






前言
滚动轴承是旋转机械的关键部件,其剩余使用寿命(RUL)预测是构建基于状态维护(CBM)系统的关键问题。然而,目前数据驱动的轴承RUL预测方法仍然需要先验知识来提取特征、构建健康指示(HI)和设置阈值,这在大数据时代是低效的。本文提出了一种基于数据驱动的轴承RUL预测方法。该方法包括特征提取、HI预测和RUL计算三个步骤。第一步,提取频谱的5个带通能值作为特征。在此基础上,提出了一种基于加注意机制的编码器-解码器框架的递归神经网络来预测与RUL值密切相关的HI值。最后,通过线性回归得到最终的RUL值。在PHM2012的数据集上进行的实验。从垂直和水平振动信号中分别获得10个特征值;通过线性回归计算RUL。
参考论文《A novel deep learning method based on attention mechanism for bearing remaining useful life prediction》
一、模型介绍
Encoder(编码器):
使用一维卷积层(nn.Conv1d)对输入序列进行特征提取,这有助于捕获局部特征,相比于RNN,可能在处理长序列时更高效。
随后是一个双向GRU(nn.GRU)层,用于捕捉序列中的长期依赖关系。双向意味着它同时考虑过去和未来的上下文信息。
编码器输出和隐藏状态被进一步用于解码阶段。
Attention(注意力层):
计算解码器当前状态与所有编码器输出之间的相关性分数,以便动态地确定哪些部分的输入序列对于预测当前输出最为重要。
这里使用的是加性注意力机制,通过一个全连接层(nn.Sequential)和点积操作来计算能量分数,然后softmax归一化得到注意力权重。
Decoder(解码器):
包含一个自定义的注意力机制,该机制在每一步解码时都与编码器的输出交互,以获取上下文向量。
使用一个GRU单元处理带有注意力上下文的输入,并输出下一个时间步的预测。
输出层(nn.Linear)结合了GRU的输出和注意力上下文,产生最终的输出分布。
Seq2Seq(序列到序列模型):
整合编码器和解码器,管理它们之间的交互,并控制是否采用“教师强制”(teacher forcing)策略进行训练,即在生成下一个词时是否使用真实的下一个词作为输入还是使用模型自己的预测。

二、特征计算
均值 (mean): 计算每个样本在每个时间步的平均值。
均方根 (rms): 计算每个样本在每个时间步的均方根值,反映信号的强度。
峰度 (kur): 计算每个样本在每个时间步的峰度,衡量分布的尖峭程度或扁平程度。
偏度 (skew): 计算每个样本在每个时间步的偏度,描述分布的不对称性。
峰值到峰值 (p2p): 计算每个样本在每个时间步的最大值与最小值之差,反映信号的振幅范围。
方差 (var): 计算每个样本在每个时间步的方差,描述信号变化的离散程度。
脉冲指标 (imp): 衡量信号最大绝对值与平均绝对值的比例。
形状因子 (mar): 描述信号形状的一个指标,与信号的“尖锐度”有关。
形状系数 (sha): 衡量信号的均方根值与平均绝对值的比例,反映信号的能量分布。
平方均值 (smr): 平均的信号幅度的平方,另一种能量度量。
三、实验结果
MSE: 0.0382,
RMSE: 0.1955,
MAE: 0.1258,
R²: 0.3825
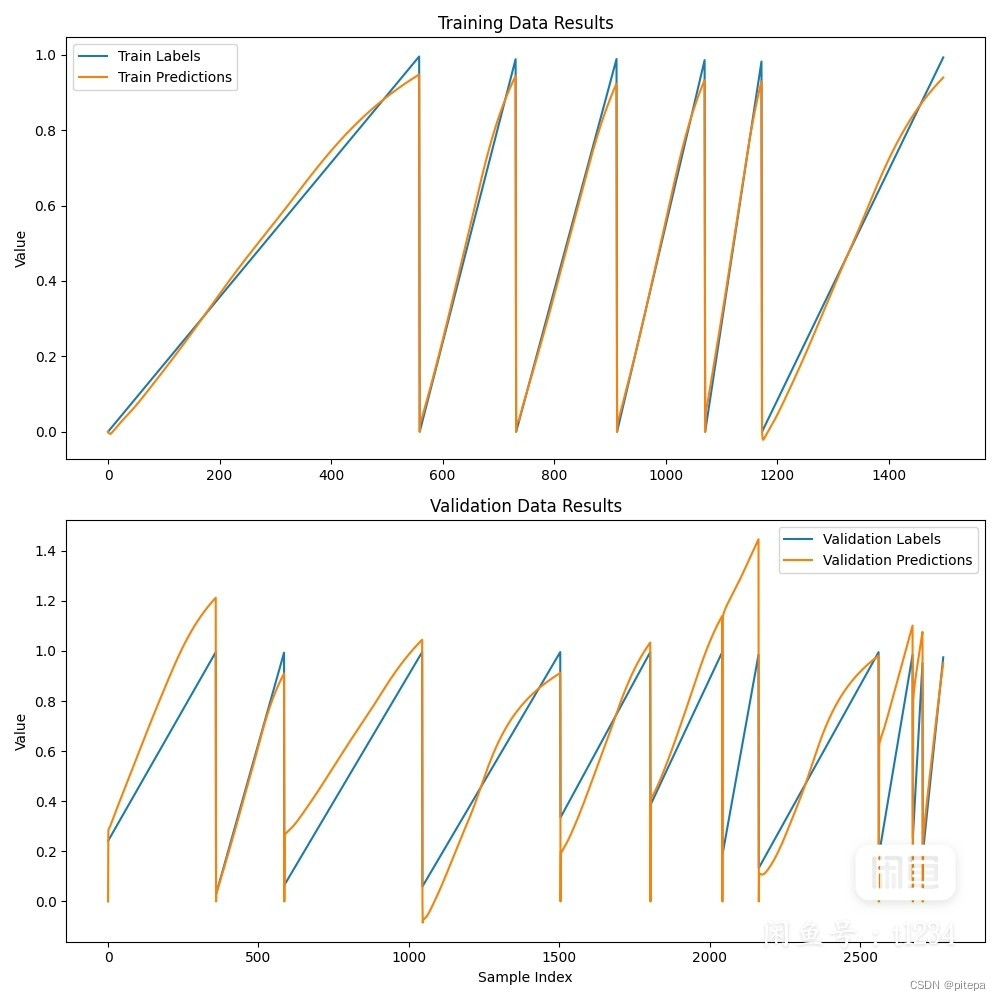

\




另外会把注意力数据提取到csv文件中,方便后续分析作图
提示:完整代码见某鱼:t1234
https://m.tb.cn/h.gdULssa?tk=TyPiWFx0H0a CZ0016
















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











