








论文链接:嘻嘻哈哈
Abstract
FLIP是一种简单且高效训练CLIP的方法,它在训练过程中去除了大量的图像补丁
Introduction
text masking带来的增益很小,因为文本编码器较小,文本序列较短
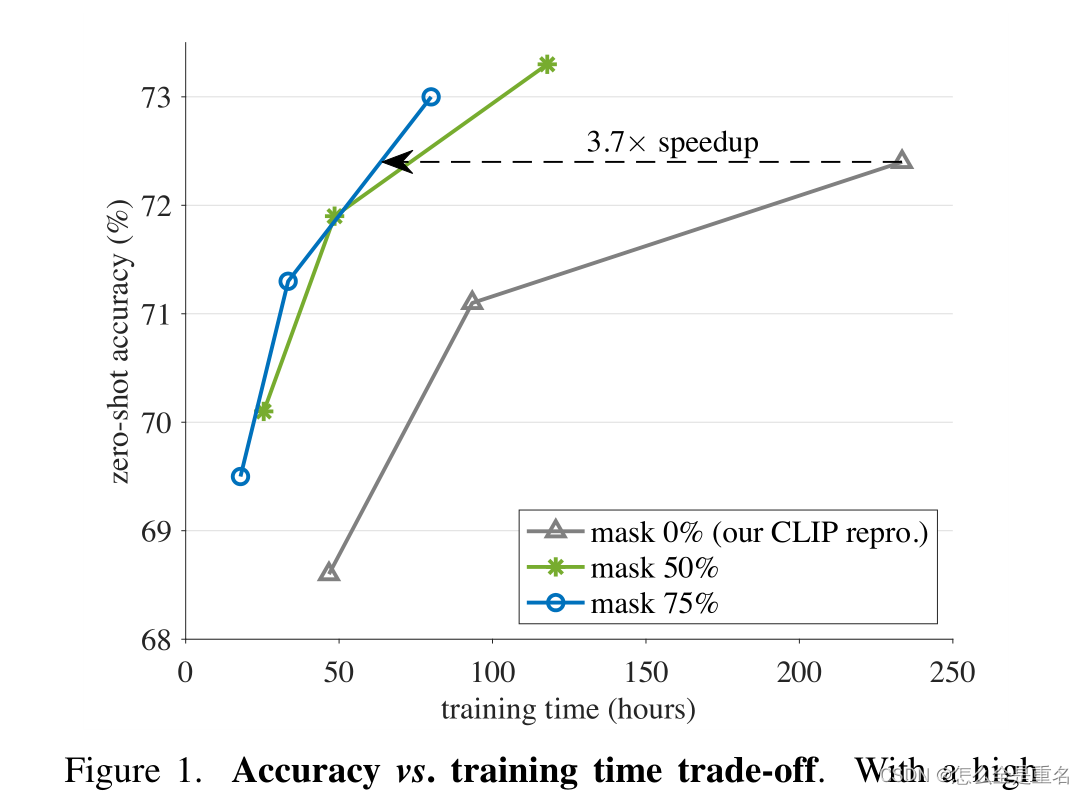
CLIP训练非常耗时,收到MAE稀疏计算的启发,随机的去除了大部分图像补丁,提出的FLIP可达到他3.7倍的速度,并且精度类似甚至更优
通过引入masking,可以在相同的挂钟训练时间下,看到更多的样本对,在相似的内存占用下,每批次可以比较更多的样本对
