






近日,第62届国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,简称 ACL)公布了论文录用结果。小米AI实验室大模型团队共有5篇最新研究成果中选ACL 2024,其中主会长文3篇,findings长文2篇,涵盖了AI Agent、端侧部署、复杂问题推理和预训练等方向。这是小米大模型部分研究成果的阶段性展示,同时也是践行小米科技战略中“深耕底层技术、长期持续投入”的又一例证。
ACL 年会是计算语言学和自然语言处理领域国际排名第一的顶级学术会议,由国际计算语言学协会组织,每年召开一次,在中国计算机学会(CCF)推荐会议列表中被列为 A 类会议。2024年是该会议的第62届,将于8月11日至16日在泰国曼谷举行。

论文简介
01
▍Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents
邓诗涵*,徐伟恺*,孙宏达*,刘伟,谭涛,刘剑锋,李昂,栾剑,王斌,严睿,商烁
【录用类型】
主会长文
【论文简介】
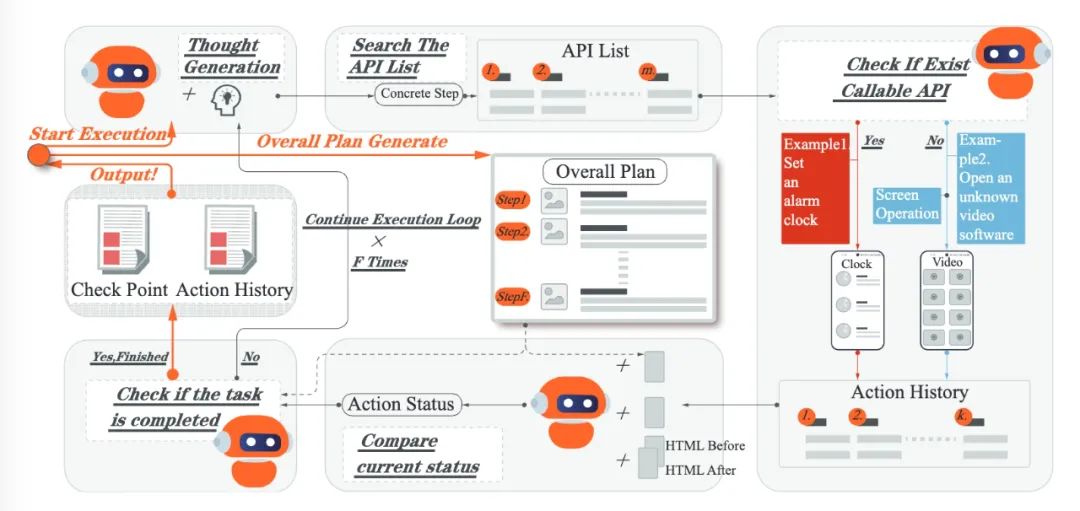
随着大语言模型(LLM)的飞速发展,基于LLM的智能体已成为人机交互领域的研究热点。然而,对基于手机操作系统的LLM智能体的研究,尤其是对于评估LLM手机智能体的benchmark依旧有所欠缺。LLM手机智能体的评估通常面临三个主要挑战:(1)UI 操作效率低,任务评估成本高;(2)单一应用程序中的简单指令不足以评估LLM手机智能体的多维推理和决策能力;(3)当前的自动评估指标无法准确评估LLM手机智能体的任务完成度。
为此,我们提出了 Mobile-Bench,一个全新的评估LLM手机智能体能力的Benchmark。首先,在常规的UI操作基础上,我们收集了103个手机操作系统的通用API指令,以此扩展LLM手机智能体的动作空间。其次,我们收集了来自线上真实用户的指令,也通过指导LLM生成一些模拟用户指令,并将两部分数据进行整合与质量筛选,构建了新的测试指令数据。最后,为了更好地评估手机智能体的不同级别的规划能力,评测数据集被分为三个子集:SAST、SAMT 和 MAMT,以反映不同级别任务的复杂性。Mobile-Bench 包含 832 个测试样例,以及 200 多个专门用于评估多 APP 协作场景的任务。此外,我们提出了一个新的自动指标 CheckPoint,以评估LLM手机智能体在其规划和推理步骤中是否包含关键步骤,CheckPoint的多角度评估能更精确地衡量LLM手机智能体的任务完成度。
02
▍DetermLR: Augmenting LLM-based Logical Reasoning from Indeterminacy to Determinacy
孙宏达*,徐伟恺*,刘伟,栾剑,王斌,商烁,文继荣,严睿
【录用类型】
主会长文
