







 “KinectFusion Real-Time Dense Surface Mapping and Tracking”一文于2012年发表,该文章首次实现了实时稠密重建(Real time dense restruction),我认为微软的Kinect深度相机是其成功的根本,该文章也是首次成功应用了深度相机,是做实时稠密重建(Real time dense restruction)方向的必读论文。
“KinectFusion Real-Time Dense Surface Mapping and Tracking”一文于2012年发表,该文章首次实现了实时稠密重建(Real time dense restruction),我认为微软的Kinect深度相机是其成功的根本,该文章也是首次成功应用了深度相机,是做实时稠密重建(Real time dense restruction)方向的必读论文。
“KinectFusion Real-Time Dense Surface Mapping and Tracking”一文于2012年发表,该文章首次实现了实时稠密重建(Real time dense restruction),我认为微软的Kinect深度相机是其成功的根本,该文章也是首次成功应用了深度相机,是做实时稠密重建(Real time dense restruction)方向的必读论文。
系统的主体结构如图所示:(摘自原文)
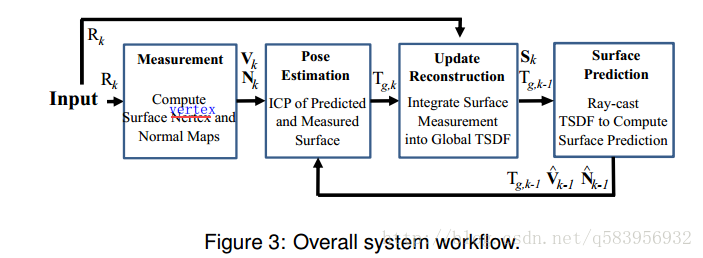
- 深度相机采集数据,对数据做预处理。(Surface measurement)
- 使用Prj ICP算法估计相机位姿。(Sensor pose estimation)
- 融合当前帧点云到模型。(Surface reconstruction update)
- 使用光线投射法(投影算法)将点云模型投影到下一帧相机位置的图像上供下一帧计算。(Surface prediction)
深度图像预处理(Surface measurement)
记从传感器获得的第 k 帧深度图像为
记 K 为相机的内参矩阵(Intrinsic matrix), u˙=[uT1]T 为 u 的齐次化向量。通过反投影法由 Dk 计算得到该帧的三维点云集合 Vk (其中每个点 Vk(u)∈R3 ):
*注1:双边滤波器可以参考双边滤波器的原理及实现一文。其作用是保留边界梯度的情况下,滤除高频噪声。
然后通过 Vk(u) 计算对应像素点 u 的法向量 Nk(u) :
由于深度图像并不是每个像素点都是有值的,如下图,深度图像中纯黑色的部分就是传感器无法采集深度的区域,原因可能是多种的:探测区域超出了传感器的探测范围、过于光滑的材质、能够吸收红外光的材质等。

