







paer:Training data-efficient image transformers & distillation through attention
official implementation:GitHub - facebookresearch/deit: Official DeiT repository
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/deit.py
存在的问题
Vision Transformer (ViT) 是一种直接从 NLP 继承的架构,应用于图像分类任务,但需要大规模的私有标注图像数据集(如 JFT-300M,3亿张图片)进行预训练。该文章的结论是:Transformer“在数据量不足的训练下不能很好地泛化”,而这些模型的训练涉及大量的计算资源。大量的数据和计算资源都限制了高性能视觉 Transformer 的应用范围。
本文的创新点
- 数据高效的训练策略(DeiT):本文提出了一种在单节点上使用8个GPU进行两到三天训练的方法,使视觉Transformer在仅使用ImageNet数据集的情况下也能达到与CNN相当的性能。
- 蒸馏策略:引入了一种基于蒸馏token的特定于Transformer的蒸馏策略,显著优于传统的蒸馏方法。
- 性能提升:通过这种蒸馏策略,作者展示了在不使用外部数据的情况下,Transformer 模型可以达到与卷积网络相媲美的性能。同时在多项任务中验证了模型的迁移学习能力,包括细粒度分类和多个公共基准数据集,表明该方法具有良好的泛化能力。
方法介绍
Soft distillation 传统的知识蒸馏最小化教师和学生模型softmax输出的KL散度。假设 \(Z_t\) 表示教师模型的logits,\(Z_s\) 表示学生模型的logits,\(\tau\) 表示蒸馏温度,\(\lambda\) 是蒸馏KL散度损失和与ground truth标签 \(y\) 之间的交叉熵损失的平衡系数,\(\psi\) 是softmax函数,则蒸馏目标函数为
![]()
Hard-label distillation. 本文引入了一种蒸馏的变体,将教师模型的预测结果(这里原文是hard decision,这里用argmax不就是教师模型的预测结果吗?也没有设score阈值过滤,为什么叫hard decision?)作为标签,\(y_t=argmax_cZ_t(c)\) 表示教师模型的预测结果,对应hard-label的蒸馏的目标函数为
![]()
对于一张给定的图片,教师模型给出的hard label可能会随着具体数据增强的变化而变化。我们会看到这种选择比传统的选择更好,同时没有参数,概念上也更简单:教师的预测 \(y_t\) 起着和ground truth标签 \(y\) 相同的作用。
同时还要注意通过label smooth硬标签也可以转换为软标签,其中true label的概率为 \(1-\varepsilon \),剩余其它类别均分 \(\varepsilon \)。
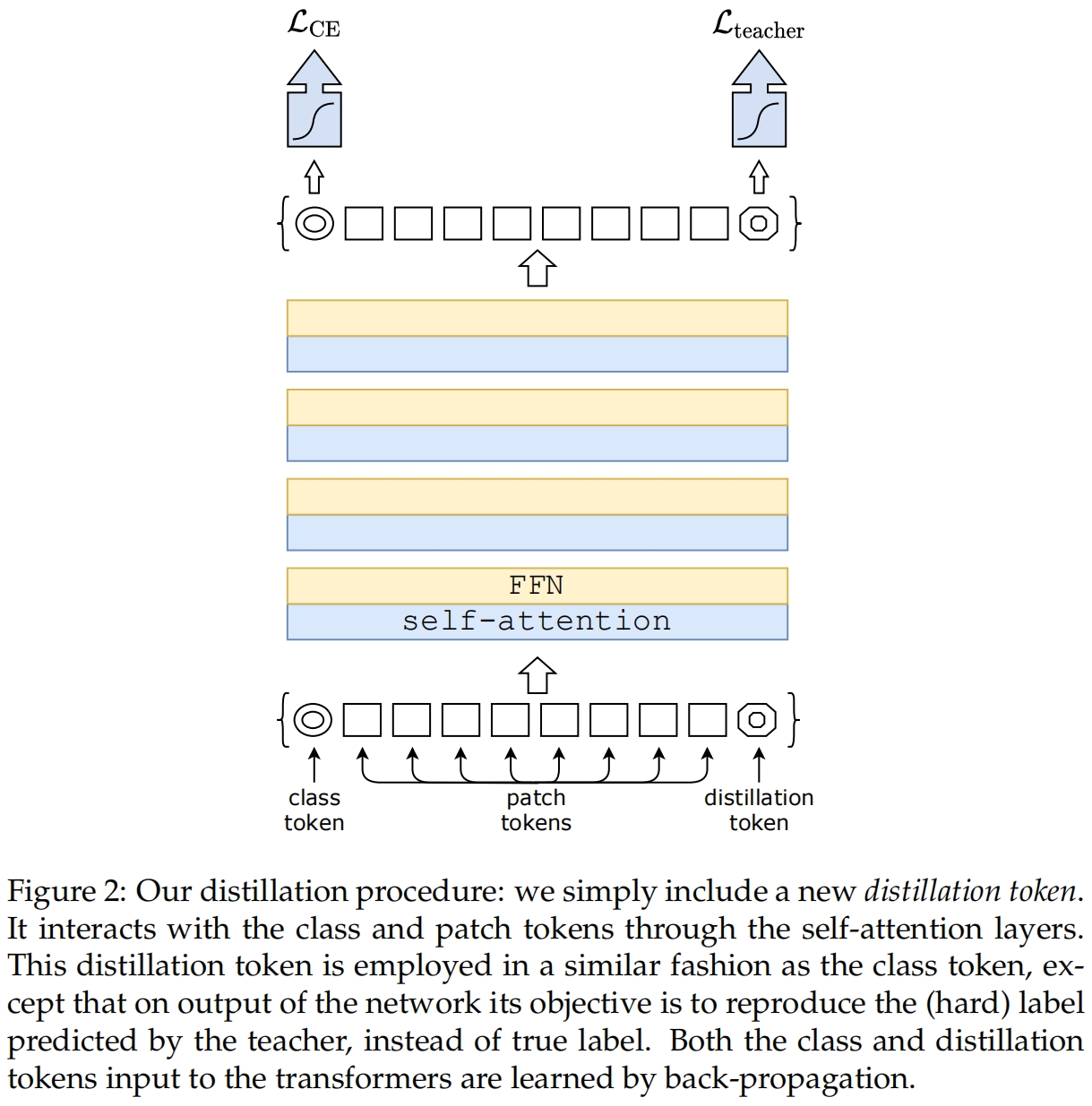