【论文简介】
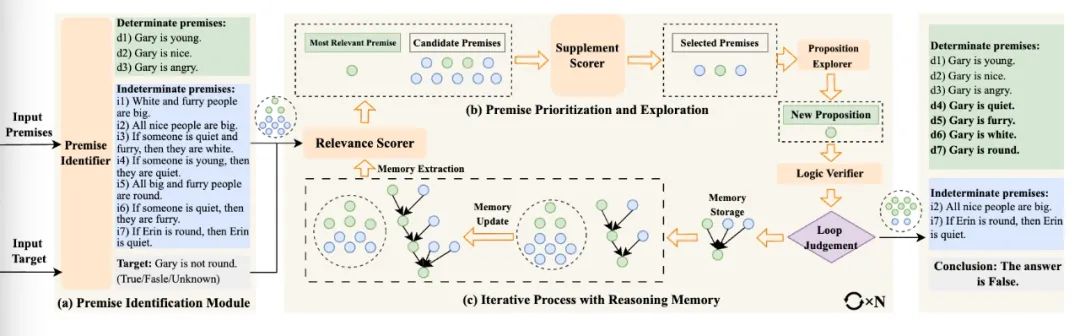
大型语言模型 (LLM) 的发展彻底改变了推理任务的格局。为了增强LLM模拟人类推理的能力,之前的研究主要集中在使用链、树或图等各种思维结构对推理步骤进行建模。然而,基于LLM的推理仍然遇到以下挑战:(1)事先预设推理结构对解决不同难度推理任务的适应性有限;(2)LLM通过整理已知条件来推导新条件的效果有待提升;(3)在多轮迭代推理过程中,后续推理步骤对先前推理经验的利用不足,导致相似推理错误的重复。
为此,我们提出了一种全新的大模型思维框架DetermLR,将推理过程建模为从不确定性到确定性的演变。首先,我们将已知条件划分为两种类型:确定前提和不确定前提,为推理过程提供总体方向,指导LLM将不确定信息逐渐向确定方向转化。随后,我们设计两阶段定量指标来对已知条件的优先级进行划分,以利用更相关、更有用的已知条件来推导新信息。此外,我们还开发一个推理记忆模块来自动存储和提取可用前提和推理路径,在迭代推理过程中保留关键历史推理细节。实验表明DetermLR在5个逻辑推理benchmark(LogiQA、ProofWriter、FOLIO、PrOntoQA 和 LogicalDeduction)上超越所有baseline推理方法。与之前的多步推理方法相比,DetermLR能以更少的推理步骤实现了更高的准确率,在解决逻辑推理任务方面展示了优越的效率和有效性。
【论文链接】
https://arxiv.org/abs/2310.18659
03
▍A Comprehensive Evaluation of Quantization Strategies for Large Language Models
金任任*,杜江村*,黄武伟,刘伟,栾剑,王斌,熊德意
【录用类型】
Findings长文
【论文简介】
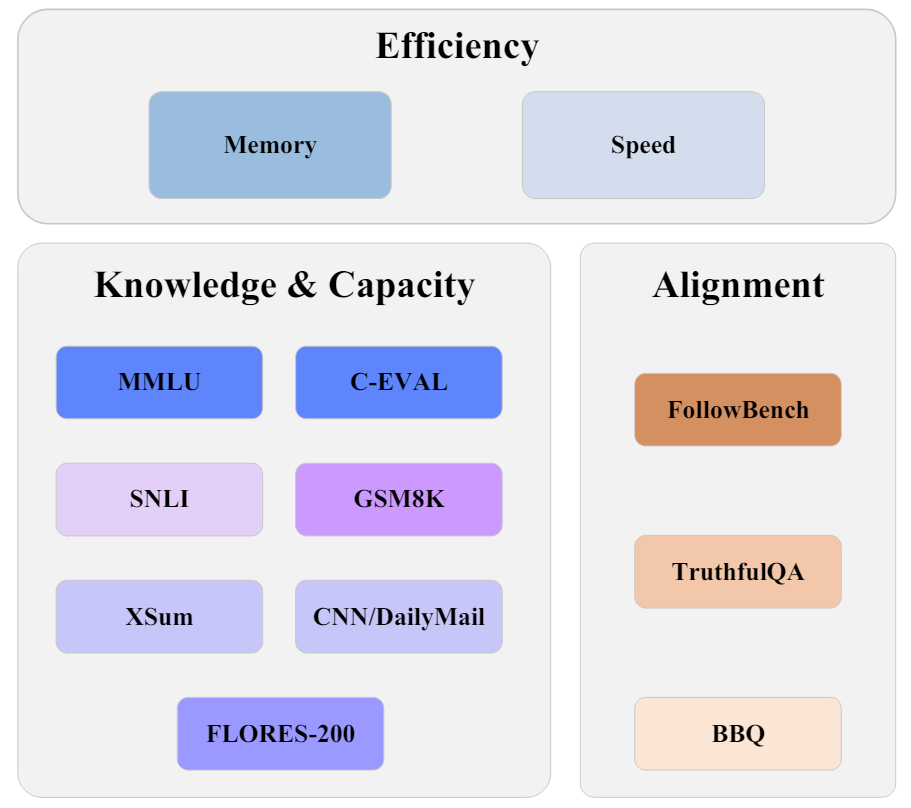
尽管增加大语言模型的参数规模通常能提升其在下游任务中的表现,但这也会增加模型在推理阶段的计算成本和内存(显存)开销,使得模型在资源有限的环境中难以部署。大模型量化是一种通过降低模型参数或激活值所占比特数的方法,能有效降低大模型在推理阶段的内存(显存)开销,以及加快模型的解码速度,因此大模型量化技术应用已变得越来越广泛。然而,大部分关于大模型量化的研究工作仅对预训练模型进行了量化实验,而量化对对齐模型的影响,以及perplexity与对齐模型在下游任务中表现之间的关系尚不明确。此外,现有的研究工作中,对量化后模型的评估往往局限于语言建模任务和少数分类任务,量化后的大模型在其他任务中的表现尚不清楚。
