






(1)📢 Ollama安装deepseek-r1:7b
deepseek模型大小根据个人电脑的配置选择,最好是大于1.5b。
Windows系统进入命令提示,通过ollama下载deepseek-r1:7b
cmd体验AI代码助手代码解读复制代码ollama run deepseek-r1:7b
(2)🎨 Ollama安装bge-m3:latest
bge-m3是一个向量模型,会将输入的汉字转换成向量。
Windows系统进入命令提示,通过ollama下载bge-m3:latest
cmd体验AI代码助手代码解读复制代码ollama run bge-m3:latest
以下是安装好的模型:

(3)🧊 安装向量数据库milvus
通过Docker安装向量数据库milvus,为了可视化操作数据库,还可以安装zilliz/attu
- 下载milvus安装脚本(单机模式)
linux体验AI代码助手代码解读复制代码curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
- 在此之前我们需要创建一个docker网络,zilliz/attu和milvus通信
linux体验AI代码助手代码解读复制代码# 自定义docker网络
docker network create icontainer
# 查看我们创建的docker网络
docker network ls
- 修改standalone_embed.sh,将docker run时的network指定为自定义的网络,下边是修改后的shell脚本
shell体验AI代码助手代码解读复制代码#!/usr/bin/env bash
# Licensed to the LF AI & Data foundation under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
run_embed() {
cat << EOF > embedEtcd.yaml
listen-client-urls: http://0.0.0.0:2379
advertise-client-urls: http://0.0.0.0:2379
quota-backend-bytes: 4294967296
auto-compaction-mode: revision
auto-compaction-retention: '1000'
EOF
cat << EOF > user.yaml
# Extra config to override default milvus.yaml
EOF
sudo docker run -d \
--name milvus-standalone \
--security-opt seccomp:unconfined \
--net=icontainer \
-e ETCD_USE_EMBED=true \
-e ETCD_DATA_DIR=/var/lib/milvus/etcd \
-e ETCD_CONFIG_PATH=/milvus/configs/embedEtcd.yaml \
-e COMMON_STORAGETYPE=local \
-v $(pwd)/volumes/milvus:/var/lib/milvus \
-v $(pwd)/embedEtcd.yaml:/milvus/configs/embedEtcd.yaml \
-v $(pwd)/user.yaml:/milvus/configs/user.yaml \
-p 19530:19530 \
-p 9091:9091 \
-p 2379:2379 \
--health-cmd="curl -f http://localhost:9091/healthz" \
--health-interval=30s \
--health-start-period=90s \
--health-timeout=20s \
--health-retries=3 \
milvusdb/milvus:v2.5.4 \
milvus run standalone 1> /dev/null
}
wait_for_milvus_running() {
echo "Wait for Milvus Starting..."
while true
do
res=`sudo docker ps|grep milvus-standalone|grep healthy|wc -l`
if [ $res -eq 1 ]
then
echo "Start successfully."
echo "To change the default Milvus configuration, add your settings to the user.yaml file and then restart the service."
break
fi
sleep 1
done
}
start() {
res=`sudo docker ps|grep milvus-standalone|grep healthy|wc -l`
if [ $res -eq 1 ]
then
echo "Milvus is running."
exit 0
fi
res=`sudo docker ps -a|grep milvus-standalone|wc -l`
if [ $res -eq 1 ]
then
sudo docker start milvus-standalone 1> /dev/null
else
run_embed
fi
if [ $? -ne 0 ]
then
echo "Start failed."
exit 1
fi
wait_for_milvus_running
}
stop() {
sudo docker stop milvus-standalone 1> /dev/null
if [ $? -ne 0 ]
then
echo "Stop failed."
exit 1
fi
echo "Stop successfully."
}
delete_container() {
res=`sudo docker ps|grep milvus-standalone|wc -l`
if [ $res -eq 1 ]
then
echo "Please stop Milvus service before delete."
exit 1
fi
sudo docker rm milvus-standalone 1> /dev/null
if [ $? -ne 0 ]
then
echo "Delete milvus container failed."
exit 1
fi
echo "Delete milvus container successfully."
}
delete() {
delete_container
sudo rm -rf $(pwd)/volumes
sudo rm -rf $(pwd)/embedEtcd.yaml
sudo rm -rf $(pwd)/user.yaml
echo "Delete successfully."
