








原文
代码
Abstract
本文探讨了深度学习在长尾分布数据集上的分类问题,并提出了将表示学习和分类器学习分开的方法。通过实验发现,即使使用最简单的平衡采样方法,也可以获得高质量的表示学习结果,并且只调整分类器即可实现强大的长尾识别能力
Method
本文提出了一种学习表示以实现长尾识别的方法。在长尾分布下,训练集中的某些类别的样本数量非常少,因此模型很难对其进行准确分类。为了解决这个问题,本文提出了多种重采样策略、损失加权和边界的正则化等方法来提高模型性能。此外,本文还介绍了如何将表示学习与分类器学习分离,以便更好地理解哪些因素对于长尾识别至关重要。
Improve
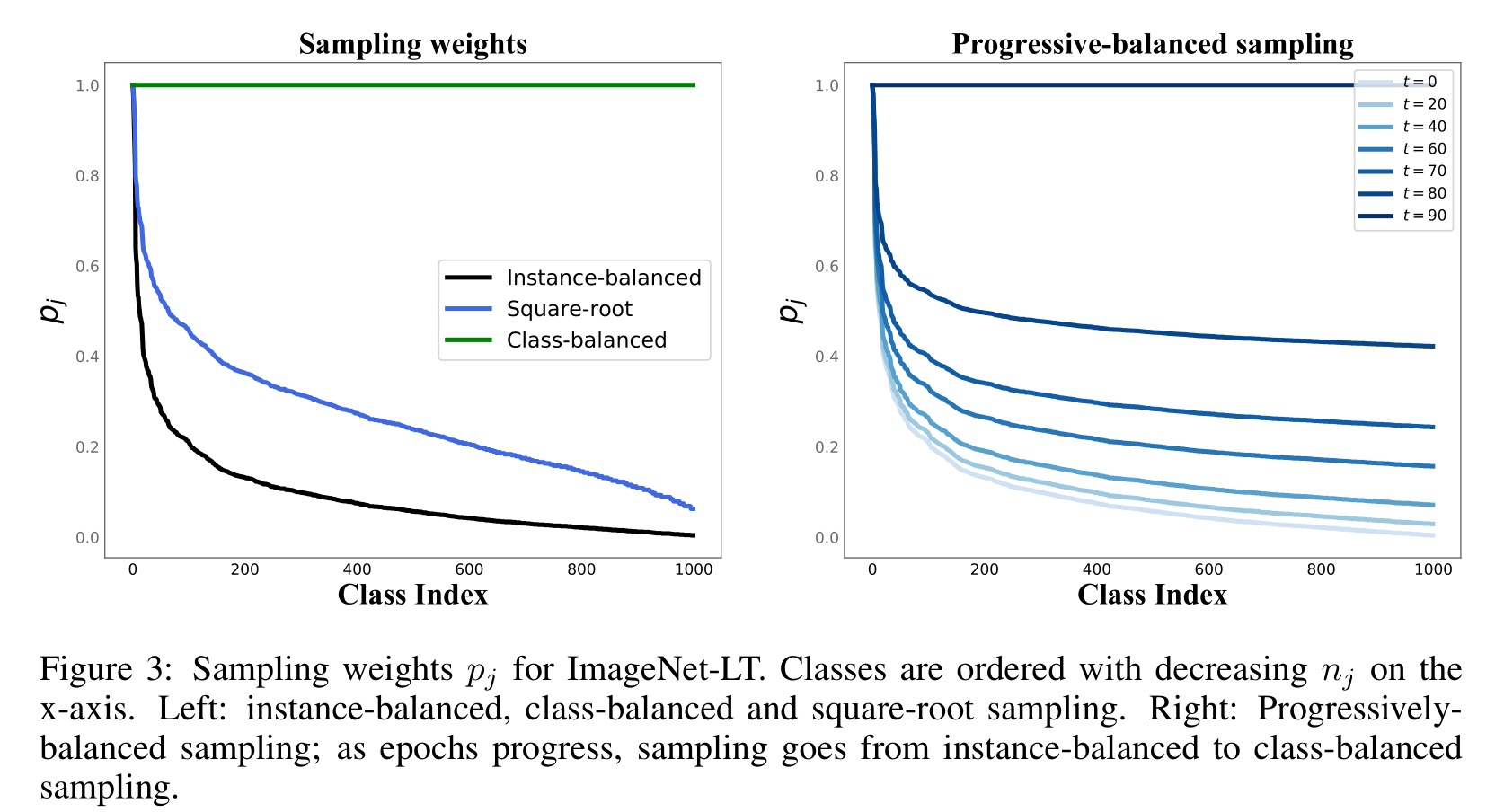
本文提出的改进方法包括:(1)实例平衡采样、类别平衡采样、平方根采样和渐进平衡采样等多种采样策略;(2)基于交叉熵损失函数的学习表示和分类器联合优化方法;(3)使用最近邻均值分类器和τ-归一化分类器等非参数方法来进行分类器微调;(4)学习可扩展的权重缩放因子以调整决策边界