针对这些问题,我们提出了一个由知识和能力评测、对齐评测和效率评测这三个关键评测维度构成的结构化评测框架,并在10个不同的测试基准中进行了大量的实验。实验结果表明,与未量化的大模型相比,经过4bit量化的大模型通常能在下游任务中保持相当的表现,而且perplexity在一定程度上能反映大模型在大多数评测基准中的表现。此外,参数规模更大的模型经过量化后的表现可以超过参数规模较小的未量化模型。我们还发现,尽管量化可以降低模型的内存(显存)消耗,但它可能会降低模型的解码速度。因此,除了学术研究外,还需要付出大量的工程努力和相应的硬件支持,才能使得各种量化方法在降低大语言模型的内存(显存)消耗的同时加快模型的推理速度。
【论文链接】
https://arxiv.org/abs/2402.16775
04
▍Pruning Large Language Models to Intra-module Low-rank Structure with Transitional Activations
申博文,林政,查达仁,刘伟,栾剑,王斌,王伟平
【录用类型】
Findings长文
【论文简介】
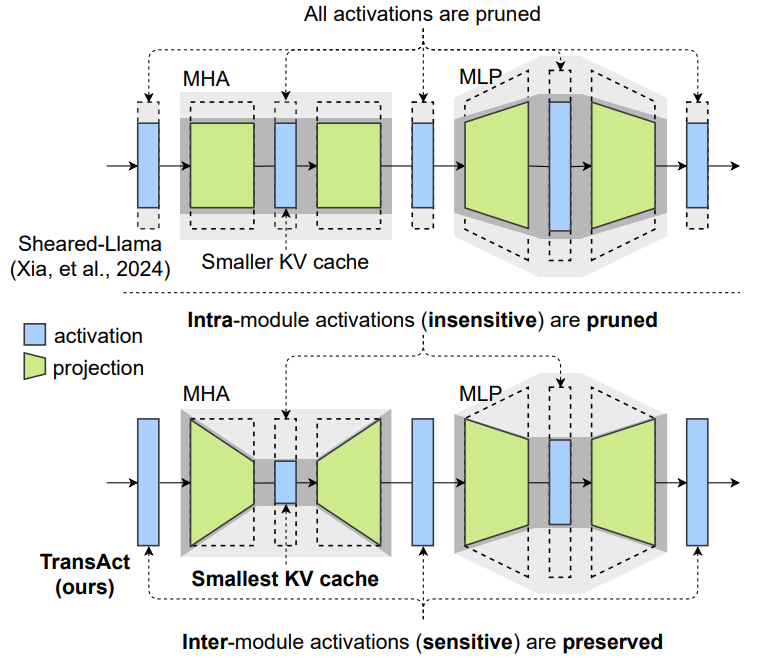
结构化剪枝能够减少大语言模型的计算和内存开销,为大模型的端侧部署提供可行的方案。结构化剪枝后得到的模型仍然是稠密和高精度的,更加容易进行端侧任务的定制和进一步压缩。然而,由于结构化剪枝粒度较粗,如何在大模型上同时实现高度压缩和较小的精度损失仍然是一个挑战。
为此,我们设计了轻量化大模型结构和与任务无关的大模型结构化剪枝方法 TransAct。针对 Transformer 结构中多头注意力(MHA)和多层感知器(MLP)两大主要模块,本方法以减小模块内隐藏层表征维度为目标,以隐藏层各神经元的激活值大小为依据,剪除激活值较小的神经元,形成类低秩表示的模块结构,同时保留 LayerNorm 等对扰动敏感的模块间隐藏表征维度。在参数量和效果相近的情况下,本方法的 KV Cache 压缩程度比 SOTA 方法高 30%。实验采用主流基座模型,并部署在小米 14 手机上,基准下游任务的评测结果验证了本方法在效率和效果上的优势。此外,消融实验证明了迭代式剪枝相较于单步剪枝的优势,并为大模型中 MHA 和 MLP 模块的冗余性提供了实验分析。
05
▍Analysing The Impact of Sequence Composition on Language Model Pre-Training
赵宇, 屈原斌, Konrad Staniszewski, Szymon Tworkowski, 刘伟, Piotr Miłoś, Yuxiang Wu, Pasquale Minervini
【录用类型】
主会长文
【论文简介】
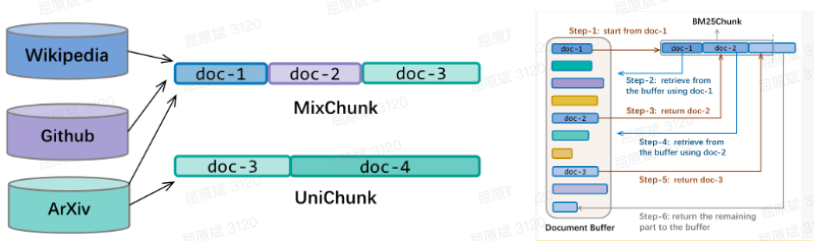
现有语言模型预训练框架通常将多个文档拼接成固定长度的序列,并使用因果掩码(causal masking)策略来通过给定上下文计算每个token的生成概率;这一策略因其简单高效而被广泛采用。然而,到目前为止,预训练数据序列的组合策略对模型泛化特性的影响仍未得到充分探索。
