






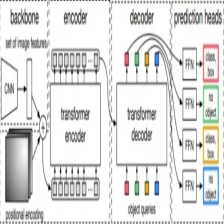
前言
自DETR提出之后,不计其数的DETR改进模型不断被提出,尽管如此,基于Transformer模型的速度与精度却一直被人诟病。今天学习的这个DETR的改进模型,号称SOTA模型,这便是大名鼎鼎的DINO-DETR模型。
该模型声称在COCO数据上测试的mAP值达到了0.63,可谓是不同凡响。
实验过程
博主也做了相关的实验,论文中提到DINO-DETR模型收敛极快,这个的确显而易见,考虑到COCO数据集太大,所以博主提取了bus,car,truck三个类别数据进行实验,其在训练过程中,在第一个epoch时效果还并不好,而第二个epoch时竟然mAP达到了0.26,这属实让我大为震惊,正当我以为其能够继续高歌猛进,达到其论文中的效果时,其最终的结果却让我有些失望,其最终的mAP值仅为0.28,而论文中指出其在12个epoch时便能达到0.49,在24个epoch时能到达0.52,这与我现在的结果差距属实巨大:
训练结果
使用预训练模型
博主的实验结果:本次实验中使用了官方提供的预训练模型进行微调实验。
epochs=24,batch-size=2


未使用预训练模型
作者在论文这指出,在仅使用resnet预训练模型的情况下,训练12epoch,模型的AP值可以达到0.49,在训练24epoch时,AP值达到50.4,因此博主打算验证这一结论,由于本次分配的服务器的显存小了几十M,导致自己的batch-size只能调整为1,设置epoch=24,进行实验:可以看到最终的AP值为0.25,而在12epoch时为0.23。



随后在同学的提示下,意识到在修改了batch-size的情况下,lr也要进行相应的调整,故
考虑到自己的数据集在经过提取后其数量已经急剧下降,效果差些也就情有可原,但目前两者毕竟差距太过巨大。因此便打算使用完整数据集进行实验。但让我想不通的是,博主的数据集并非是直接减少,而是按照不同类别进行提取,对于某个类别而言,其不该有如此大的差距。
验证结果
因此便想到使用论文中给出的已经训练好的模型文件进行验证:
在验证的过程中,博主也发现,先前的loss值最多只能下降到6.2便不再下降,而在使用论文中提供的权重文件时,其可以下降到3.1左右,这倒是令我感到意外。
最终通过验证集最后的结果为:可以看到的确如论文中所言,其达到了0.49。

原因分析
数据集标注问题
目前来看,关于实验结果差距大的问题可能原因为:
1.博主的类别提取方法有问题,提取的数据集有问题(太可怕了)
关于该问题,博主考虑到可以将COCO数据集中的标注信息打印到图片上进行验证:提取代码如下:
import json
import shutil
import cv2
def select(json_path, outpath, image_path):
json_file = open(json_path)
infos = json.load(json_file)
images = infos["images"]
annos = infos["annotations"]
assert len(images) == len(images)
for i in range(len(images)):
im_id = images[i]["id"]
im_path = image_path + "/" + images[i]["file_name"]
img = cv2.imread(im_path)
for j in range(len(annos)):
if annos[j]["image_id"] == im_id:
x, y, w, h = annos[j]["bbox"]
x, y, w, h = int(x), int(y), int(w), int(h)
x2, y2 = x + w, y + h
# object_name = annos[j][""]
img = cv2.rectangle(img, (x, y), (x2, y2), (255, 0, 0), thickness=2)
img_name = outpath + "/" + images[i]["file_name"]
cv2.imwrite(img_name, img)
# continue
print(i)
if __name__ == "__main__":
json_path = "/data/datasets/coco_type/annotations/instances_val2017.json"#放标注json的地址
out_path = "/data/datasets/coco_type/results"#结果放的地址
image_path = "/data/datasets/coco_type/images/val2017/"#原图的地址
select(json_path, out_path, image_path)
输出结果:



从上面的标注结果来看,其标注的信息还是较为准确的。
数据集数量问题
2.按照目前对Transformer的研究来看,其效果一般在数据量及其庞大的情况下越好,因此博主虽然是按照类别进行提取了,但不可否认的是数据集数量大大缩水,所以导致了实验效果差。
验证时GPU使用情况

小插曲
在进行实验时,由于博主才COCO数据集中提取了3个类别(car,bus,truck),因此在配置文件中也要进行修改,其中num_classes为数据集中目标类别数量,博主将其设置为3时,出现报错:
cuda error:device-side assert triggered
起初,博主以为是cuda环境出现了问题,但转念一想在先前的实验中并未出现问题,随后在查阅了相关资料后,看到有人提到可能是数据集标签类别的问题,随后想到DETR类模型除了原始类别外还需要加一个背景类,所以此处的num_classes应为4,随后将其改为4后,成功运行。
结语
本实验主要为复现DINO在COCO数据集上的实验结果,考虑到原始COCO数据集数据量庞大,训练时间长等问题,故从中提取了3个类别的样本进行实验,分别验证了不使用预训练模型与使用预训练模型时DINO在新建数据集上的性能。
关于当前实验结果分析与改进,博主还在进行中,如果大家有自己的观点,望不吝赐教。感谢!
















 9857
9857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