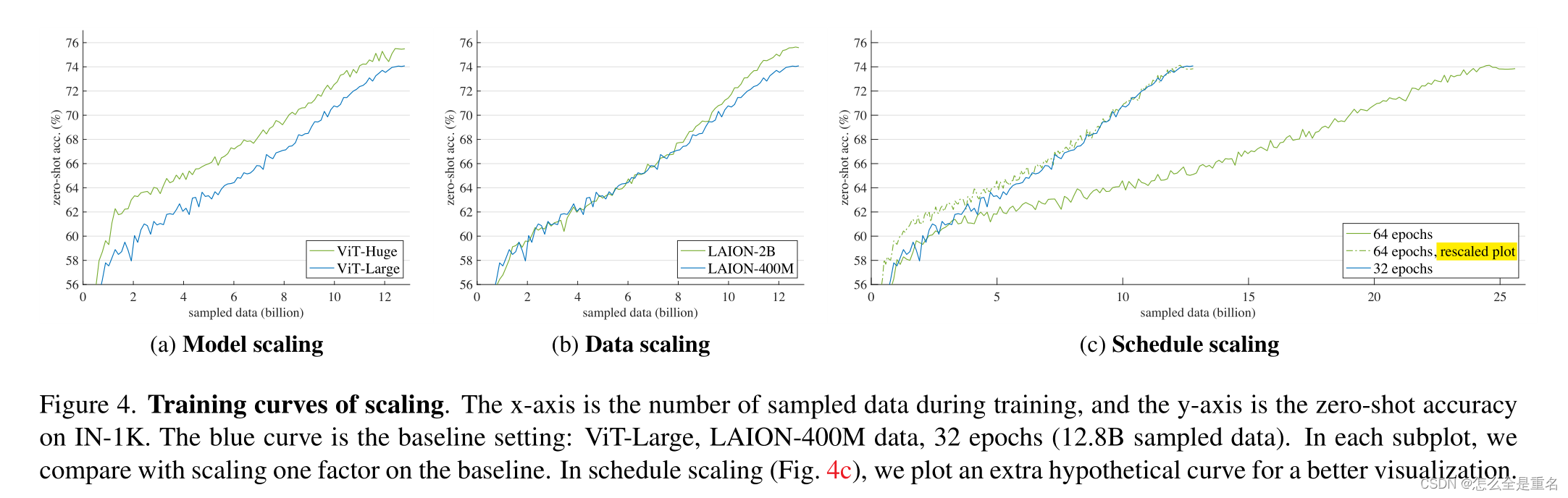
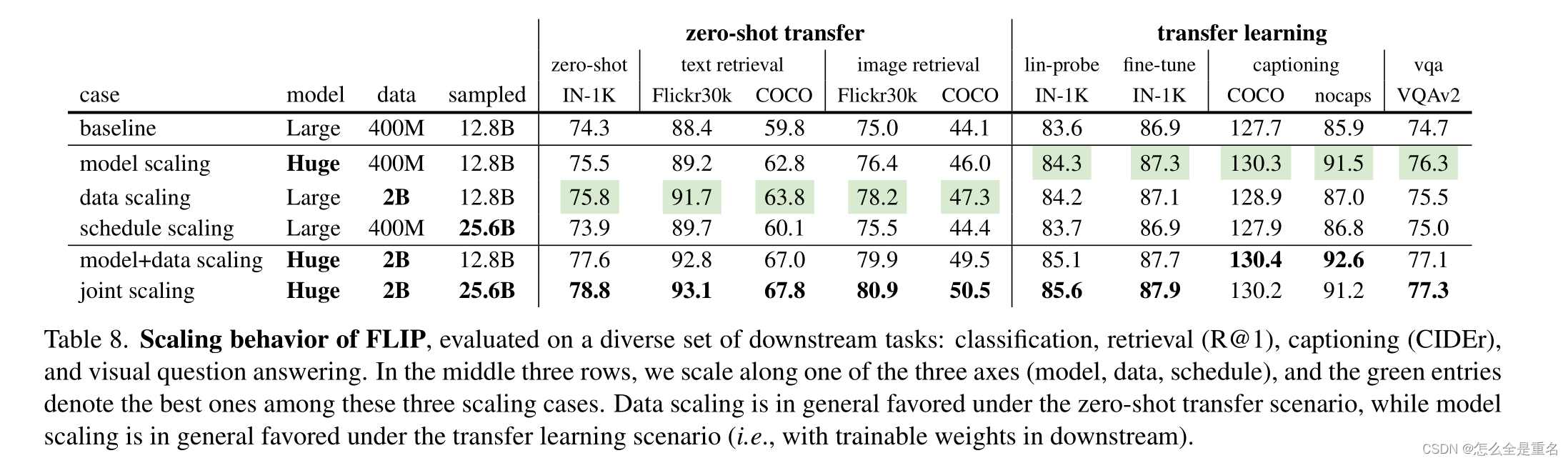
model scaling,data scaling都能提高精准率,schedule scaling几乎没有增益,且同时进行model+data是优于分开的总和
Method
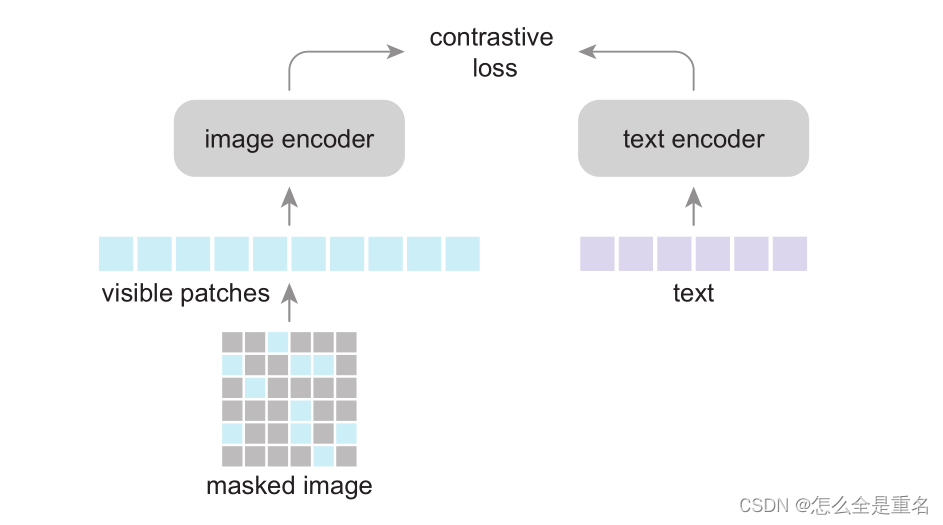
Image masking
作者采用视觉变压器(ViT)作为图像编码器。首先将图像划分为不重叠的小块网格。随机屏蔽掉很大一部分(例如,50%或75%)的补丁
