






我们今天继续聊低秩适应,或者简称LoRA。这个技术牛在哪呢?它能让那些已经训练好的大模型,比如特别大的那种语言模型或者视觉变换器,通过只调整一小部分关键参数,来更好地适应一些特别的、通常规模较小的数据集。这么一来,就能在特定任务上快速微调这些大家伙,省下了不少计算资源和时间。
而且,最近有研究者提出了一个叫DoRA( https://arxiv.org/abs/2402.09353)的新方法,它是LoRA的升级版,潜力巨大,可能会比LoRA做得还要好。
本文接下来会手把手教我们怎么用PyTorch这个工具来实现LoRA和DoRA,从头开始,一步步来。
在深入了解DoRA之前,先简单回顾了一下LoRA是怎么工作的。因为那些大型语言模型个头太大,如果在训练的时候更新所有的权重,可能会因为GPU内存不够用而变得很费钱。所以,他们会想出一个办法,那就是只更新一个叫做_W_的大权重矩阵里的一小部分,这样就能在训练过程中减少损失,做得更精准。
在常规训练和微调中,权重更新定义如下:
Wupdated = W + ΔW
LoRA方法由Hu等人提出,它提供了一种更有效的计算权重更新_ΔW的替代方案,通过学习它的近似值ΔW ≈ AB。换句话说,在LoRA中,我们有以下内容,其中A和B_是两个小权重矩阵:
Wupdated = W + A.B
(" ." 在" A.B"中代表矩阵乘法。)
下图并排说明了完全微调和LoRA微调的公式。
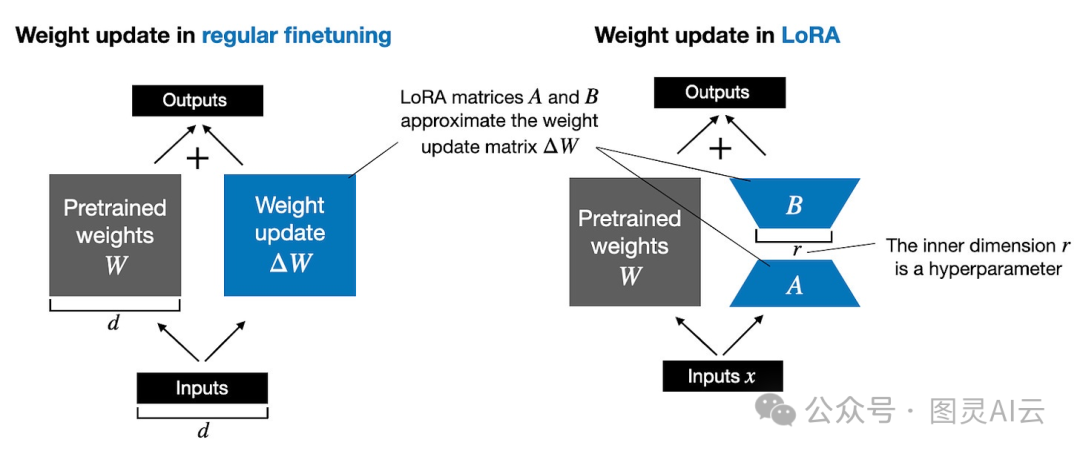
图:常规微调(左)和LoRA微调(右)的说明
LoRA这玩意儿咋就在GPU内存上这么省事儿呢?咱们来打个比方,假如说咱们手头有一个1000×1000那么大的预训练权重矩阵_W,要是咱们用常规方法来微调,那更新的权重矩阵ΔW_也得是这么大,这样一来,参数数量就达到了一百万。这得吃多少GPU内存啊!
但是,LoRA聪明就聪明在这儿,它用了一招叫低秩分解。咱们就拿秩为2的LoRA来说,它只用一个1000×2的矩阵_A和一个2×1000的矩阵B_,这么一来,需要更新的参数就只有4000个,跟原来比起来,少了足足250倍,这不就大大减轻了GPU的负担嘛!