在本项工作中,我们发现因果掩码策略使得模型在预训练过程中会受到先前文档无关信息的影响,从而对语言建模和下游任务上的性能产生负面影响。在文档内部因果掩码中,每个token的概率仅取决于同一文档中的上文信息,这消除了来自之前无关文档的潜在干扰信息,并显著地提高了模型性能。此外,我们发现将关联文档拼接可以减少预训练过程中的一些潜在干扰,并且我们提出的基于检索的高效序列构建方法Bm25Chunk可以在不牺牲效率的情况下提高语言模型的上下文学习(in-context learning)(+11.6%)、知识记忆(+9.8%)和上下文利用(context utilisation)(+7.2%)能力。
【论文链接】
https://arxiv.org/abs/2402.13991
小米大模型介绍
作为首家把 AI 放在指数位置的科技公司,小米将包括大模型在内的 AI 技术看作一种生产力,将AI真正镶嵌在业务与产品中,为生产、生活赋能。2023年8月,小米宣布集团科技战略升级,坚持“选择对人类文明有长期价值的技术领域,长期持续投入”的科技理念,与“深耕底层技术、长期持续投入,软硬深度融合,AI全面赋能”这四个关键路径与原则,并总结为一个公式:(软件×硬件)ᴬᴵ。

AI大模型作为一种先进的人工智能技术,具有巨大的潜力和前景。小米大模型以轻量化和本地部署为突破口,去年8月,小米自研13亿参数的端侧模型在手机端跑通,部分场景效果可与云端大模型媲美,这一创新成果也在去年8月发布会上精彩亮相。之后,在2023高通骁龙峰会上,小米首次对外展示了小米端侧大模型的又一技术进展。在全新高通骁龙 8 Gen 3 终端上,基于 NPU 运行了小米自研 60 亿参数语言大模型,在首词响应、生成速度等几项关键指标上均处于行业领先水平。
小米大模型团队成立于去年4月。经过对效果、效率与使用成本的权衡,以及对软硬结合、生态连结等各因素的考量,选择“轻量化、本地部署”方向,并将大模型能力下放到端侧,这不仅能更有效地保护用户隐私,还为在本地实现千人千面的个性化定制提供了可能。

历经一年多的打磨,小米大语言模型已形成包括多种参数规模和形态的模型矩阵。既通过小米澎湃OS系统和人工智能助手小爱同学落地C端产品,也在集团内进行开源,为生产、销售、客服及员工工作提效等各环节赋能。
2024年5月,小米大语言模型通过生成式人工智能服务备案。通过备案后,小米大模型将逐步应用于小米公司的汽车、手机、智能家居等产品中,通过端云结合,既带来单个设备的智能提升,也实现场景内和场景间多设备的协同,为「人车家全生态」战略赋能。给予用户更加个性化的智能体验,让全球每个人都能享受大模型带来的美好生活。

END



















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