}
upgrade() {
read -p "Please confirm if you'd like to proceed with the upgrade. The default will be to the latest version. Confirm with 'y' for yes or 'n' for no. > " check
if [ "$check" == "y" ] ||[ "$check" == "Y" ];then
res=`sudo docker ps -a|grep milvus-standalone|wc -l`
if [ $res -eq 1 ]
then
stop
delete_container
fi
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed_latest.sh && \
bash standalone_embed_latest.sh start 1> /dev/null && \
echo "Upgrade successfully."
else
echo "Exit upgrade"
exit 0
fi
}
case $1 in
restart)
stop
start
;;
start)
start
;;
stop)
stop
;;
upgrade)
upgrade
;;
delete)
delete
;;
*)
echo "please use bash standalone_embed.sh restart|start|stop|upgrade|delete"
;;
esac
- 执行standalone_embed.sh脚本
linux体验AI代码助手代码解读复制代码./standalone_embed.sh start
- 下载zilliz/attu镜像
linux体验AI代码助手代码解读复制代码docker pull zilliz/attu:v2.5
- 启动zilliz/attu:v2.5,需要填写宿主机的ip
linux体验AI代码助手代码解读复制代码docker run -d -p 8000:3000 --net=icontainer -e MILVUS_URL=192.168.10.33:19530 zilliz/attu:v2.5
-
点击【连接】,进入控制台
-
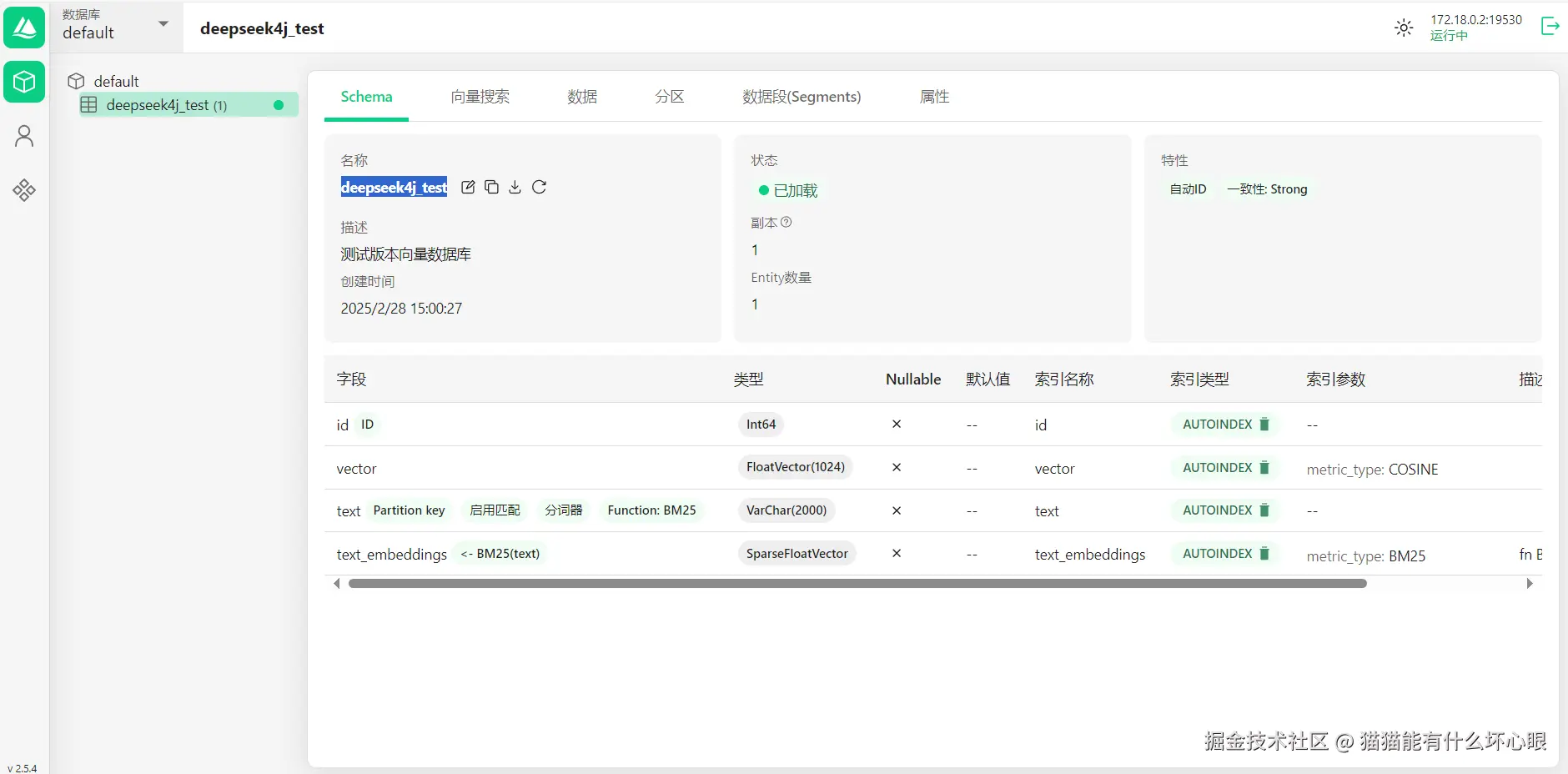
创建向量数据库,命名deepseek4j_test
(4)🚀 通过代码测试本地RAG的效果
通过SpringBoot3+JDK17搭建RAG项目
- 引入相关的maven依赖
maven体验AI代码助手代码解读复制代码<!-- pig提供的deepseek开源工具包 -->
<dependency>
<groupId>io.github.pig-mesh.ai</groupId>
<artifactId>deepseek-spring-boot-starter</artifactId>
<version>1.4.3</version>
</dependency>
<!-- 链接 milvus SDK-->
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.5.3</version>
</dependency>
- 配置yml文件,填写LLM大模型配置
java体验AI代码助手代码解读复制代码deepseek:
api-key: deepseek # 必填项:你的 API 密钥
