






RAG(Retrieval-Augmented Generation,检索增强生成)技术通过检索增强生成,显著提升了知识问答的准确性和时效性。在构建知识库时,RAG通过向量数据库和动态更新机制,实现了高效的知识检索与生成;在构建知识图谱时,RAG通过GraphRAG和Graphusion等框架,实现了实体关系的精准抽取与图谱融合。
一、RAG
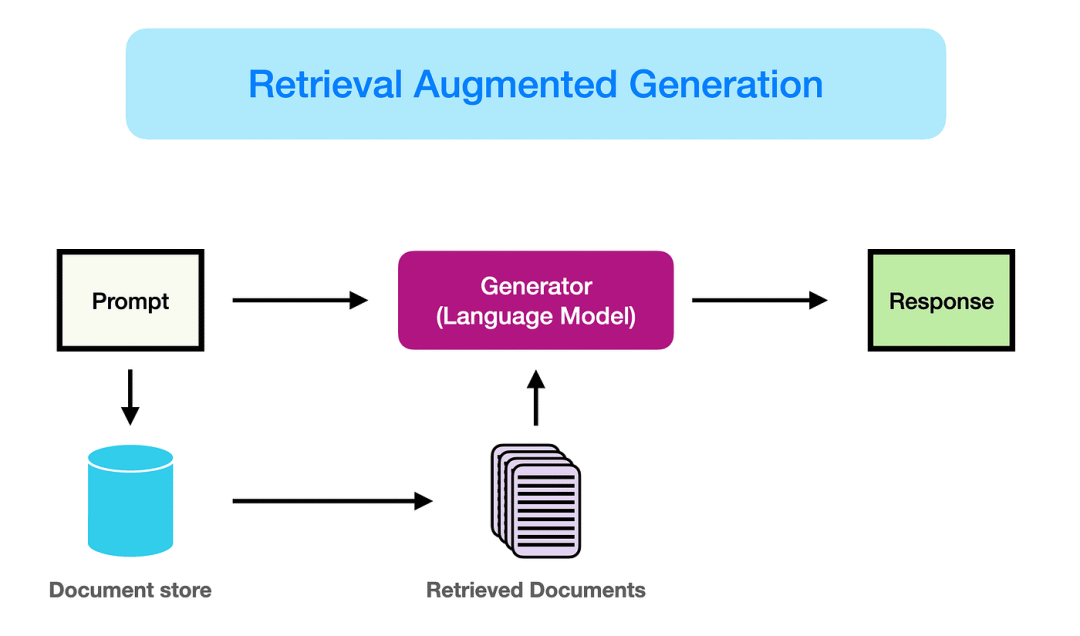
RAG(Retrieval-Augmented Generation,检索增强生成)是什么?RAG是一种结合信息检索与文本生成的人工智能技术,旨在通过引入外部知识库,解决大语言模型的幻觉问题。
RAG的核心目标是让大语言模型(LLM)在回答问题时不再仅依赖训练时的固化知识,而是动态检索最新或特定领域的资料来辅助生成答案。
RAG结合了信息检索与生成模型,通过以下三阶段工作:
-
检索:从外部知识库(如文档、数据库)中搜索与问题相关的信息。
-
增强:将检索结果作为上下文输入,辅助生成模型理解问题背景。
-
生成:基于检索内容和模型自身知识,生成连贯、准确的回答。
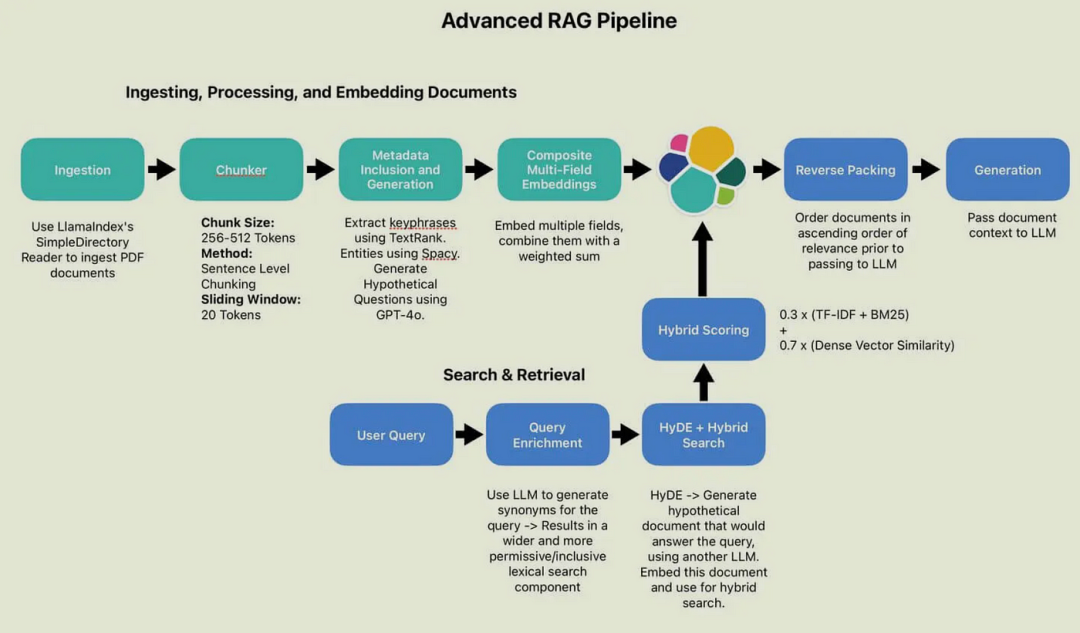
Prompt + RAG 如何实战?结合 Prompt 工程与 RAG(检索增强生成) 的实战应用需围绕数据准备、检索优化、生成控制等环节展开。
一、数据准备与向量化
1. 文档预处理与分块
文档预处理通过多模态数据清洗、词形还原与依存句法分析实现文本规范化;分块环节采用递归分割与语义边界识别技术,结合知识图谱关联优化,构建动态重叠的上下文连贯单元,以平衡检索效率与信息完整性。
# 依赖安装:pip install langchain langchain-text-splittersfrom langchain_text_splitters import RecursiveCharacterTextSplitter# 示例长文本(替换为实际文本)text = """自然语言处理(NLP)是人工智能领域的重要分支,涉及文本分析、机器翻译和情感分析等任务。分块技术可将长文本拆分为逻辑连贯的语义单元,便于后续处理。"""