知识的增加,效果会越来越好。下图1是对这类任务的增长曲线。
第二类为抗干扰的实验,即主任务中存在多个子任务,子任务中存在干扰项,这类任务会随着模型规模增长,任务效果体现出一个U 形曲线。如上图2所示,随着模型规模增长,刚开始模型效果会呈下降趋势,但当模型规模足够大时,效果反而会提升,个人的理解是当前期的时候,模型只会随机的进行着预测,而当模型在渐渐增加的过程中,却被子任务干扰项给欺骗,导致性能一塌糊涂,但是规模过大会渐渐屏蔽掉干扰项,因此会呈现U型,当然这只是一个合理的假设,更多的实验和验证还有待去后续证明。
第三类就是我们所说的涌现:
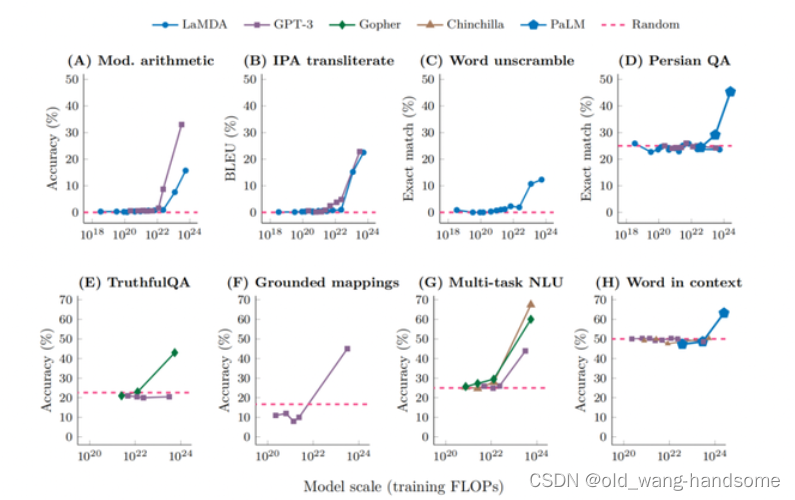
而这类涌现现象多来自于多步骤构成任务,这类任务大多是根据多个步骤构成的复杂任务,列如单词的解读,语境的判断或者是思维链等等。下图为一个简单的思维链的例子:

由于深度学习存在很多的不可解释性,因此当大模型开始出现涌现现象后,很多人们开始说是否大模型会呈现出意识或者毁灭人类这样的言论。对于这些言论我不予评价,不过我本人其实在chatGPT刚刚兴起时只认为这是在简单的把学习到的内容进行简单复刻的过程,当然后续的大语言模型的表现显然证明这不只是单纯的背诵或复刻。至少学习到了一定的规律,这点后面会说。
关于涌现现象有几个可以解释的点:
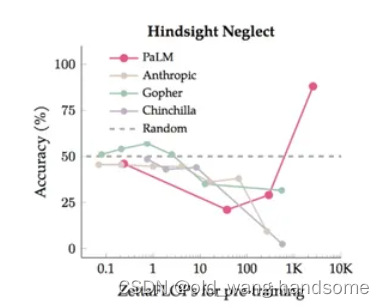
首先在「别太迷信大模型的涌现,世界上哪儿有那么多奇迹?」 (https://arxiv.org/pdf/2304.15004.pdf) 斯坦福大学的研究者发现,大模型的涌现与任务的评价指标强相关,并非模型行为在特定任务和规模下的基本变化,换一些更连续、平滑的指标后,涌现现象就不那么明显了,更接近线性,也就是说,涌现能力可能是一种海市蜃楼,主要是由于研究者选择了一种非线性或不连续地改变 per-token 错误率的度量,部分原因是由于拥有太少的测试数据,不足以准确估计较小模型的性能,下图是两个度量指标。