model: deepseek-r1:7b
base-url: http://127.0.0.1:11434/v1 # 可选,默认为官方 API 地址
embedding:
api-key: embedding
model: bge-m3:latest
base-url: http://127.0.0.1:11434/v1
- 插入测试数据
我们需要向milvus数据库中插入数据
java体验AI代码助手代码解读复制代码@Autowired
EmbeddingClient embeddingClient;
@GetMapping(value = "/addMilvusData")
public void insert() {
// Connect to Milvus server
ConnectConfig connectConfig = ConnectConfig.builder()
.uri("http://192.168.10.33:19530") // 获取的 Milvus 链接端点
.serverName("deepseek4j_test")
.build();
MilvusClientV2 milvusClientV2 = new MilvusClientV2(connectConfig);
// 这里可以换成你自己的测试文件
String law = FileUtil.readString("C:\Users\14997\Desktop\code\Rag测试.txt", StandardCharsets.UTF_8);
String[] lawSplits = StrUtil.split(law, 400);
List<JsonObject> data = new ArrayList<>();
for (String lawSplit : lawSplits) {
List<Float> floatList = embeddingClient.embed(lawSplit);
JsonObject jsonObject = new JsonObject();
// 将 List<Float> 转换为 JsonArray
JsonArray jsonArray = new JsonArray();
for (Float value : floatList) {
jsonArray.add(value);
}
jsonObject.add("vector", jsonArray);
jsonObject.addProperty("text", lawSplit);
data.add(jsonObject);
}
InsertReq insertReq = InsertReq.builder()
.collectionName("deepseek4j_test")
.data(data)
.build();
milvusClientV2.insert(insertReq);
}
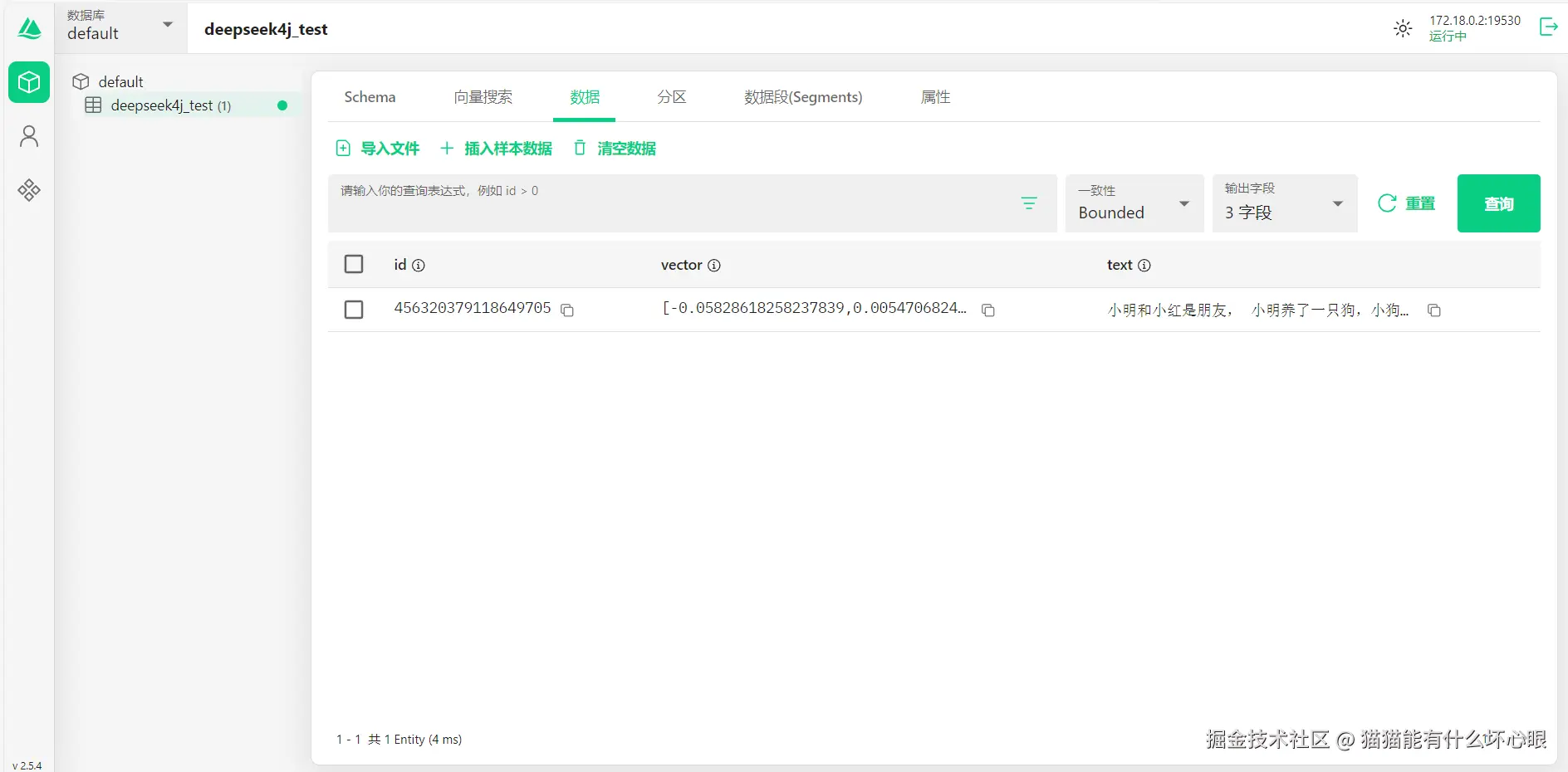
插入结果:
- 编写测试代码
java体验AI代码助手代码解读复制代码@Autowired
private DeepSeekClient deepSeekClient;
@Autowired
EmbeddingClient embeddingClient;
@GetMapping(value = "/chat2", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ChatCompletionResponse> chat2(HttpServletResponse response) {
