






昨天有小伙伴留言问我:问题来了,如何生成embedding呢?
这个问题很简单,可以直接问ChatGPT。即使是3.5的版本,也可以得到不错的回复:
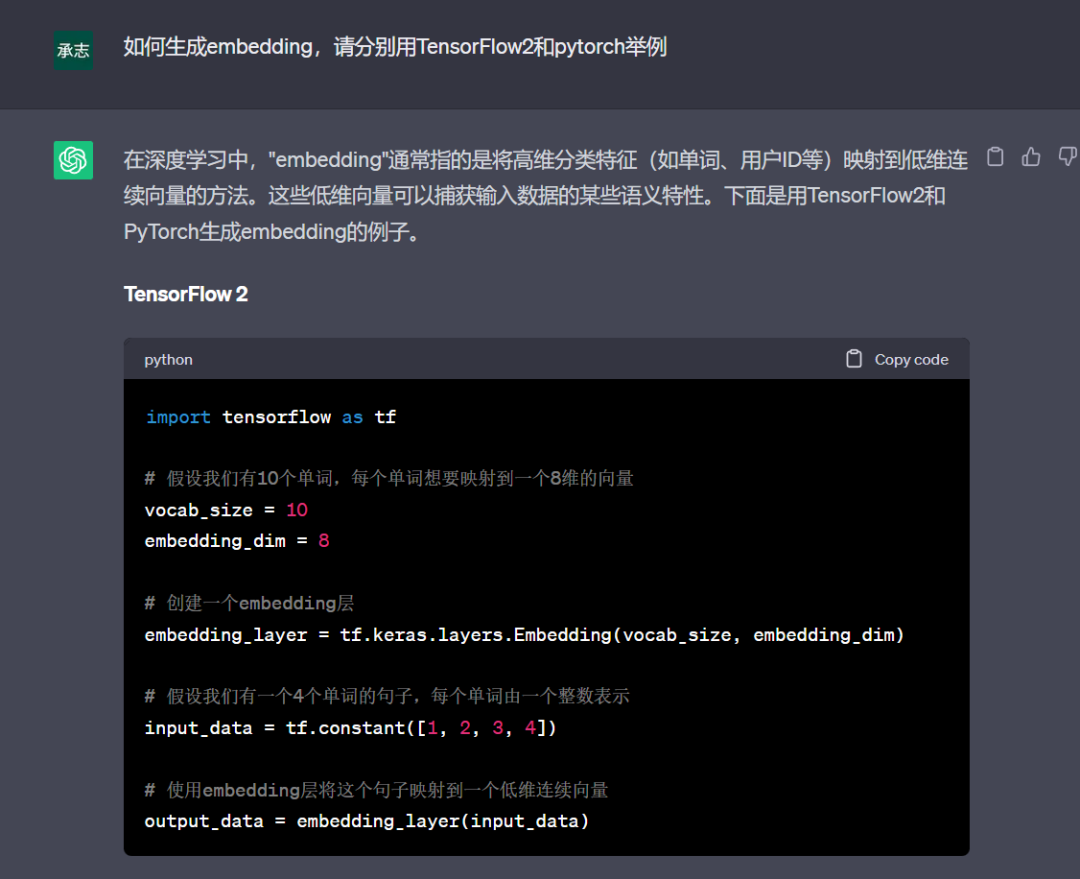
我这里贴一下它给出的代码,首先是TensorFlow2版本:
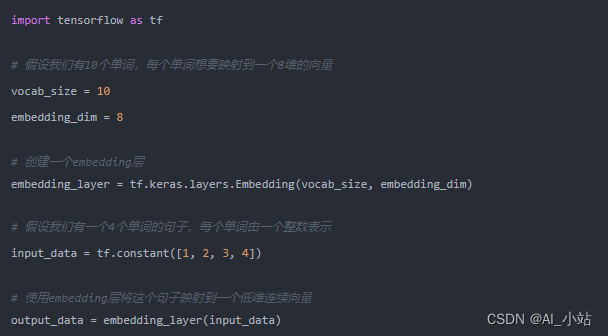
接着是pytorch版本:
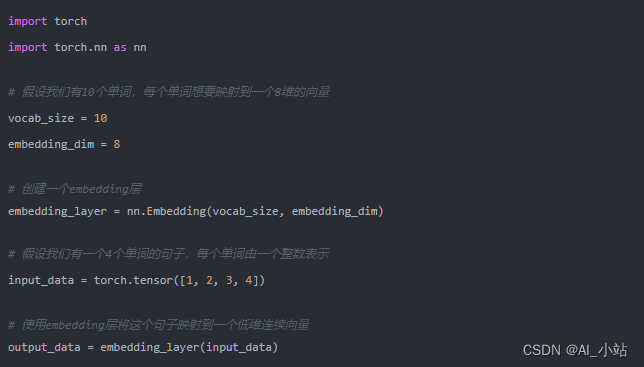
这两个版本的embedding创建过程大同小异,都有现成的api可以使用。传入的参数也类似,两个值,一个是vocab_size,表示的embedding的数量。简单理解就是你需要创建的embedding的值的数量,另外一个embedding_dim,表示的embedding的长度,也就是向量的长度。
这个api内部会生成一个二维的矩阵,这不是固定的,在一些问题当中也会有三维甚至更高维度的embedding池。只不过二维的embedding池更常见。
假设我们创建了之后的embedding池是这样的:
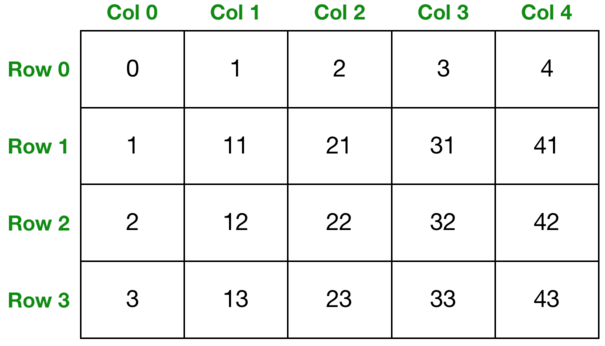
这里一共有四行,五列。对应到上面的参数,vocab_size就是4,embedding_dim则是5.
