







文章目录
1. 概要
1.1 什么是语义分割
从像素水平上理解、识别图片内容,根据语义信息分割。如下图所示,输入为一张图片,输出像素水平的分割标记,每个像素会被识别为一个类别

1.2 语义分割作用
- 机器人视觉和场景理解
- 辅助/自动驾驶
- 医学X光
1.3 全卷积网络
- 全卷积化
- 将所有全连接层转换成卷积层
- 适应任意尺寸输入,输出低分辨率分割图片
- 反卷积(deconvolution)
- 将低分辨率图片进行上采样,输出同分辨率分割图片
- 跳层结构(skip layer)
如下图所示,前面部分通过卷积,特征图尺寸越来越小,最后需要通过将小的特征图反卷积成和图片大小相同的尺寸,这样边界识别问题比较大。因此会将之前的特征图信息和当前最后特征图一起处理

1.4 反卷积
反卷积(deconvolution)操作过程
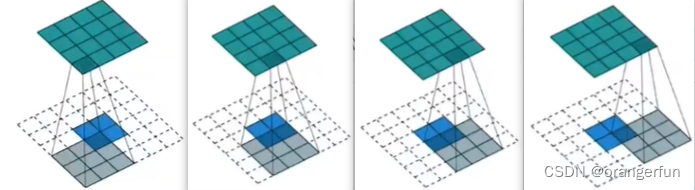
(1) 外围全补零(Full Padding)
- 输入 2 × 2 2 \times 2 2×2
- 输出 4 × 4 4 \times 4 4×4
- 参数设置:
- 卷积核尺寸: 3 × 3 3 \times 3 3×3
- 步长 1
- padding: 2
具体过程如下图所示
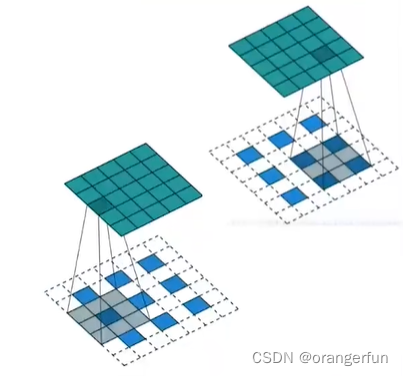
(2) 插零分数步长反卷积
- 输入: 3 × 3 3 \times 3 3×3
- 输出: 5 × 5 5 \times 5 5×5
- 卷积核尺寸: 3 × 3 3 \times 3 3×3
- 步长:2
- padding:1
1.5 上采样三种方式
(1)双线性插值
已知
Q
11
(
x
1
,
y
1
)
、
Q
12
(
x
1
,
y
2
)
、
Q
21
(
