







2023年2月17日
配置与环境
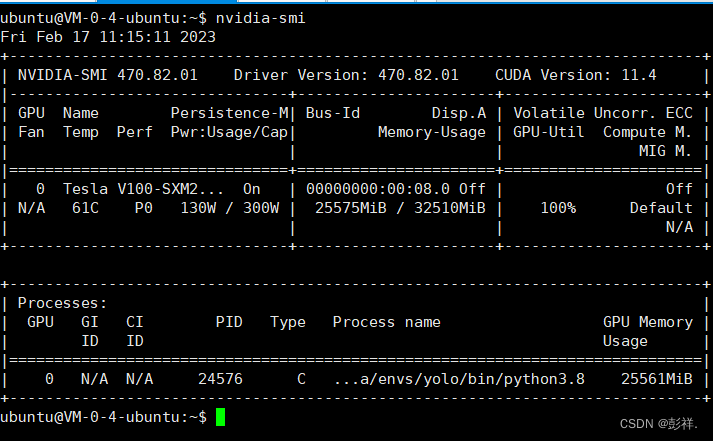
CPU:Intel® Xeon® Gold 6133 CPU @ 2.50GHz x8
GPU:NVIDIA Tesla V100 32G显存
python 3.8 pytorch1.12.1 cuda11.4 cuDNN 8.2.1
训练配置信息
输入图像尺寸:1280x1024
预训练模型:无
训练epoch:800
batch-size:24
优化器:adam
学习率下降策略:cos
cos下降策略到最后一步迭代的最后时,系数刚好为cos(pi/2),即为0,开始迭代时系数为为cos(0),即为1,中间遵循余弦曲线的方式下降。
lr = args.lr * (1 + cos(pi * (current_iter - warmup_iter) / (max_iter - warmup_iter))) / 2
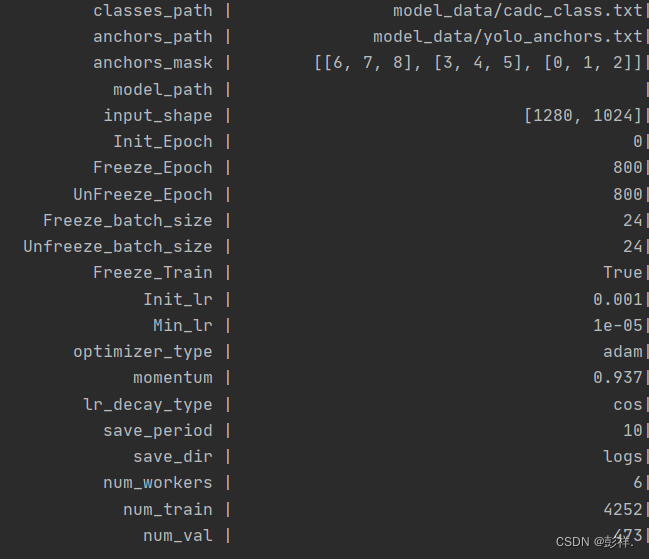
GPU使用状况:
最终结果,在训练到低180轮次后被手动终止,原因为130轮次后loss便不再下降,出现震荡状况。
2023年2月17日晚
今天对CADC数据集进行了处理,将一些不符合规范的标注进行修改,并再次投入应用,从0开始训练,包含主干网络参数。
此时训练对显存需求增大,batch-size只能设置为12才堪堪够用。
后续在训练中是否会出现爆显存问题还未可知,祈祷不要出问题吧,睡觉去喽,明早再说。
2023年2月19日早
模型逐渐收敛。验证集的loss逐渐稳定,原设定训练600轮次,在400次时便不再有明显变化。
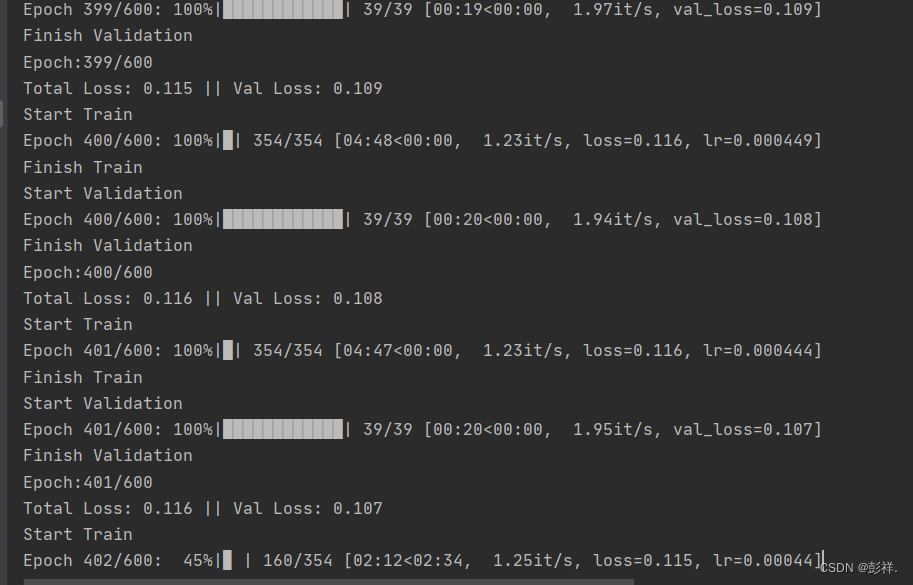
2023年2月19日晚
训练了近500次了,原本设定训练epoch为600,但此时其loss已经没有明显的变化,便将其提前终止了。
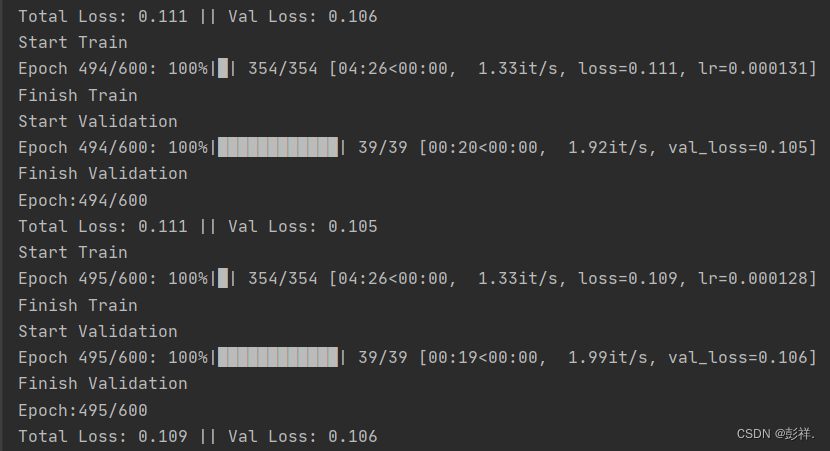
进行测试,计算mAP值
很遗憾,尽管对数据集重新做了标注,但效果并没有提升很多,将我们的预测结果在图片上打印出:
可以看出其准确度还是有的,但其召回率太低,很多物体都没检测出,博主这里将lou设置为0.5,置信度设置为0.5,理论上该数值算是较为正常的,想是否是由于远距离导致目标尺寸变小导致的呢?


2023年2月19日
考虑到是否是模型问题,将模型进行修改并再次开始训练,此次没有从0开始训练,而是使用了预训练权重,并设置batch-size=24,epoch=600
















 1354
1354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