当然了,_A和B这两个小矩阵,它们没法像大矩阵ΔW那样捕捉到所有的信息。但这就是LoRA的设计理念:在微调的时候,我们并不需要更新所有的权重,只需要通过AB_的低秩更新,就能捕捉到最关键的信息。
再仔细看看,文章里的完全微调和LoRA的描述,跟我之前说的公式可能有点儿不一样。这是因为矩阵乘法里头有个分配律,我们不用把原来的权重和更新后的权重加在一起,而是可以分开处理。比如说,_x_是输入数据,常规微调可以写成:
x.(W+ΔW) = x.W + x.ΔW
类似地,我们可以为LoRA写如下:
x.(W+A.B) = x.W + x.A.B
LoRA的一个特别吸引人的地方就是它能保持权重矩阵分开,这样做在实际应用中超级方便。你想啊,我们不需要去改动那些预训练模型的权重,因为LoRA矩阵是在运行的时候才用上的。这点对于要为很多客户托管模型的情况尤其有用。你想想,要是每个客户都要保存一个大型的更新后模型,那得多占地方,多麻烦。现在好了,只需要在原来的预训练模型旁边存一组小小的LoRA权重,多省事儿。
为了让这个概念更清晰,也为了让大家有更直观的理解,接下来咱们就要动手用代码来实现LoRA了。
首先,我们会初始化一个叫做LoRALayer的东西,这个小家伙会创建出矩阵A和B,还会设置alpha这个缩放的超参数和秩的超参数。这个层能够接受输入数据,然后计算出相应的输出。就像下面的图示那样。
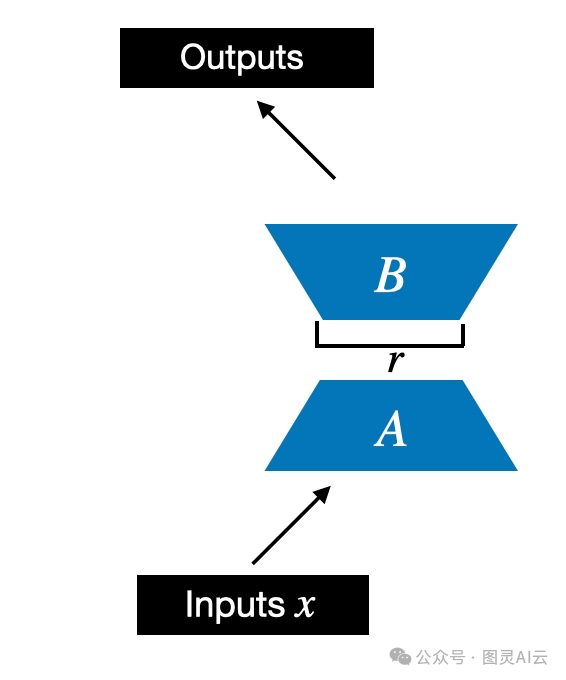
用秩_r_的LoRA矩阵A和B的说明
在代码中,上图中描述的LoRA层如下所示:
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.A = nn.Parameter(torch.randn(in_dim, rank) * std_dev)
self.B = nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x
在上面代码里,rank这个超参数可是个关键角色,它决定了矩阵_A_和_B_里面的维度大小。简单来说,就是它控制着LoRA得加多少额外的参数进去。这个参数特别重要,因为它关系到模型能不能灵活适应新任务,同时还得保证参数的效率,不能太多也不能太少。
再来说说另一个超参数,alpha,它是用来调节低秩适应输出的一个缩放因子。它的作用就是控制经过调整的层输出对原始层输出的影响有多大。你可以把它想象成是一个旋钮,用来调节低秩适应对整个层输出的影响力。
现在咱们实现的这个LoRALayer类,它能处理层的输入x并进行变换。但在LoRA的世界里,我们更关心的是怎么把现有的Linear层给替换掉,这样我们就能在不改变原有预训练权重的情况下,把权重更新给应用上。就像下面那张图展示的那样。
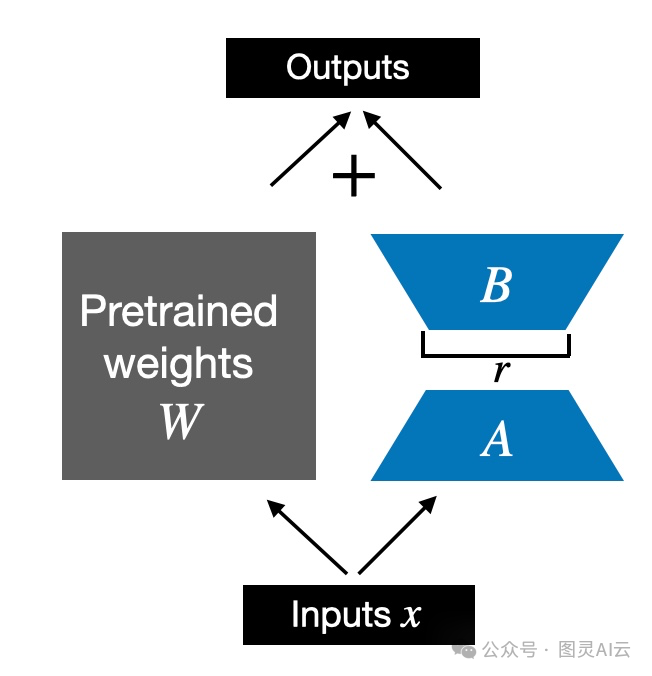
应用于现有线性层的LoRA
为了将原始线性层的权重纳入考虑,如上图所示,我们将实现一个LinearWithLoRA层,它使用先前实现的LoRALayer,并可以用来替换神经网络中现有的Linear层,例如,大型语言模型的自注意力模块或前馈模块:
class LinearWithLoRA(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)
注意,由于我们在LoRA层中用零值初始化了权重矩阵B(self.B in LoraLayer),_A_和_B_的矩阵乘法结果是一个由0组成的矩阵,并且不会影响原始权重(因为将0添加到原始权重不会修改它们)。
让我们尝试在一个小的神经网络层上应用LoRA,该层由一个单一的Linear层表示:
输入:
torch.manual_seed(123)
layer = nn.Linear(10, 2)
x = torch.randn((1, 10))
print("Original output:", layer(x))
输出:
Original output: tensor([[0.6639, 0.4487]], grad_fn=<AddmmBackward0>)
现在,将LoRA应用于Linear层,我们看到结果是一样的,因为我们还没有训练LoRA权重。换句话说,一切都按预期工作:
输入:
layer_lora_1 = LinearWithLoRA(layer, rank=2, alpha=4)
print("LoRA output:", layer_lora_1(x))
输出:
LoRA output: tensor([[0.6639, 0.4487]], grad_fn=<AddmmBackward0>)
之前,我提到了矩阵乘法的分配律:
x.(W+A.B) = x.W + x.A.B。
这里,这意味着我们也可以组合或合并LoRA矩阵和原始权重,这应该会导致一个等效的实现。在代码中,LinearWithLoRA层的这种替代实现如下:
class LinearWithLoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
lora = self.lora.A @ self.lora.B # Combine LoRA matrices
# Then combine LoRA with orig. weights
combined_weight = self.linear.weight + self.lora.alpha*lora.T
return F.linear(x, combined_weight, self.linear.bias)
简而言之,LinearWithLoRAMerged计算等式_x.(W+A.B) = x.W + x.A.B_ 的左侧,而LinearWithLoRA计算右侧——两者都是等效的。
我们可以通过以下代码验证这是否会产生与之前相同的输出:
输入:
layer_lora_2 = LinearWithLoRAMerged(layer, rank=2, alpha=4)
print("LoRA output:", layer_lora_2(x))
输出:
LoRA output: tensor([[0.6639, 0.4487]], grad_fn=<AddmmBackward0>)
现在我们已经有一个工作的LoRA实现,让我们看看如何在下一部分将其应用于神经网络。
为什么我们使用上述方式使用PyTorch模块实现LoRA?这种方法使我们能够轻松地将现有的Linear层替换为新的LinearWithLoRA(或LinearWithLoRAMerged)层。