# 初始化递归分块器(块大小300字符,重叠50字符保持上下文)text_splitter = RecursiveCharacterTextSplitter(chunk_size=300,chunk_overlap=50,separators=["\n\n", "\n", "。", "!", "?"] # 优先按段落/句子分界[2,4](@ref))# 执行分块chunks = text_splitter.split_text(text)# 打印分块结果for i, chunk in enumerate(chunks):print(f"Chunk {i+1}:\n{chunk}\n{'-'*50}")
2. 向量化与存储
向量化通过Embedding模型将非结构化数据(文本、图像等)映射为高维语义向量,存储则依托专用向量数据库(如ElasticSearch的dense_vector字段、Milvus)构建高效索引(HNSW、FAISS),支持近似最近邻搜索(ANN)实现大规模向量数据的快速相似性匹配。
# 依赖安装:pip install sentence-transformers faiss-cpufrom sentence_transformers import SentenceTransformerfrom langchain_community.vectorstores import FAISS# 1. 文本向量化(使用MiniLM-L6预训练模型)model = SentenceTransformer('paraphrase-MiniLM-L6-v2')embeddings = model.encode(chunks)# 2. 向量存储到FAISS索引库vector_db = FAISS.from_texts(texts=chunks,embedding=embeddings,metadatas=[{"source": "web_data"}] * len(chunks) # 可添加元数据)# 保存索引到本地vector_db.save_local("my_vector_db")# 示例查询:检索相似文本query = "什么是自然语言处理?"query_embedding = model.encode([query])scores, indices = vector_db.similarity_search_with_score(query_embedding, k=3)print(f"Top 3相似块:{indices}")
二、检索优化技术
通过多路召回(如混合检索、HyDE改写、动态重排)提升查全率与排序质量,并利用上下文增强(知识图谱补充关系、指令级RAG动态生成Prompt)优化检索结果。