引用一下张俊林老师的一张图:可以看到其实在多步骤构成任务中,只有一个标准答案,而当我们在接近答案的过程中我们的评价依然为0。
 因此在模型逐步增大的过程中,我们对中等模型的评价是不太友好的,因此出现了顿悟的现象,但是如果我们选取较为平滑的评价指标后,顿悟现象似乎就荡然无存了。因此涌现能力的一部分可能的原因出现在非线性 / 非连续度量上。
因此在模型逐步增大的过程中,我们对中等模型的评价是不太友好的,因此出现了顿悟的现象,但是如果我们选取较为平滑的评价指标后,顿悟现象似乎就荡然无存了。因此涌现能力的一部分可能的原因出现在非线性 / 非连续度量上。
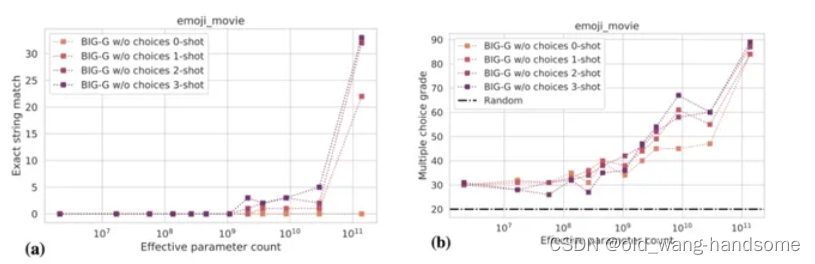
另一方面,依然借用张老师的一张图,嘿嘿,即复杂的任务与子任务之间的指标不对等,举一个例子,当有5个子任务只有5部都对时才会判定为对,即子任务只有全部完成后集成为一个大的任务才会被判定为完成,以象棋为例,我们的每一步棋都会影响我们最后比赛的结果,而只有当将军后绝杀无解才会判定为主任务的完成。
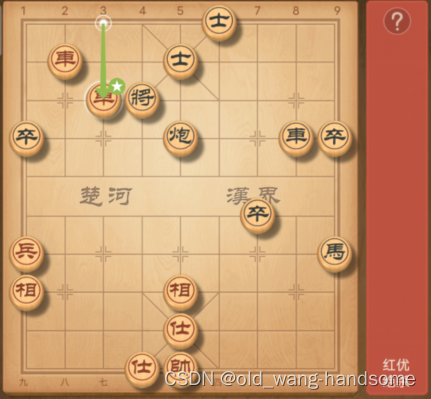
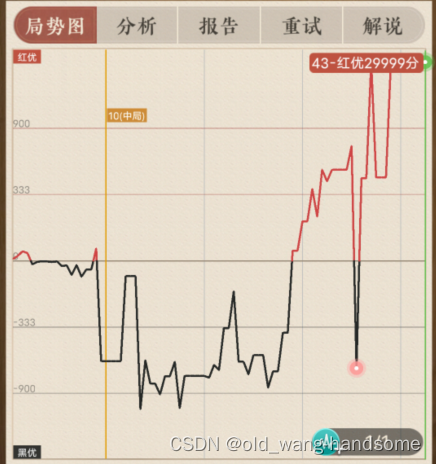
如下图所示,让语言模型预测下一步,最终评价指标是只有“绝杀”才算赢。如果按“绝杀”评估(红线),发现随着模型增大,模型在缓慢上升,符合涌现的表现。若评估LLM合法移动(绿线),而在合法的移动步骤里进行正确选择才够最后“绝杀”是个子任务,所以其实这是比绝杀简单的一个子任务。我们看合法移动随着模型规模,效果持续上升。此时,我们是看不到涌现现象的。

因此大语言模型的涌现似乎是一场评价指标不够圆滑而导致的闹剧, 同时grokking的出现一部分又是因为过拟合到预期拟合在转变过程中的产物,但两者又那么相似,不妨换一个解读:大语言模型从最大模型一点点拆分后,其实可以看成无数个子模型,不妨就拿MLP在顿悟后找到了事物的规律着一点出发来探讨一下大语言模型的涌现。 结合刚刚的对grokking的描述,简单的MLP在学习的过程中是展现了对规律的掌握,那么大语言在逐步增大的过程中会包含越来越多的数据,还记得刚刚上面讲到的—— 只有当训练数据占比大于40%时才可能出现grokking。 同时在生成拟合函数的过程中不断的去惩罚泰勒展开过程中大于1的高次项。 那么当每一个大语言的子部分随着数据的增加,训练的占比渐渐都大于40%,同时有些任务会被反复的训练(尽管大任务可能就200轮,但是子任务有重叠,所以就单个子任务来说会被训练很多次),以此出现了从过拟合到预期拟合的过程,增加了其泛化型。 总结来说就是大语言模型的不断增加会诱导更多的子任务在这个过程中grokking,即更多的子任务学习到了规律,理解了这个子任务的本质。当然这暂时没有科学依据,相比于前两个被实验证实的结论,这个更多的只是在看了张老师文章后自己的脑洞罢了。
总结:
因此我个人认为大语言模型出现顿悟的最大可能是评价指标不够圆滑,同时对子任务的拆解存在一些不到位的地方。但是不可否认的是大语言模型的某些个别子任务可能会出现grokking现象,并且真的学习到的不只是知识,也学习到了个别任务本质的规律。有些文章为了流量或者点击,说些奇奇怪怪的博人眼球的东西,例如大语言会产生意识等等吧,未来不确定,但是现在定论大语言会产生意识或者过度神秘化大语言模型,甚至神秘化深度学习,那我个人认为是大可不必的。
















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