为了简单起见,我们暂时关注一个小型的3层多层感知器,而不是一个大型语言模型,如下图所示:
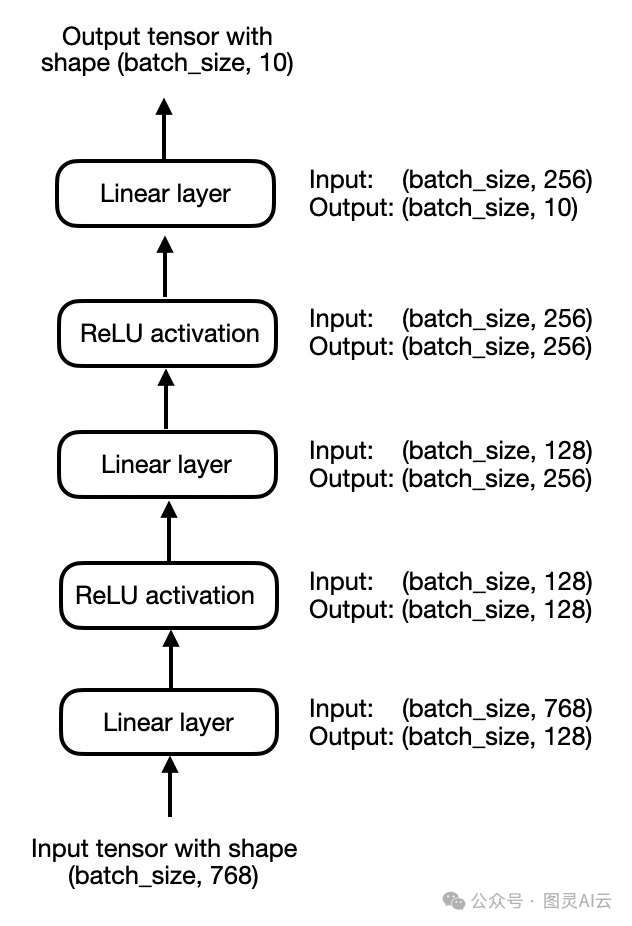
一个简单的3层多层感知器
在代码中,我们可以如下实现上述多层感知器:
输入:
class MultilayerPerceptron(nn.Module):
def __init__(self, num_features,
num_hidden_1, num_hidden_2, num_classes):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(num_features, num_hidden_1),
nn.ReLU(),
nn.Linear(num_hidden_1, num_hidden_2),
nn.ReLU(),
nn.Linear(num_hidden_2, num_classes)
)
def forward(self, x):
x = self.layers(x)
return x
model = MultilayerPerceptron(
num_features=num_features,
num_hidden_1=num_hidden_1,
num_hidden_2=num_hidden_2,
num_classes=num_classes
)
print(model)
输出:
MultilayerPerceptron(
(layers): Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=256, bias=True)
(3): ReLU()
(4): Linear(in_features=256, out_features=10, bias=True)
)
)
使用LinearWithLora,我们可以通过替换多层感知器模型中的原始Linear层来添加LoRA层:
输入:
model.layers[0] = LinearWithLoRA(model.layers[0], rank=4, alpha=8)
model.layers[2] = LinearWithLoRA(model.layers[2], rank=4, alpha=8)
model.layers[4] = LinearWithLoRA(model.layers[4], rank=4, alpha=8)
print(model)
输出:
MultilayerPerceptron(
(layers): Sequential(
(0): LinearWithLoRA(
(linear): Linear(in_features=784, out_features=128, bias=True)
(lora): LoRALayer()
)
(1): ReLU()
(2): LinearWithLoRA(
(linear): Linear(in_features=128, out_features=256, bias=True)
(lora): LoRALayer()
)