Distillation token. 如图2所示,本文提出了向初始的embedding添加一个distillation token,它和class token的使用类似:通过self-attention和其它embeddings进行交互,并在网络的最后一层输出。蒸馏embedding让模型可以从教师的输出中学习,就像常规的蒸馏一样,同时又与class embedding互补。
有趣的是,作者观察到学习到的class token和distillation token收敛于不同的向量:这些token之间的平均余弦相似度为0.06。随着类别和蒸馏embeddings在每层进行计算,随着网络加深它们逐渐变得相似,一直到最后一层它们的相似度就很高了(cos=0.93)但仍然小于1。这是意料之中的,因为它们旨在得到相似但不完全相同的目标输出。
作者验证了蒸馏token确实向模型添加了一些东西,而不是额外添加了一个类别token:不用教师模型的伪标签,而是试验一个有两个class token的transformer。尽管随机且独立地初始化两个class token,训练过程中它们收敛于相同的向量(cos=0.999),并且输出embedding也是几乎相同的。额外添加的class token不会带来任何分类性能的提升,相反作者通过实验证明蒸馏token比原始的蒸馏baseline带来了显著的提升。
关于数据高效的训练策略会在实验部分介绍。
实验结果
本文的模型完全遵循 Vision Transformer 的架构,唯二的区别就是训练策略和蒸馏token。而且在预训练阶段不用MLP head而是一个线性classifier。为了避免混淆,之前的模型称为ViT,本文的模型都称为DeiT。如果没有特别说明,DeiT指的是DeiT-B,它和ViT-B的架构相同。当在更大的分辨率下微调DeiT时会在后面添加分辨率比如DeiT-B↑384。当使用本文的蒸馏方法时![]() 表示。