x
2
,
y
1
)
、
Q
22
(
x
2
,
y
2
)
Q_{11}(x_1,y_1)、Q_{12}(x_1,y_2)、Q_{21}(x_2,y_1)、Q_{22}(x_2,y_2)
Q11(x1,y1)、Q12(x1,y2)、Q21(x2,y1)、Q22(x2,y2),求其中点
P
(
x
,
y
)
P(x,y)
P(x,y)的值,如下图所示
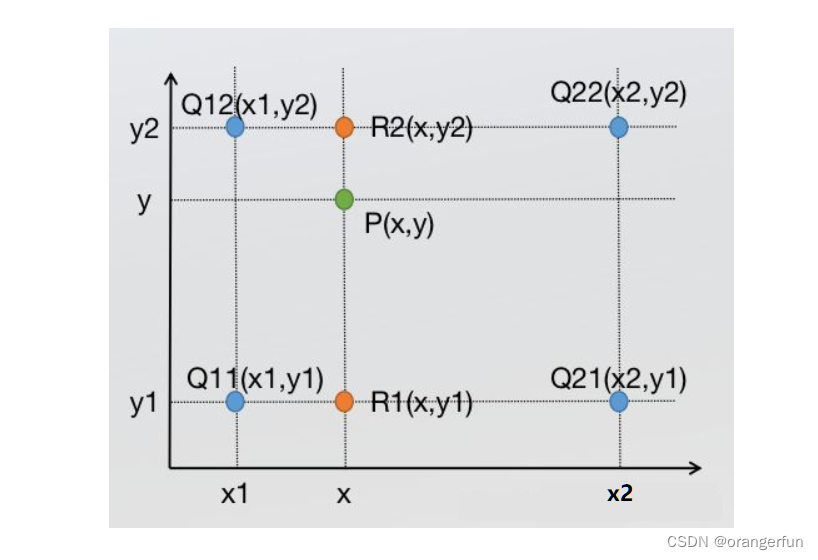
双线性插值是分别在两个方向计算了共3次单线性插值,如图所示,先在
x
x
x方向求2次单线性插值,获得
R
1
(
x
,
y
1
)
R_1(x, y_1)
R1(x,y1)、
R
2
(
x
,
y
2
)
R_2(x, y_2)
R2(x,y2)两个临时点,再在
y
y
y方向计算1次单线性插值得出
P
(
x
,
y
)
P(x, y)
P(x,y)(实际上调换2次轴的方向先y后x也是一样的结果)
具体可以参考:一篇文章为你讲透双线性插值
双线性插值不需要学习,运行速度快,操作简单
(2)反卷积
为了还原原有特征图,类似消除原有卷积的某种效果,所以叫反卷积,具体参考上一章节
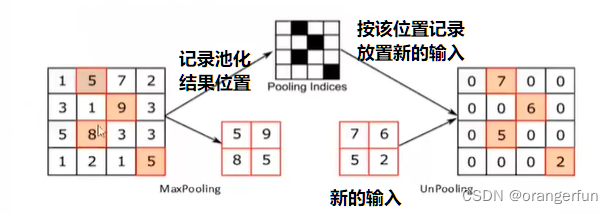
(3)反池化
在池化过程中记录下池化后元素在对应kernel中的坐标,作为反池化索引。
- 记录池化的位置,形成池化索引
- 将输入特征按记录位置摆放回去
反池化和反卷积的区别: - 最大区别在于反卷积过程是有参数要学习
- 理论上只要卷积核参数设置合理,反卷积可以实现反池化
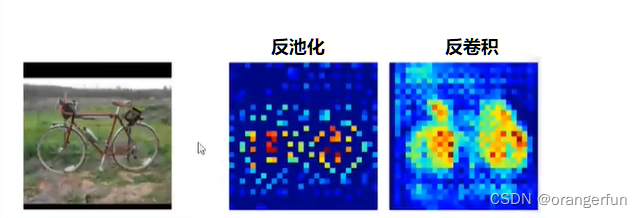
1.6 跳层结构 Skip Layer
原因
直接用32倍反卷积得到的分割结果粗糙
FCN-跳层结构
如下图所示,