三、Prompt 工程实践
1. 结构化输入设计
基于角色和场景进行约束,例如法律顾问角色与合同条款咨询场景,结合《民法典》第580条知识单元,通过“用户问题→检索知识→逻辑关联→生成答案”的思维链,分点解释并标注引用来源。
2. 输出模版控制
通过预设模板化输出框架确保格式规范,并设置动态防护栏机制过滤敏感词与校验事实一致性,实现内容生成的安全性与合规性。
二、知识库和知识图谱
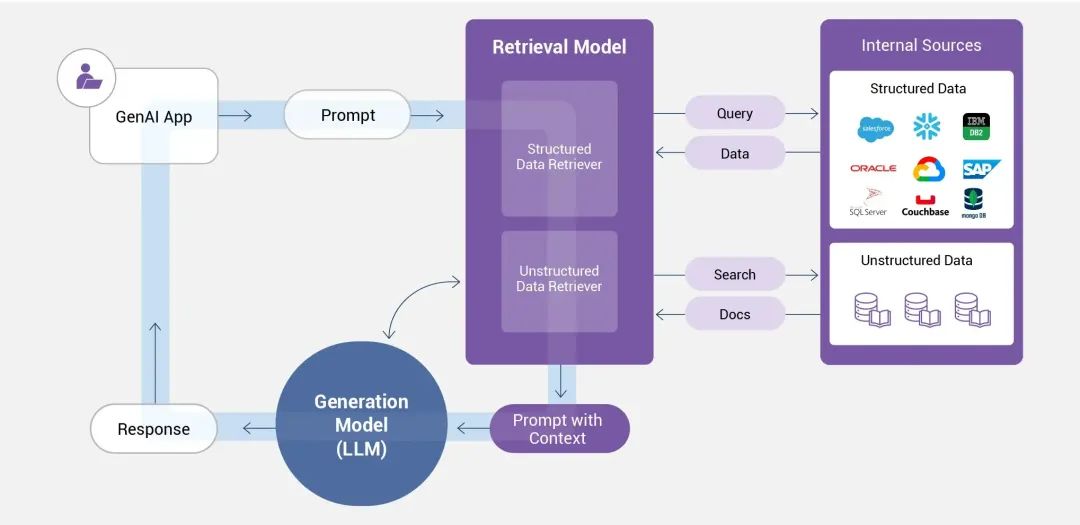
知识库(Knowledge Base)是什么?知识库是结构化、易操作的知识集群,通过系统性整合领域相关知识(如理论、事实、规则等),为问题求解、决策支持和知识共享提供基础平台。
RAG构建知识库的核心在于将外部知识检索与大语言模型生成能力结合,通过高效检索为生成提供上下文支持,从而提升答案的准确性和时效性。(实战的重点在文本分块Chunking和向量化Embedding)
1. 文本分块(Chunking)
文本分块是将长文本分割为较小、可管理的片段,以便更高效地处理和分析。
2. 向量化(Embedding)
向量化是将文本或数据映射为高维向量空间中的数值表示,以捕获语义特征。
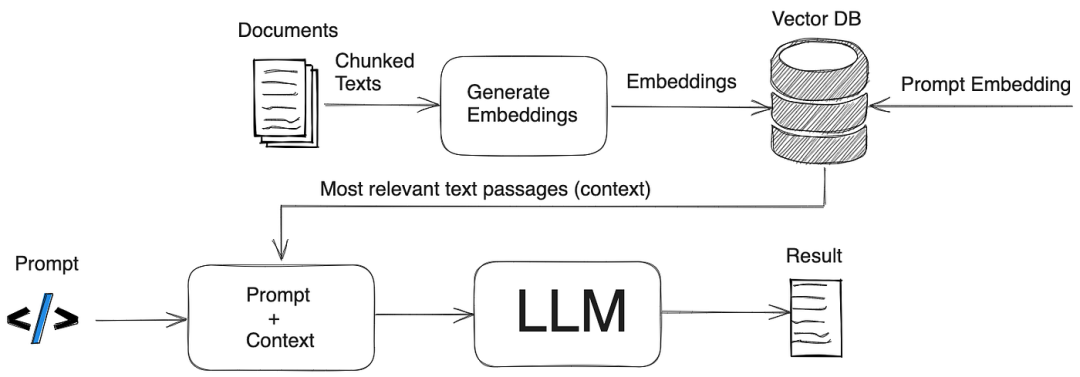
知识图谱(Knowledge Graph)是什么?知识图谱是一种通过实体与关系构建的语义化网络结构,支持推理与复杂查询,而传统知识库多以非关联的扁平化方式存储数据。
RAG构建知识图谱的核心是通过结合检索技术与大语言模型(LLM),将外部知识库中的结构化与非结构化数据整合为图谱形式。知识图谱为RAG系统注入结构化推理能力,使其从“信息检索器”进化为“知识推理引擎”。
RAG构建知识图谱的关键在于检索与生成的协同,其流程包括:
- 数据预处理:将文档分割为文本块(chunking),并通过命名实体识别(NER)提取实体与关系。
- 知识图谱索引:基于提取的实体与关系,构建初始知识图谱后,运用聚类算法(例如Leiden算法)对图谱中的节点进行社区划分。
- 检索增强:在用户查询时,通过本地搜索(基于实体)或全局搜索(基于数据集主题)增强上下文,提升生成答案的准确性。

如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