表示。
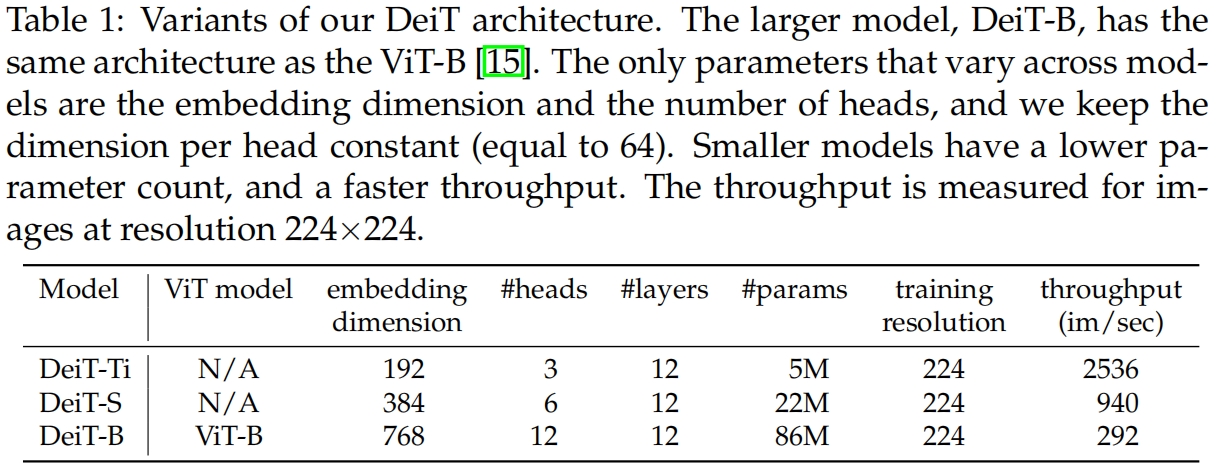
本文采用的三种DeiT详细配置如表1所示。
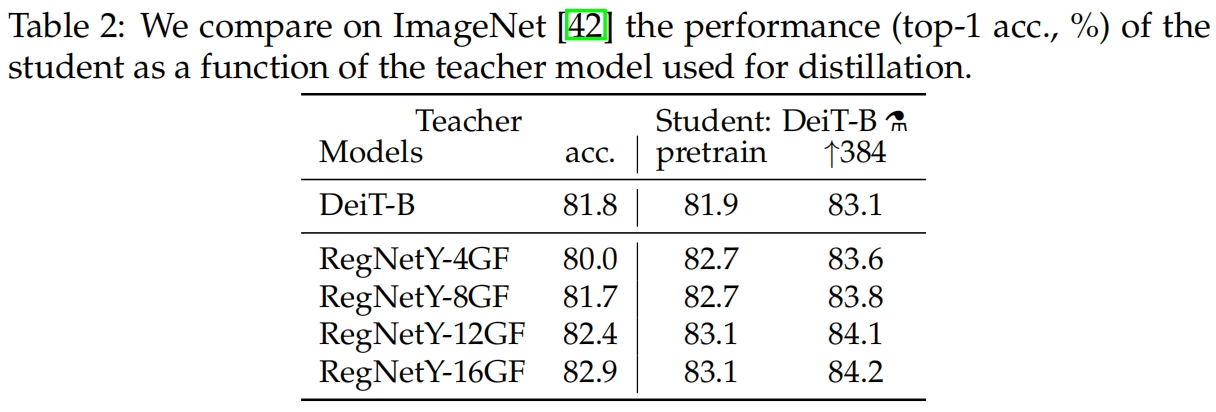
作者观察到使用卷积网络当做教师模型比使用transformer当做教师模型的效果好。表2比较了不同架构的教师模型蒸馏的结果。卷积是更好的教师可能是因为transformer学生模型通过蒸馏继承了卷积网络中的归纳偏置inductive bias。
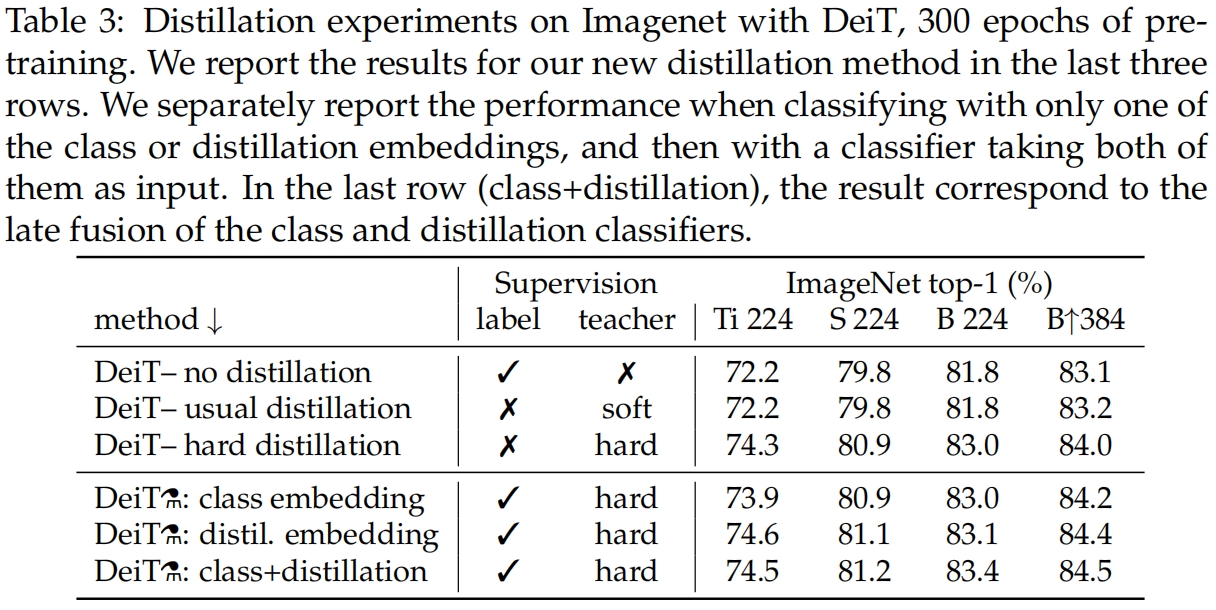
作者又比较了不同蒸馏方法的效果,结果如表3所示。可以看到对于transformer而言hard蒸馏的效果明显好于soft蒸馏,前者达到了83.0%的准确率而后者只有81.8%。而蒸馏token要比常规的在class token上进行蒸馏的效果要好。
和其它SOTA模型的对比
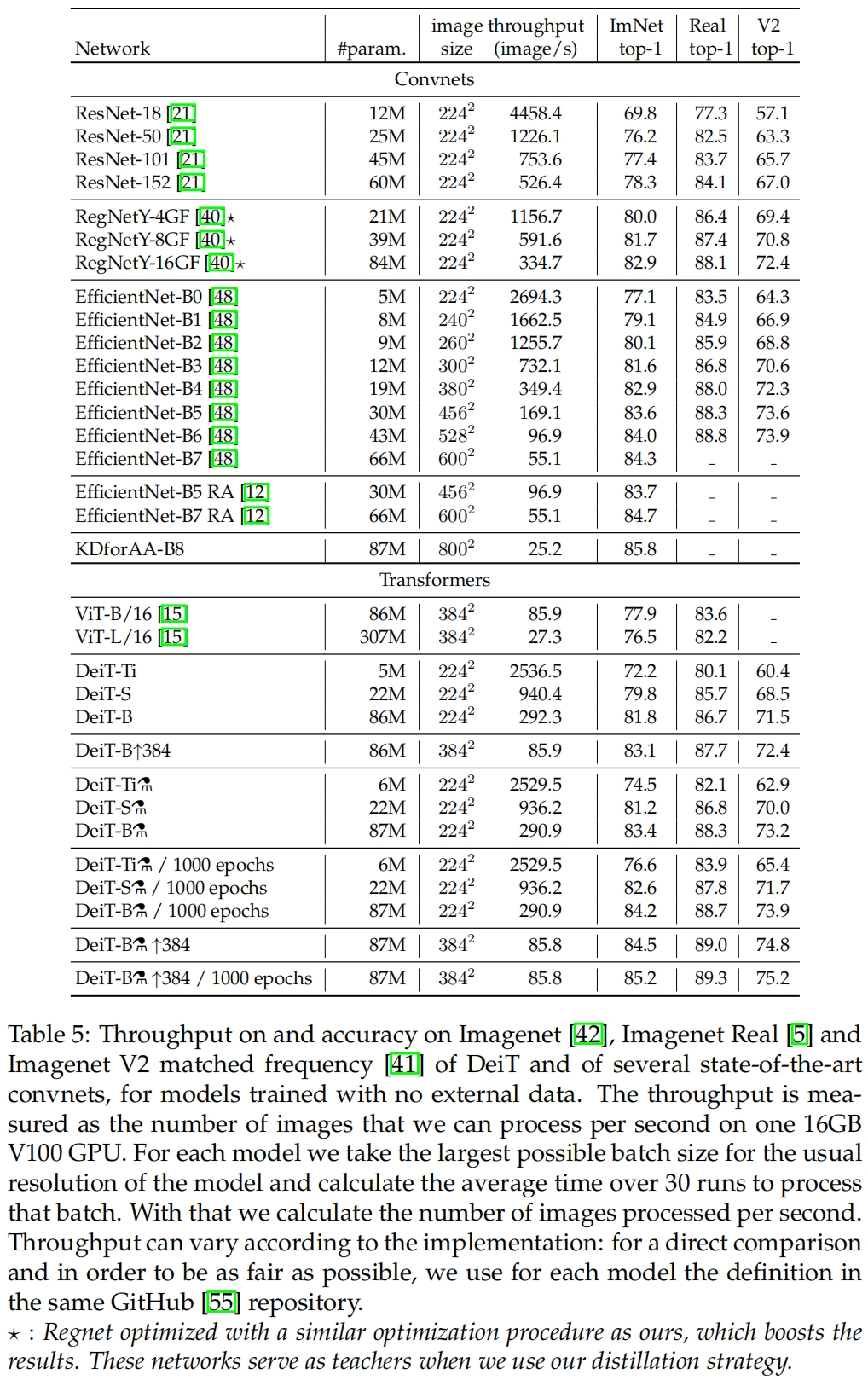
训练细节
本文创新内容包括高效的训练策略和distillation token,即使不蒸馏在高效的训练策略下,DeiT的精度也明显高于baseline的ViT。下面是具体介绍
Initialization and hyper-parameters. Transformer对初始化相对更加敏感,在测试了一些初始化方法后其中有一些会导致网络不收敛,最后采用截断正态分布来初始化权重。表9列出了作者在所有实验中默认采用的超参,对于常规的soft distillation,采用 \(\tau=3.0, \lambda=0.1\)。