(3): ReLU()
(4): LinearWithLoRA(
(linear): Linear(in_features=256, out_features=10, bias=True)
(lora): LoRALayer()
)
)
)
然后,我们可以冻结原始的Linear层,只让LoRA层可训练,如下所示:
输入:
def freeze_linear_layers(model):
for child in model.children():
if isinstance(child, nn.Linear):
for param in child.parameters():
param.requires_grad = False
else:
# Recursively freeze linear layers in children modules
freeze_linear_layers(child)
freeze_linear_layers(model)
for name, param in model.named_parameters():
print(f"{name}: {param.requires_grad}")
输出:
layers.0.linear.weight: False
layers.0.linear.bias: False
layers.0.lora.A: True
layers.0.lora.B: True
layers.2.linear.weight: False
layers.2.linear.bias: False
layers.2.lora.A: True
layers.2.lora.B: True
layers.4.linear.weight: False
layers.4.linear.bias: False
layers.4.lora.A: True
layers.4.lora.B: True
从上面的True和False值,我们可以一目了然地看出,现在只有LoRA层是可以训练的,这里的True就代表可训练,而False则表示这部分是冻结的。实际操作中,我们会在这个配置了LoRA的状态下开始训练网络。
接下来聊聊DoRA,也就是权重分解的低秩适应,这可以看作是在LoRA的基础上做了改进或者增加了新功能。调整一下我们之前的代码,就能轻松实现DoRA了。
DoRA这个过程大概分两步走:首先,把预训练的权重矩阵拆成两个部分,一个是大小向量(m),另一个是方向矩阵(V)。然后,我们对方向矩阵_V应用LoRA的处理,同时,大小向量m_也单独进行训练。
这种把一个东西拆成大小和方向两个部分的想法,其实是从数学里的一个原理来的,就是说任何一个向量,都能看成是它的长度(一个数字,表示它伸多远)和它指向哪儿(一个箭头,表示它指哪个方向)这么两个事儿的乘积。
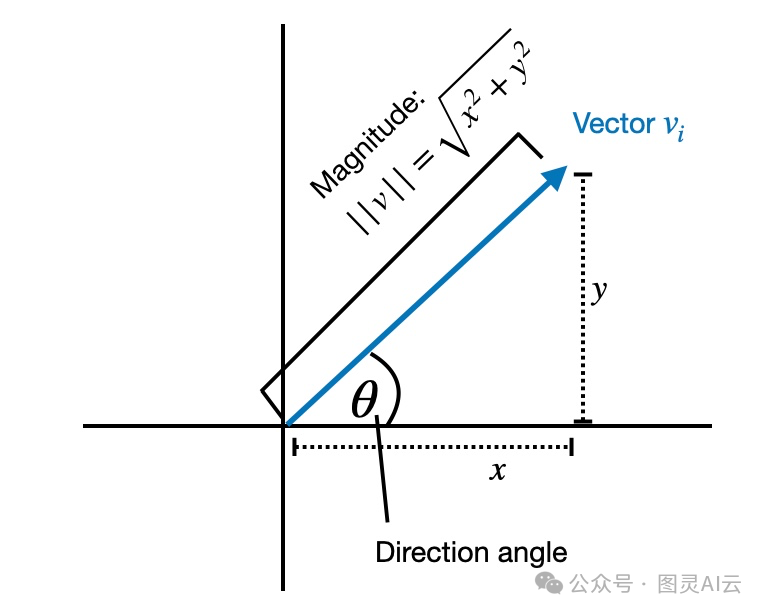
单个向量的方向和大小的说明
比如说,咱们手头有一个2D向量[1, 2],咱们可以把它拆成两个部分:大小是2.24,方向向量是[0.447, 0.894]。这么一来,2.24乘以[0.447, 0.894]就又得到原来的向量[1, 2]了。