Text masking
因为文本编码器较小,文本序列较短,总的速度增益是微不足道的
Objective
大量的负样本对于图像的自监督对比学习至关重要
Unmasking
虽然编码器是在遮罩图像上进行预训练的,但它可以直接应用于完整的图像而不做任何改变,为了缩小掩蔽造成的分布差距,我们可以将掩蔽率设置为0%,继续进行小步数的预训练。这种Unmasking的调优策略产生了更有利的精度/时间权衡

Experiment and Conclusion
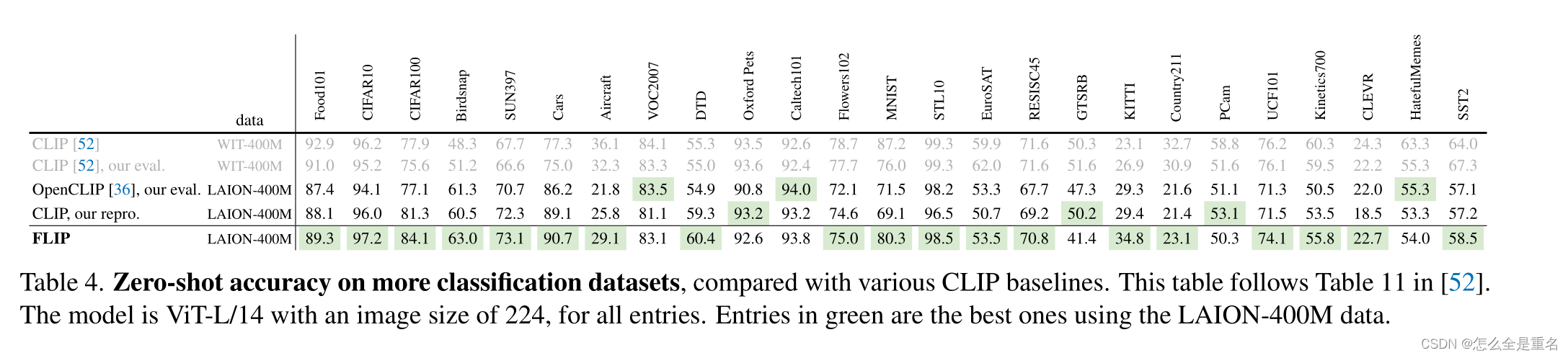
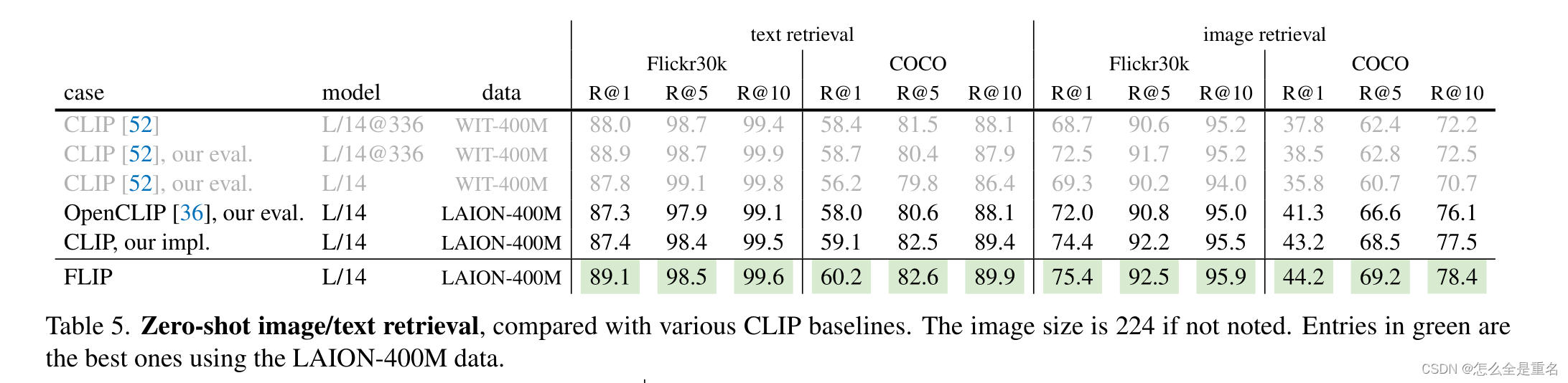
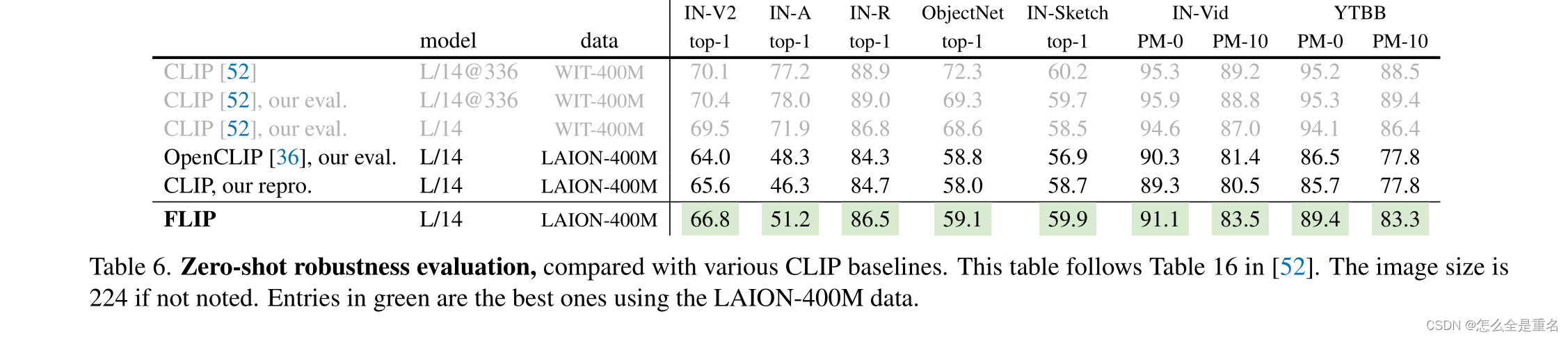
在各种各样的场景中,FLIP明显优于其CLIP对应物
在某些情况下,数据差距很大。正如在许多下游任务中观察到的那样,WIT数据和LAION数据之间的差异可能会造成很大的系统差距。
















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