solve
本文的主要目标是解决长尾识别问题,即在数据集中存在大量少数类别的情况下,如何有效地训练模型以使其能够正确地识别这些少数类别。通过引入各种采样策略、损失加权和正则化方法以及分类器微调技术,本文旨在提高模型在长尾分布下的性能,并帮助研究者更好地理解哪些因素对于长尾识别最为重要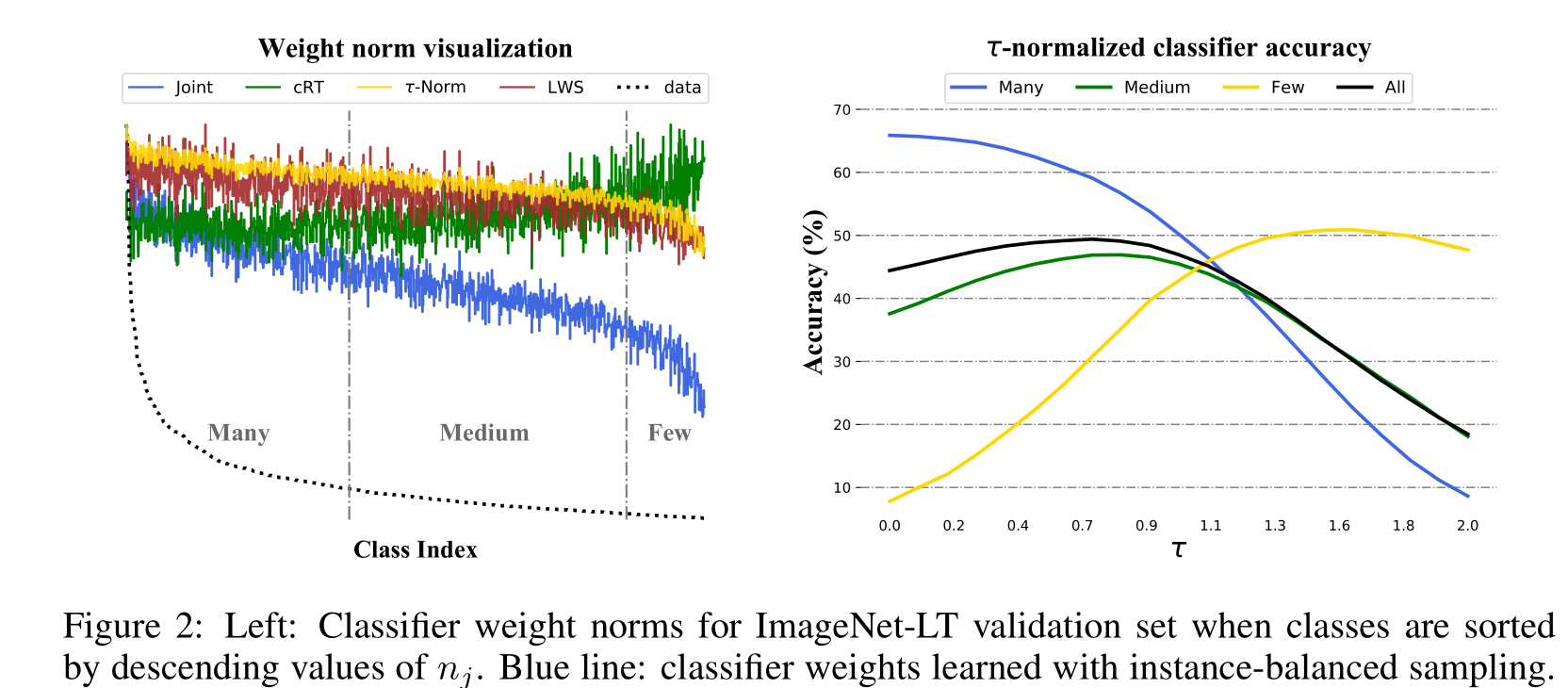

Experiment
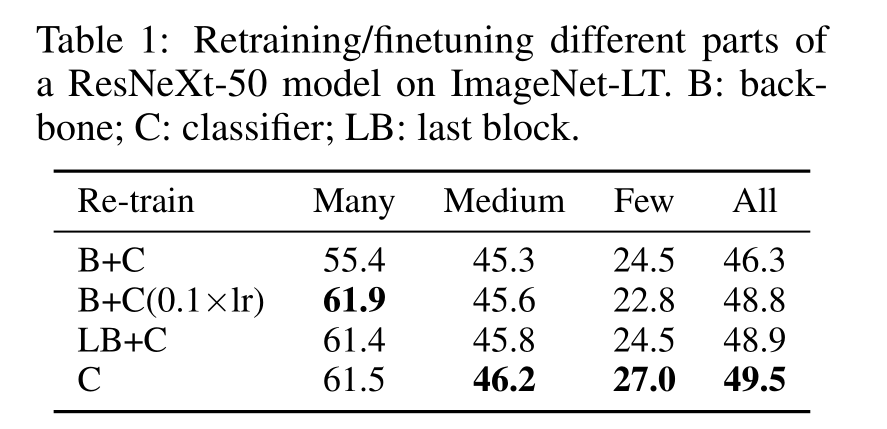
对于不同的采样策略和学习方式的比较:作者在ImageNet-LT数据集上比较了不同采样策略和学习方式的效果,包括联合训练和分离训练两种方式。结果表明,分离训练的方式比联合训练更有效,其中以重新初始化并重新训练分类器(cRT)和τ-归一化分类器(τ-Norm)效果最好。
对于不同的分类器平衡方法的比较:作者在ImageNet-LT数据集上比较了不同的分类器平衡方法的效果,包括非参数化的最近邻均值法(NCM)、重新训练分类器(cRT)和τ-归一化分类器(τ-Norm)。结果表明,τ-归一化分类器的效果最好,其次是重新训练分类器,而NCM的效果最差。