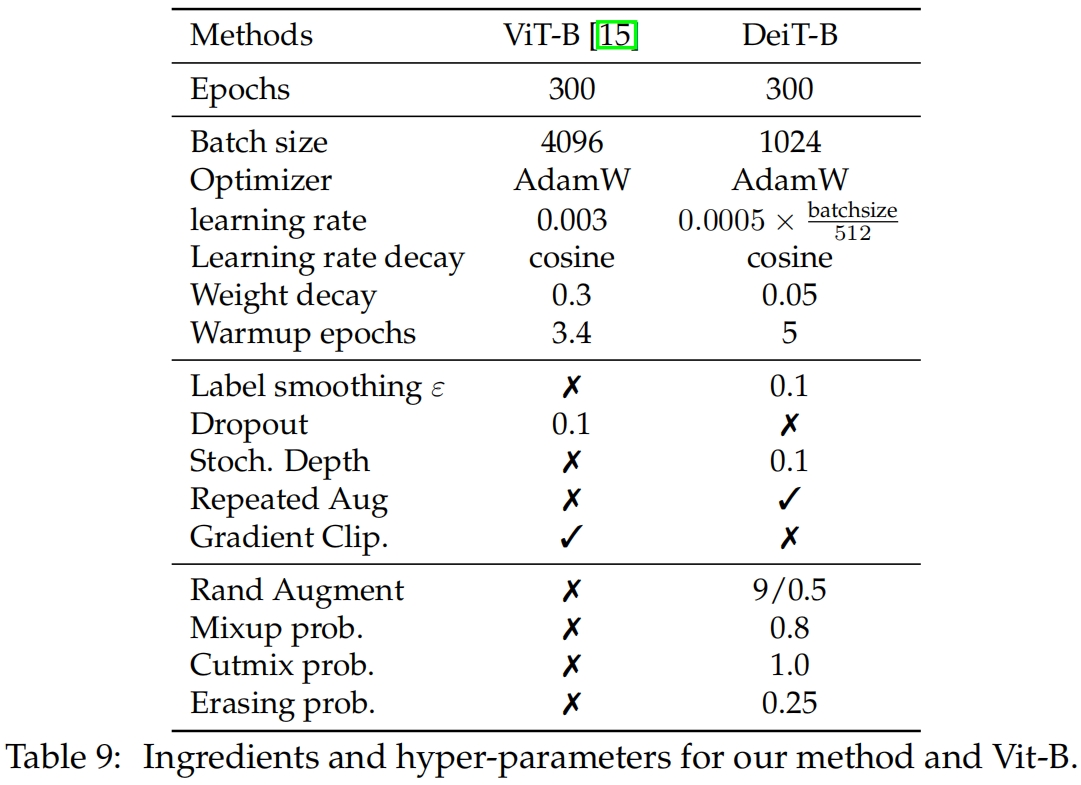
Data-Augmentation. 与集成了更多先验(如卷积)的模型相比,Transformer需要更多的数据。因此为了使用相同大小的数据集进行训练,需要更广泛的数据增强。为了达到data-efficient training的目的作者评估了不同类型的数据增强。Auto-Augment(AutoAugment(CVPR 2019)原理与代码解析_autoaugment代码-CSDN博客)、Rand-Augment(RandAugment(NeurIPS 2020)论文速读-CSDN博客)、random erasing(Random Erasing 原理与代码解析-CSDN博客)都对性能的提升有帮助。后两者作者采用timm库的实现并且通过消融试验,作者最终采用Rand-Augment而不是Auto-Augment。总得来说作者发现几乎所有的数据增强都对性能有提升作用,唯一的例外是dropout,因此作者在训练过程中不使用dropout。
Regularization & Optimizers. 作者考虑了不同的优化器,并交叉验证了不同的学习率和权重衰减。Transformer对超参数的设置很敏感。作者通过交叉验证得到的最好结果是使用AdamW优化器并使用与ViT相同的学习率同时使用小得多的权重衰减,因此ViT中的weight decay在本文的设置中影响了模型的收敛。
作者还使用了stochastic depth(Stochastic Depth 原理与代码解析_droppath(stochastic depth)-CSDN博客),它对模型的收敛有帮助。正则化如Mixup(数据增强Mixup原理与代码解读_mixup数据增强原理-CSDN博客)和Cutmix(CutMix原理与代码解读-CSDN博客)也都使用了,它们都性能提升都有帮助。作者还使用了repeated augmentation,它可以显著提高性能,是本文提出的训练策略的关键组成部分之一。
Exponential Moving Average(EMA). 作者评估了训练后模型的EMA,有一些小的增益精度提升了0.1,但在微调后消失了。
Fine-tuning at different resolution. 本文微调的schedule、正则化、优化过程都遵循FixEfficientNet,除了数据增强保持本文的方法。本文还对位置编码进行了插值,原则上任何插值方法都可以使用比如双线性插值。但是一个向量的双线性插值会降低其 \(\ell_2\)-norm,这些low-norm向量不适合于预训练的Transformer,并且如果直接使用而不进行任何微调会导致精度的明显下降。所以在用SGD或AdamW进行微调之前,作者采用近似保持向量norm的双边bicubic插值。
和ViT一样,训练DeiT用分辨率224,微调用384。


















 1812
1812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











