






随着 AI 技术的发展,大家在日常使用过程中经常会碰到一些目前 GPT4 也无法解决的问题:
- 无法获取个人私有数据信息,进行智能问答
- 无法获取最新信息,LLM 模型训练都是都是有截止日期的
- 无法定制化私有的专属模型,从而在某个领域内取得更好效果
基于以上问题 OpenAI 官方提供了两种不同私有化模型定制方式:Fine-Tuning(微调)、Embedding(嵌入)。
一、Fine-Tuning 与 Embedding 区别
两种方式信息概括如下:
- Fine-Tuning(微调):在一个已经预训练好的模型的基础上,使用用户提供的数据进行进一步的训练,从而使模型更适合用户的特定应用场景。微调可以提高模型的质量、准确性和可靠性,以及降低请求的延迟和代价。微调需要用户准备和上传训练数据,以及选择合适的模型和参数。
- Embedding(嵌入):指将文本或其他内容转换为数值向量的形式,从而可以计算内容之间的相似度或相关性。OpenAI 的 Embedding 模型可以将文本解析为 1536 个维度,每个维度代表一个概念或特征。用户可以通过 Embedding 模型来存储、检索或比较文本或其他内容。Embedding 不需要用户提供训练数据,也不需要选择模型和参数。
Fine-Tuning 微调训练的成本较高,且自身需要一定的模型训练经验和一定规模的数据集,否则微调出来的模型效果并不会很理想。所以更推崇使用 Embedding 方式对数据进行处理从而达到预期效果,比如目前市面上智能客服完全可以通过 Embedding 实现落地。
二、Embedding 详细分析
接下来我们就来重点聊聊 Embedding ,它的大致流程是:
- 将已有数据集维护成对应的向量数据库
- 当用户通过 Prompt 进行提问时,从向量数据库提取相似或相近的信息
- 将信息连同 Prompt 一起发送给 GPT 模型来生成结果
这样做有一个好处就是我们只需要将相关的数据发送给 ChatGPT 即可,相对比较节约 Token。
Embedding 将数据转成成连续向量空间的过程,我们并不需要去深入了解。所以我们从 Embedding 如何识别相似或关联性数据讲起。
1. 如何从向量数据库提取相关数据?
从上面的概述我们可以了解到一个重点是:Embedding 模型需要将数据解析为 1536 个维度,每个维度代表一个概念或特征。
将一段文字转换成这么多个维度的数据,从向量数据库提取的过程中就是根据这些维度进行计算。
人类是如何辨别一个人,想象自己平时是如何认出谁是谁呢?我们都是通过外表容貌来认人的(如眼睛大小、鼻子大小、脸型、发型等等),对我们熟悉的人,我们的脑海中会记住他的五官、身材等关键信息。
映射到向量数据也是一样的道理,将数据的 1536 个维度认为是它的“五官”,当我们需要从向量数据库中提取数据时只需要找到“五官”相似的数据即可。
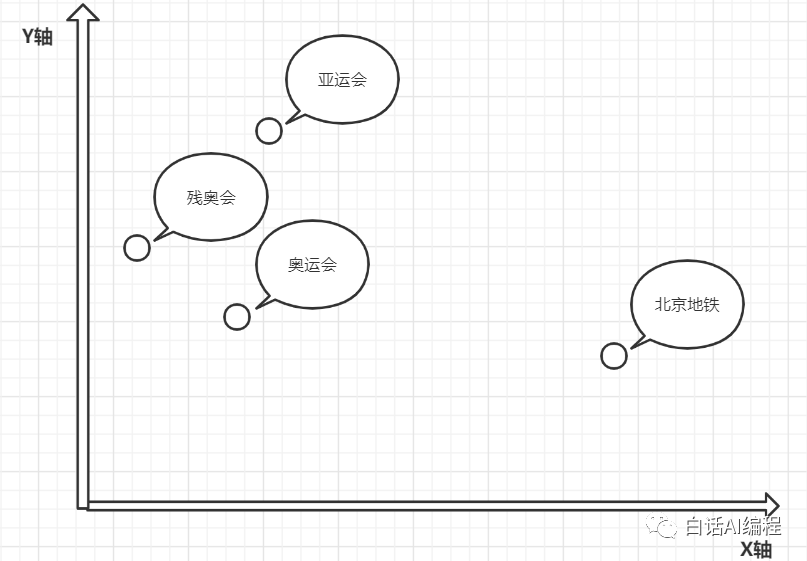
以如上二维坐标进行举例,相似或有关联性的向量数据就会分布在坐标系中比较临近的位置(奥运会、亚运会、残奥会),而内容基本不相干的向量数据(北京地铁)在坐标系中就会离得比较远。
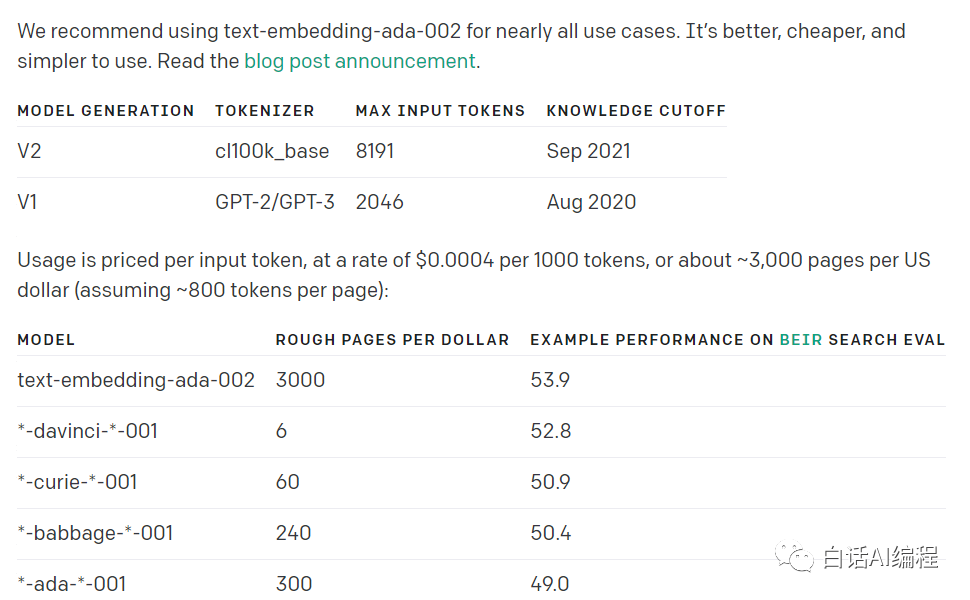
2. 使用 OpenAI 生成向量数据
通过 OpenAI 官网我们也可以看到,价格还是比较便宜的。使用量按每个输入令牌定价,收费为每1000个 tokens 大约0.0004美元。
通过 OpenAI 的 Embedding 方法调用,看看返回数据啥样。