// Connect to Milvus server
ConnectConfig connectConfig = ConnectConfig.builder()
.uri("http://192.168.10.33:19530") // 获取的 Milvus 链接端点
.serverName("deepseek4j_test")
.build();
String prompt = "小明的小狗叫什么?";
MilvusClientV2 milvusClientV2 = new MilvusClientV2(connectConfig);
List<Float> floatList = embeddingClient.embed(prompt);
SearchReq searchReq = SearchReq.builder()
.collectionName("deepseek4j_test")
.data(Collections.singletonList(new FloatVec(floatList)))
.outputFields(Collections.singletonList("text"))
.searchParams(Map.of("anns_field", "vector"))
.topK(3)
.build();
SearchResp searchResp = milvusClientV2.search(searchReq);
List<String> resultList = new ArrayList<>();
List<List<SearchResp.SearchResult>> searchResults = searchResp.getSearchResults();
for (List<SearchResp.SearchResult> results : searchResults) {
System.out.println("TopK results:");
for (SearchResp.SearchResult result : results) {
resultList.add(result.getEntity().get("text").toString());
}
}
ChatCompletionRequest request = ChatCompletionRequest.builder()
// 根据渠道模型名称动态修改这个参数
.model("deepseek-r1:7b")
.addUserMessage(String.format("你要根据用户输入的问题:%s \n \n 参考如下内容: %s \n\n 整理处理最终结果", prompt, resultList)).build();
response.setHeader(HttpHeaders.CONTENT_TYPE, MediaType.TEXT_PLAIN_VALUE + ";charset=UTF-8");
return deepSeekClient.chatFluxCompletion(request);
}
测试结果:小明的小狗叫米粒
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2097
2097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