因此,需要一个掩码矩阵 Mk 来表示该帧深度图像对应的位置是否有值。若对应像素 u 有值,则 Mk(u)=1 ,否则 Mk(u)=0 。
至此,得到了 Rk 与 Nk 以供后面的投影法 ICP使用。
相机位姿估计(Sensor pose estimation)
定义相机坐标系,取相机光心为原点,取相机光轴为 Z 轴,像素坐标轴 u 与相机坐标轴
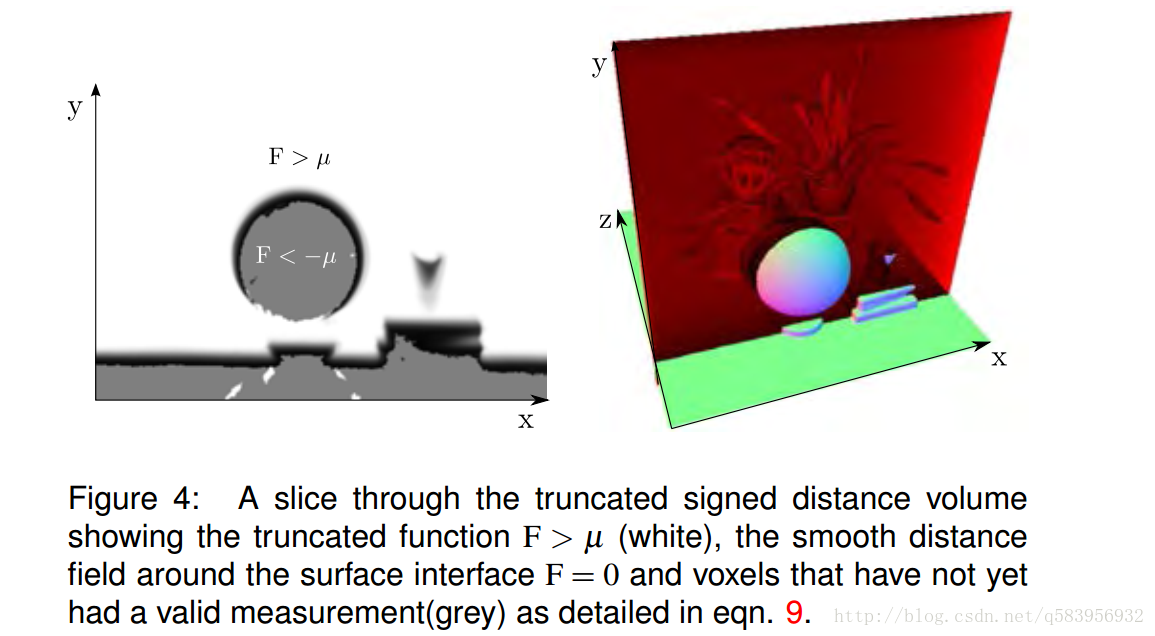
TSDF(truncated signed distance function),一般译作“截断符号距离描述函数”,可以把这个词拆开看:
- 一张深度图像反投影变换到三维空间中的每个三维点都对应着原深度图像中的每一个像素点,当点云比较稠密时,我们可以将该点云看成一个三维曲面,也就是function,记作 F(x,y,z)=0 。
- 所谓signed distance就是带正负符号的距离,以相机的光轴为Z轴,对于一个三维点 (x0,y0,z0) ,记 d=F(x0,y0,z0) ,如果它在平面前面,则 d 的值为正,否则为负,(这是《高等数学》空间几何代数部分的基础内容)。
- 而“truncated”就是截断,当
|d|>t 时,则 |d|=0 ,其中 t 是截断距离。
ICP算法(Iterate Closest Points)可以用于计算两组点云之间的刚体变换,对于 ICP算法有多种变种,如点到点 ICP(Point-to-Point)、点到面 ICP(Point-to-Plane)、面到面 ICP(Plane-to-Plane)等。
传统的 ICP(Point-to-Point)是需要知道两组点云之间,一组点云的各个点在另一组点云中的最近点,才能进行计算。显然,这需要遍历另一组点云以寻找最近点,最差会需要

为了抛掉“各个点的对应关系”这一搜索步骤,变种的 ICP都假设两组点之间的旋转、平移量很小,所以一个点附近的点就是它的当前最近点。
左图中是点到面 ICP,它并不需要去寻找最近的点是哪一个,这个算法所需要的只有两组点云的坐标和当前帧的法向量,也就是 Rk 、 Nk ,通过 Rk 可以计算得到当前帧的点云 Vk ,已知在此之前融合好的模型点云 V^gk 。

(图片摘自“KinectFusion 解析”)
GPU的三维数组中的每一个元素代表一个体素(Voxel),其存储在体素空间内的顶点的位置。
例如:用 1000×1000×1000 大小的三维数组表示 1m3 空间内的三维结构。每个元素就是一个体素(Voxel),这个元素对应的数组下标就表示体素在这 1m3 空间内的对应位置的 1cm3 空间,这个元素所存储的值,就是处于这 1cm3 空间中的顶点在这 1m3 内的精确位置。
通过使用TSDF的描述方法,以上图形式将 V^gk 作为距离描述函数曲面直接放在GPU的三维数组中,即GPU的各个线程对这个三维数组赋值,把对应位置的元素赋值为“0”,离相机近的一侧为正,另一侧为负。然后每个线程负责读取一个 Vk(u) 在这个三维数组中对应位置的值,就得到了当前 Vk(u)<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