当我们要获取embedding的时候,传入的是下标,比如我们传入[1],那么会得到向量[1, 11, 21, 31, 41]。我们也可以传入多个下标,这样得到的就是多个embedding组成的矩阵。比如我们传入[0, 3],那么就会得到[[0, 1, 2, 3, 4], [3, 13, 23, 33, 43]]。
原理我们讲完了,接下来来分析问题。
最大的问题是embedding的数量是固定的,当我们遇到了没有出现过的下标的时候,该怎么办?
比如训练样本当中某个值最多只有10个,我们使用了大小10的embedding池。然而在预测的时候,突然遇到了没出现过的取值,这个时候该怎么办?
我们肯定是不可能放任这种情况不管的,因为这会让模型报错崩溃,得不到任何结果。
比较常用的办法是专门设置一个embedding作为默认情况,当出现之前没有出现过的值的时候,就用默认值来代替。比如我们可以把下标0空出来,然后将训练样本中出现比较稀疏的值都映射到0上,这样假如我们在预测的时候遇到了之前没有出现过的取值的时候,就使用0来代替。
由于模型在训练的时候,0就起到了默认值的作用,因此即使碰到了训练样本中没有出现过的离群值也不会太影响模型的效果。
另外一种方法当然是事先预留buffer,将embedding的大小设置得较大一些。这样即使遇到了个别离群值,也不会让模型崩溃。但embedding池的大小并不是随意设置的,这是需要消耗存储的。尤其是如果我们使用GPU作为训练的话,那么显存是非常有限的。如果embedding池过大,会导致显存不够,所以并不是越大越好的。
第二个问题就是稀疏性,在涉及到频率的问题上,28定律非常常见。可能20%的embedding占据了训练样本的80%,这就导致了会有很大一部分embedding非常稀疏,在训练样本中出现次数极少。
以电商场景举例,有一些id特征是非常稀疏的,比如商品id,用户id等。动辄上亿甚至数十亿,而其中大量都是非常低频的,只有少量极其高频。比如大促时的一些爆款商品,可能占到总体订单的10%甚至更多。这就导致了即使不考虑显存的问题,这些大量且低频的embedding由于在样本中出现次数太少,没有办法学习到一个很好的表达。
这个问题也是业界难题,据我所知暂时还没有特别好的办法。在工业场景当中,一个广泛使用的方法是共享embedding。也就是说我们把embedding数量设置得远小于特征的取值数量,比如上亿的商品id,我们只使用十万级的embedding来表达。通过哈希的方法,让一些不同的id映射到同一个向量上。
由于embedding共享,显然这会导致模型损失一些表达能力影响效果。但反过来说,这种做法一方面解决了显卡显存的问题,一方面让一些稀疏的特征值对应的embedding多少能学习到一定的表达,至少比初始化随机赋值的向量要好。
当然,如果财大气粗的话,这也不一定是问题。特征出现的频率稀疏就使用数据量来弥补,一周的数据不够就用一个月,一个月还不够就一年,往上堆数据直到够为止……当然这么大的embedding对显存会是一个很大的考验,肯定是不可能单机训练的,必须要使用分布式训练技术来优化。
由于GPU价格比较昂贵,国内很多大公司采用的是大量CPU集群的办法。比如某度的广告系统,就是用的大规模分布式,动辄成千上万台机器一起训练,不管你来多少embedding都能存的下……
ChatGPT使用大量样本,并且支持多种语言,内部的embedding数量肯定也是一个天文数字。我也很好奇openai在这个问题上有没有优化,我后面会读一读相关的论文看看能不能找到答案,有了进展再给大家分享。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