在DoRA这个方法里,我们不是只对一个向量这么做,而是把这种分解的方法用在了整个预训练的权重矩阵_W_上。这个矩阵的每一列就相当于一个向量,它代表了所有输入到某个特定输出神经元的权重连接。
所以,当我们把_W这个矩阵分解后,得到的就是大小向量m_,它表示的是权重矩阵里每个列向量的大小或者比例。就像下面这张图展示的那样。
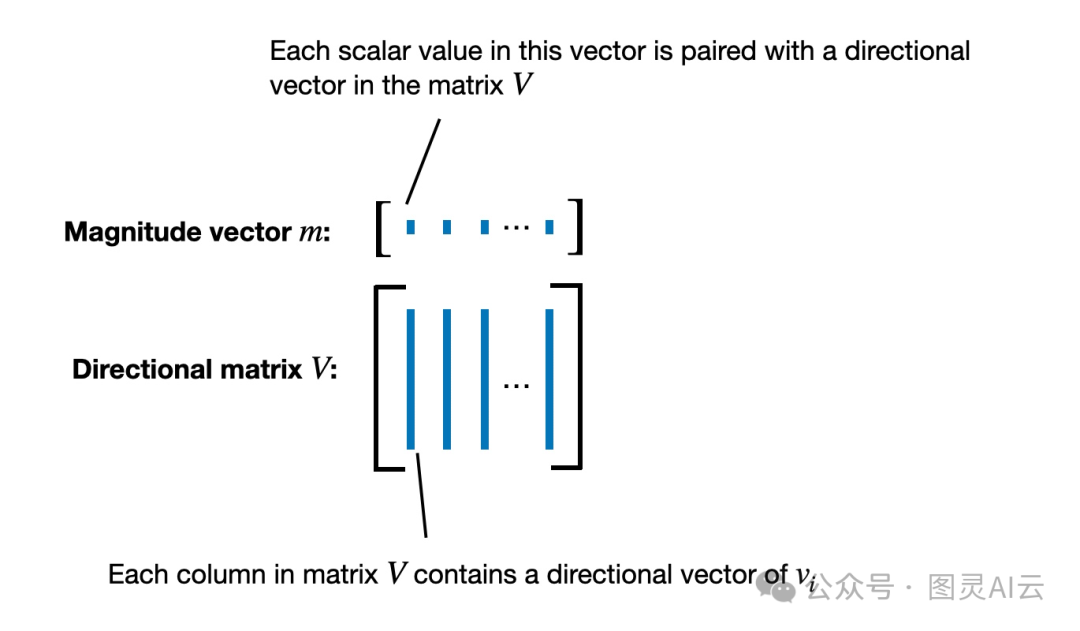
DoRA中权重矩阵分解的说明
接着,DoRA用方向矩阵_V_来应用标准的LoRA,就像这样:
W' = m (V + ΔV)/norm = m (W + AB)/norm
这里我用了"norm"这个词来代表规范化,主要是为了不让这次解释变得太复杂。这种规范化方法是基于Saliman和Kingma在2016年提出的一种权重规范化技术,它通过简单的重新参数化来加速深度神经网络的训练。
DoRA的这两步——把预训练的权重矩阵分解,然后对方向矩阵应用LoRA——在DoRA的论文里的下图中有更详细的说明。
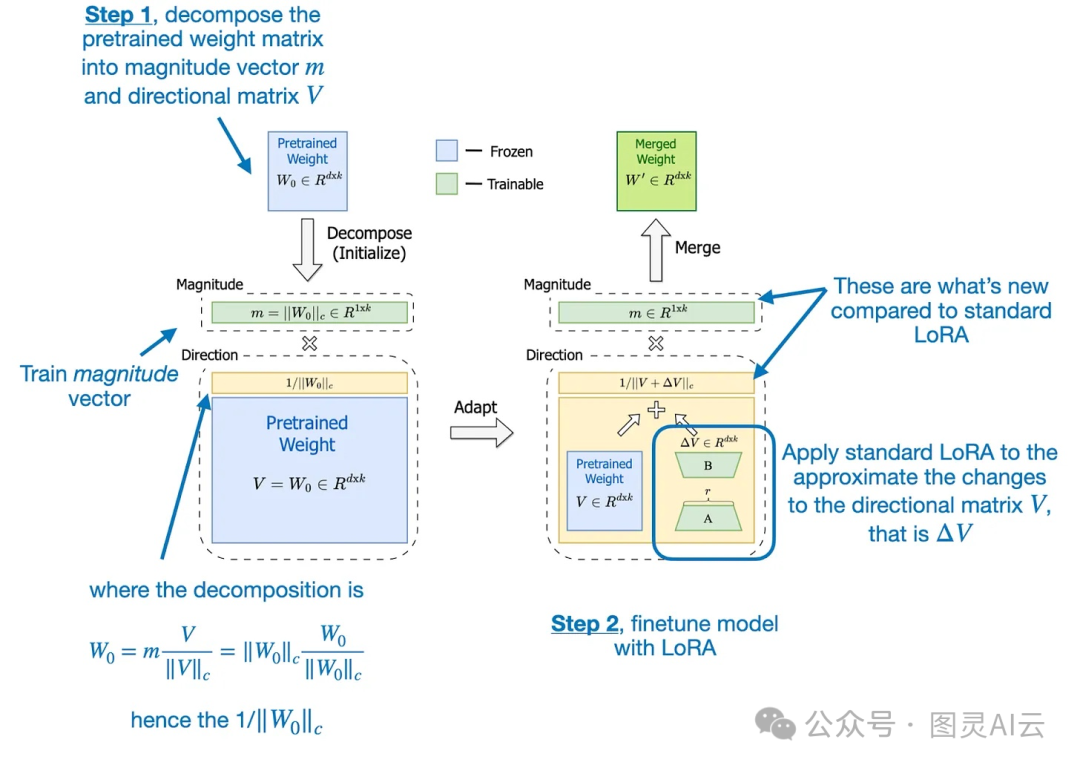
开发DoRA的初衷是分析并比较LoRA和完全微调的学习模式。DoRA的研究者们发现,LoRA在更新时会成比例地调整大小和方向,但似乎缺少在完全微调中那种仅对方向进行细微调整的能力。因此,他们提出了将大小和方向这两个组件分开来处理。
换句话说,DoRA这个方法的目标是对方向组件_V单独应用LoRA,同时让大小组件m_能够独立训练。
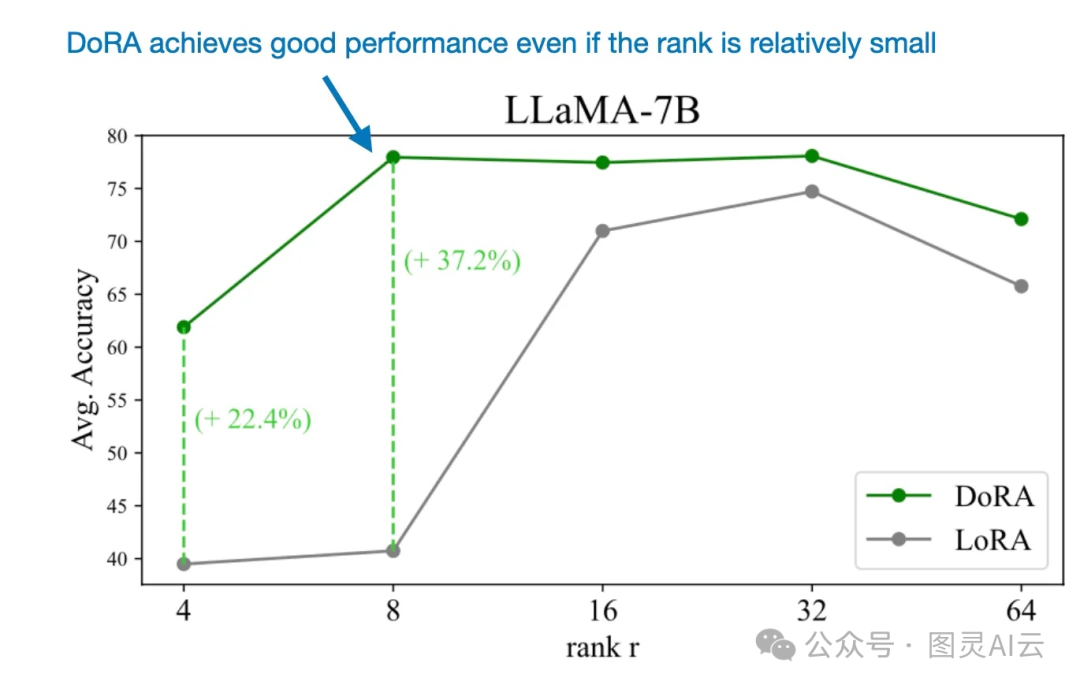
虽然引入大小向量_m_让DoRA的参数比LoRA多了0.01%,但是在大型语言模型和视觉变换器的基准测试中,即使DoRA的秩减半,它的表现也超过了LoRA。就像下面图表中展示的性能对比。
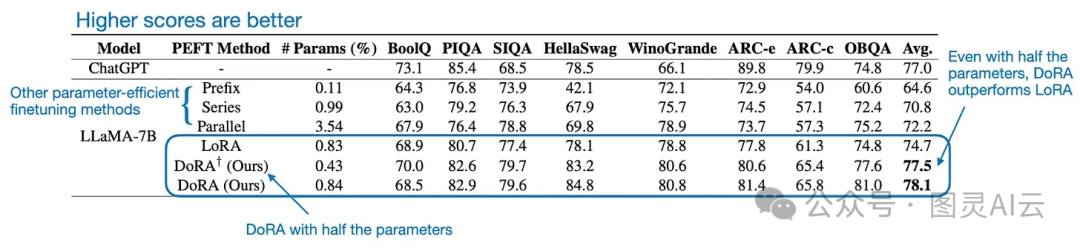
就像我几个月前在另一篇文章里提到的,使用LoRA(低秩适应)对大型语言模型进行微调时,需要仔细调整秩来优化性能。但是,DoRA似乎对于秩的变化更加不敏感,就像下面比较图所展示的。
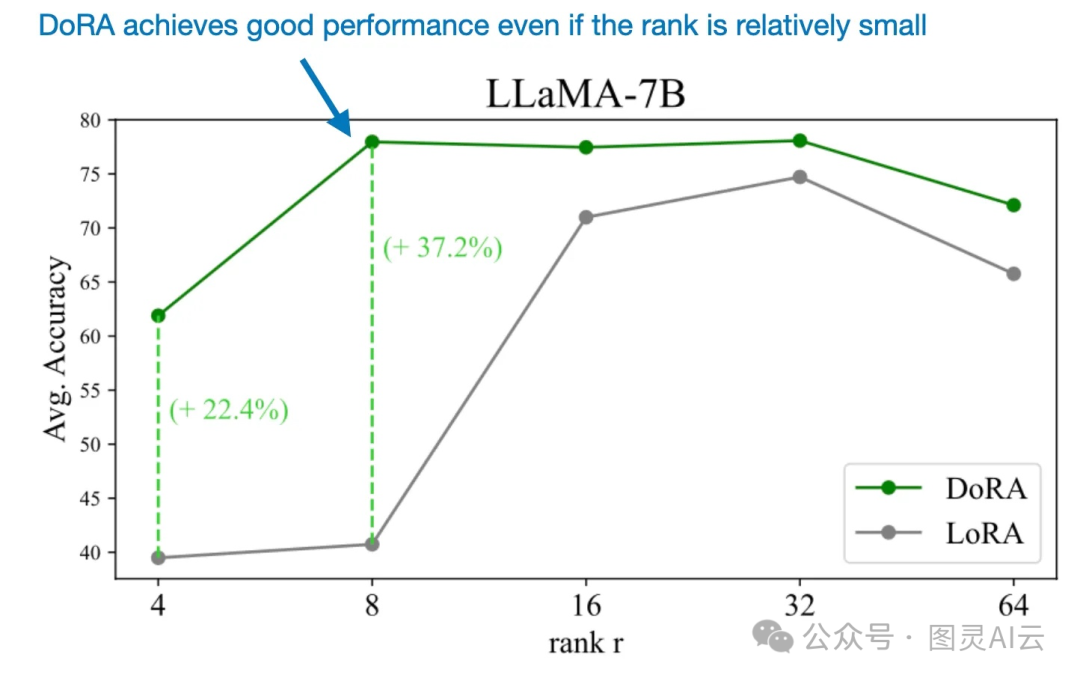
能够在使用相对较小的秩的情况下成功应用DoRA,使得这种方法在参数效率上超过了LoRA。
总的来说,我对DoRA的结果印象非常深刻,而且把LoRA的实现升级到DoRA应该不会太复杂,我们接下来就会做这件事。
在这一部分,我们会看看DoRA在代码里长什么样。之前我们提到,我们可以初始化一个预训练的权重_W0,以及对应的大小m和方向部分V_。比如,我们有下面这样的等式:
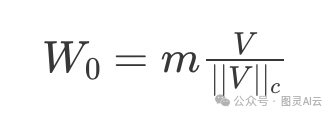
其中(|| V ||c)是_V的向量范数。然后我们可以写下包括LoRA权重更新BA_的DoRA,如下所示:
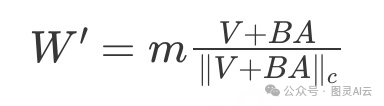
现在,在DoRA论文中,作者将DoRA表述如下,他们直接使用初始预训练权重_W0作为方向分量,并在训练过程中学习大小向量m_:
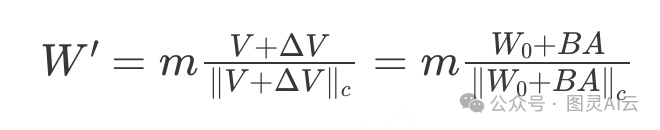