接口返回了该文本对应的 1536 个维度数据,相当于我们已经掌握了这份文本数据的“五官”信息了。

3. 如何提取相似数据?
在上面的方法上使用余弦值来比较相似度,代码如下:
import openai
from sklearn.metrics.pairwise import cosine_similarity
openai.api_key = "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"
if __name__ == '__main__':
evaluate_one_text = "奥运会"
evaluate_two_text = "亚运会"
evaluate_three_text = "北京地铁"
# 对数据进行 embedding
embeddings = openai.Embedding.create(
model="text-embedding-ada-002",
input=[evaluate_one_text, evaluate_two_text, evaluate_three_text],
)
evaluate_one = embeddings["data"][0]["embedding"]
evaluate_two = embeddings["data"][1]["embedding"]
evaluate_three = embeddings["data"][2]["embedding"]
print("奥运会&亚运会的余弦距离:" + format(cosine_similarity([evaluate_one], [evaluate_two])[0][0]))
print("奥运会&北京地铁的余弦距离:" + format(cosine_similarity([evaluate_one], [evaluate_three])[0][0]))
print("北京地铁&亚运会的余弦距离:" + format(cosine_similarity([evaluate_three], [evaluate_two])[0][0]))
结果如下:
奥运会&亚运会的余弦距离:0.9022809359592784
奥运会&北京地铁的余弦距离:0.7898007980212471
北京地铁&亚运会的余弦距离:0.7767229785942393
计算两个数据的相似度,我们可以使用余弦相似度(cosine similarity)的方法,即计算两个向量之间的夹角的余弦值。余弦相似度的范围是[-1, 1],其中 1 表示完全相同,0表示正向相关性,-1表示完全相反。
通过这样一个简单的案例,我们就可以知道 OpenAI 是如何从向量数据库中提取到相似或相关联的数据。
结尾
本文主要讲解了 Embedding 的一些基本概念,后续会更新如何基于 Embedding 转换私人数据搭建私人客服。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