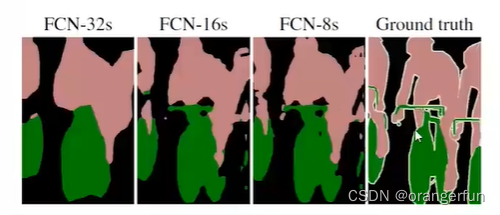
2. FCN架构

反卷积层:
- 最后一层反卷积层固定为双线性插值,不做学习
- 剩余反卷积层初始化为双线性插值,做学习
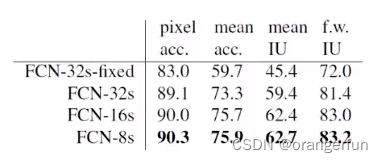
FCN性能
3. DeepLab-v1
3.1 改进点
- 基本结构:优化后的CNN+传统的CRF图模型
- 新的上采样卷积方案:带孔结构的空洞卷积(Atrous/Dilated convolution)
- 边界分割优化:使用全连接条件随机场CRF进行迭代优化;CNN输出粗糙的分割结果,全连接CRF精化分割结果
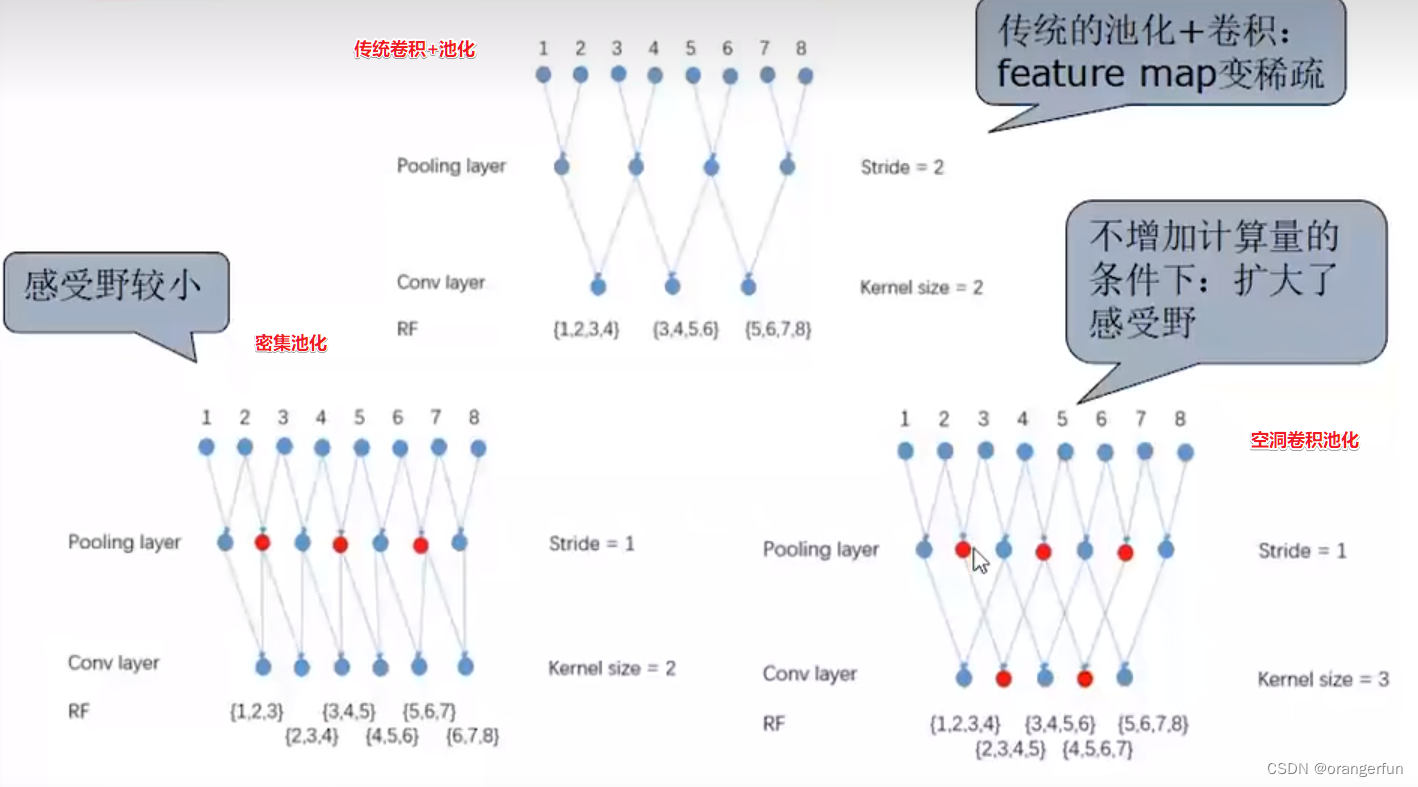
3.2 空洞卷积(Atrous/Dilated convolution)
其计算卷积过程如下图所示

有一个rate参数,rate越大,感受野越大,注意:中间有多少空洞,外部就要进行等量的padding
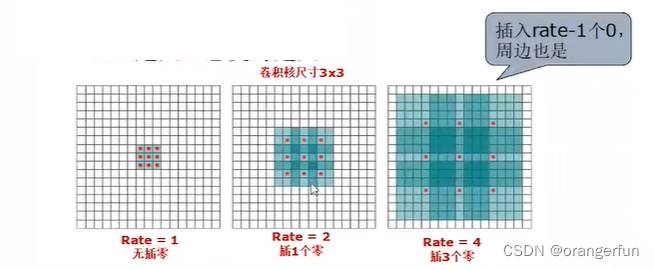
传统卷积+池化与空洞卷积对比

4. U-Net
U-Net的整体结构如下图所示, U-Net是一种用于生物影像分割的深度学习模型,他是一个全卷积网络,输入输出都是图像,没有全连接层

TODO
















 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