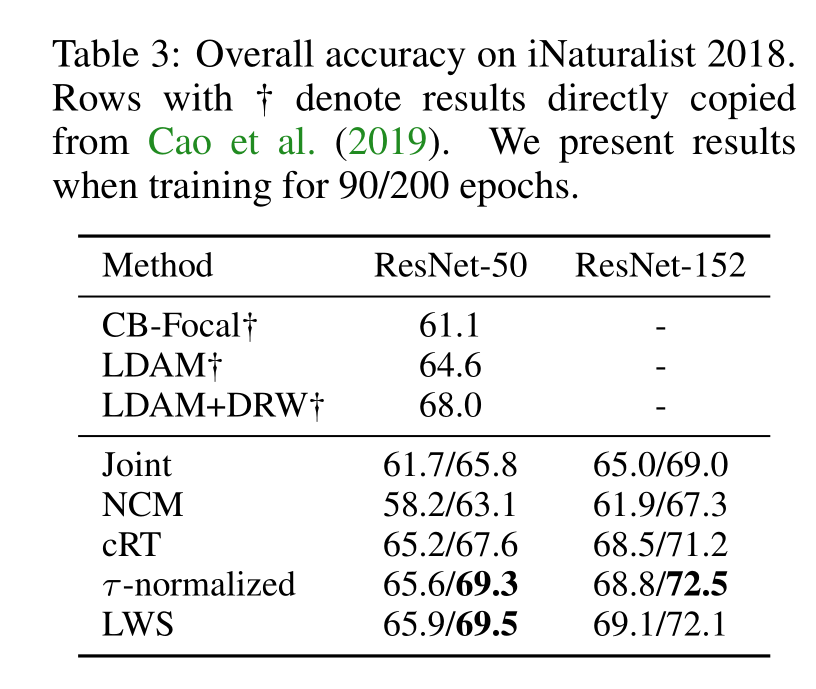
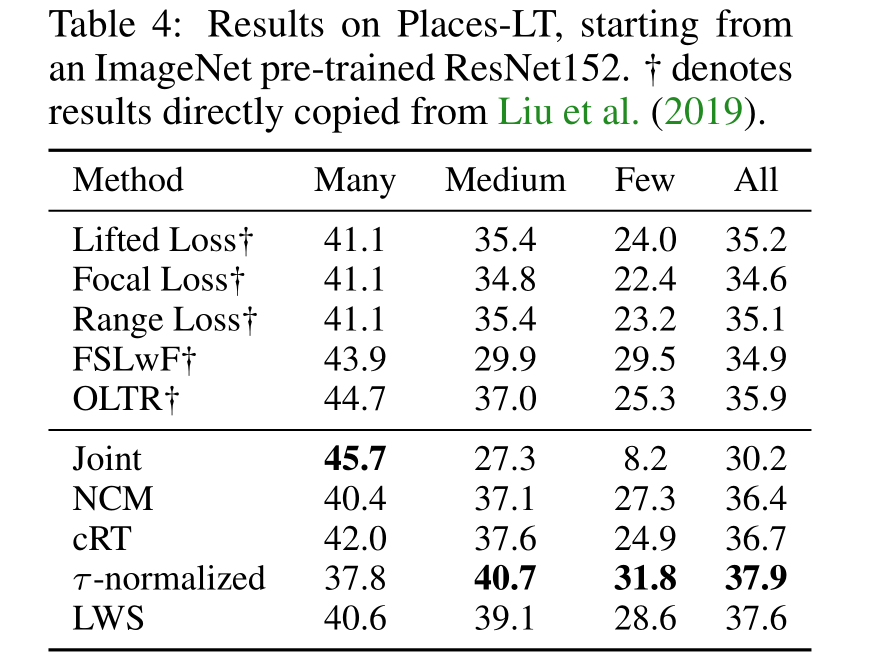
对于其他长尾数据集上的比较:作者将他们的方法与其他最新的长尾数据集上的方法进行了比较,包括iNaturalist 2018和Places-LT数据集。结果表明,他们的方法在这些数据集上都取得了最好的效果
创新
本文提出了将表示学习和分类器训练分离的方法,从而更好地解决长尾识别中的数据不平衡问题。同时,作者还提出了一些新的决策边界调整方法,包括重新训练线性分类器、基于最近邻类均值的非参数分类器以及归一化的权重调整等。这些方法不仅简单有效,而且只需要一个超参数来控制温度,不需要额外的训练















 898
898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