这里,(\Delta V)是对方向分量矩阵_V_的更新。
虽然原始作者尚未发布官方实现,但你可以在这里找到独立实现,它松散地启发了我的以下实现:
利用我们之前的LinearWithLoRAMerged实现,我们可以将其升级为DoRA,如下所示:
class LinearWithDoRAMerged(nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
self.m = nn.Parameter(
self.linear.weight.norm(p=2, dim=0, keepdim=True))
# Code loosely inspired by
# https://github.com/catid/dora/blob/main/dora.py
def forward(self, x):
lora = self.lora.A @ self.lora.B
numerator = self.linear.weight + self.lora.alpha*lora.T
denominator = numerator.norm(p=2, dim=0, keepdim=True)
directional_component = numerator / denominator
new_weight = self.m * directional_component
return F.linear(x, new_weight, self.linear.bias)
咱们的LinearWithDoRAMerged类和之前的LinearWithLoRAMerged类相比,有几个关键的不同点,主要是在它怎么修改和用线性层的权重上。不过,这两个类都用了LoRALayer来增强原始的线性层权重,但DoRA还加了权重的规范化和调整。
就像下面这张图显示的,LinearWithLoRAMerged和LinearWithDoRAMerged之间的代码差异:

从图里可以看出,LinearWithDoRAMerged加了一个额外的步骤,就是动态地规范化那些增强后的权重。
在把原始权重和LoRA调整过的权重结合起来之后(也就是self.linear.weight + self.lora.alpha*lora.T),它会算出这些组合权重的范数(column_norm)。然后,它会通过除以这些范数来规范化组合权重(V = combined_weight / column_norm)。这样做确保了组合权重矩阵的每一列都保持单位范数,这有助于在学习过程中保持权重更新的规模稳定。
DoRA还加了一个可以学习的向量self.m,它表示归一化后的权重矩阵中每个权重向量的大小。这个参数让模型在训练的时候能动态地调整组合权重矩阵里每个向量的比例。这种额外的灵活性,可以帮助模型更好地识别不同特征的重要性。
总的来说,LinearWithDoRAMerged通过加上动态的权重规范化和缩放,扩展了LinearWithLoRAMerged的功能,提高了训练的效果。
在实际应用中,就像之前提到的多层感知器,我们可以轻松地把现有的Linear层换成我们的LinearWithDoRAMerged层,操作就像下面这样:
输入:
model.layers[0] = LinearWithDoRAMerged(model.layers[0], rank=4, alpha=8)
model.layers[2] = LinearWithDoRAMerged(model.layers[2], rank=4, alpha=8)
model.layers[4] = LinearWithDoRAMerged(model.layers[4], rank=4, alpha=8)
print(model)
输出:
MultilayerPerceptron(
(layers): Sequential(
(0): LinearWithDoRAMerged(
(linear): Linear(in_features=784, out_features=128, bias=True)
(lora): LoRALayer()
)
(1): ReLU()
(2): LinearWithDoRAMerged(
(linear): Linear(in_features=128, out_features=256, bias=True)
(lora): LoRALayer()
)
(3): ReLU()
(4): LinearWithDoRAMerged(
(linear): Linear(in_features=256, out_features=10, bias=True)
(lora): LoRALayer()
)
)
)
在我们微调模型之前,我们可以重用我们之前实现的freeze_linear_layers函数,只让LoRA权重和大小向量可训练:
输入:
freeze_linear_layers(model)
for name, param in model.named_parameters():
print(f"{name}: {param.requires_grad}")
输出:
layers.0.m: True
layers.0.linear.weight: False
layers.0.linear.bias: False
layers.0.lora.A: True
layers.0.lora.B: True
layers.2.m: True
layers.2.linear.weight: False
layers.2.linear.bias: False
layers.2.lora.A: True
layers.2.lora.B: True
layers.4.m: True
layers.4.linear.weight: False
layers.4.linear.bias: False
layers.4.lora.A: True
layers.4.lora.B: True
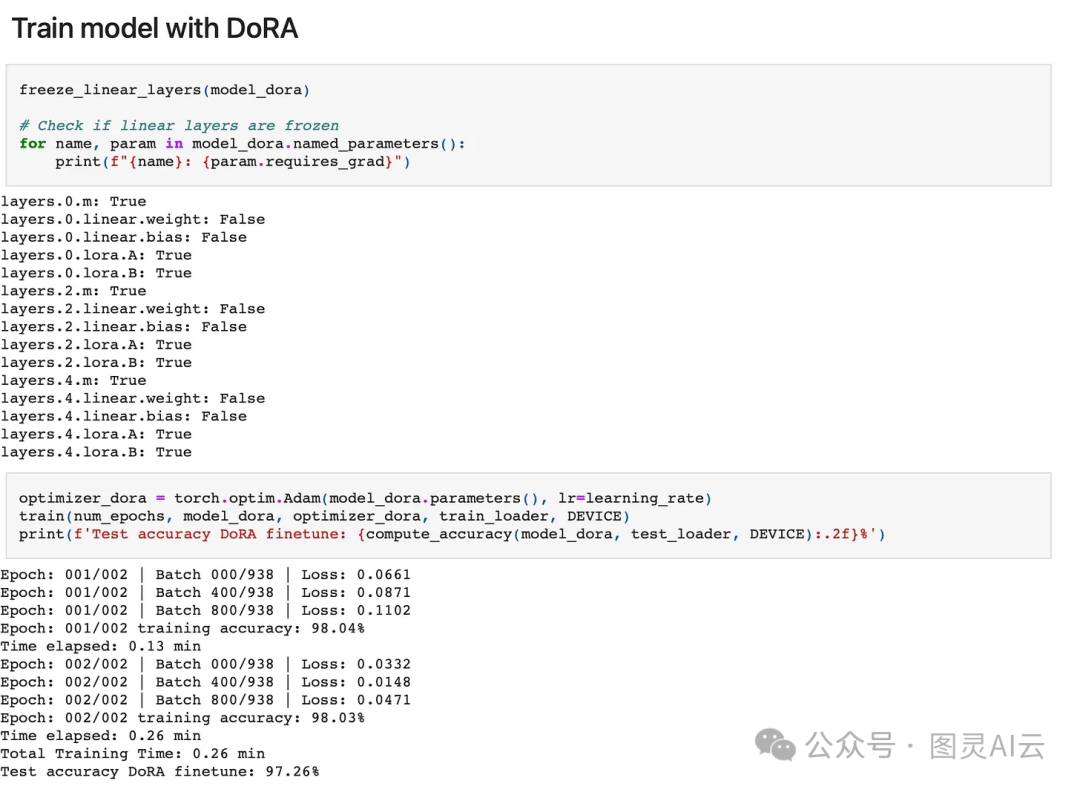
DoRA在LoRA的基础上做了挺棒的延伸,它不仅逻辑上说得通,而且效果也挺不错,给人感觉挺有前景的。就算没有特意去调那些超参数,我都已经看到它的预测准确率比LoRA提高了超过1%呢。



















 242
242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









