







 超级会员免费看
超级会员免费看
-
ScaNN 索引
Milvus 目前支持了 Faiss 中的 FastScan 算法,在各项 benchmark 中有着不俗的表现,对比 HNSW 有 20% 左右提升,约为 IVFFlat 的 7 倍,同时构建索引速度更快。ScaNN 在算法上跟 IVFPQ 比较类似,聚类分桶,然后桶里的向量使用 PQ 做量化,区别是 ScaNN 对于量化比较激进,搭配上 SIMD 计算效率较高,但是精度损失会比较大,需要有原始向量做 refine 的过程。

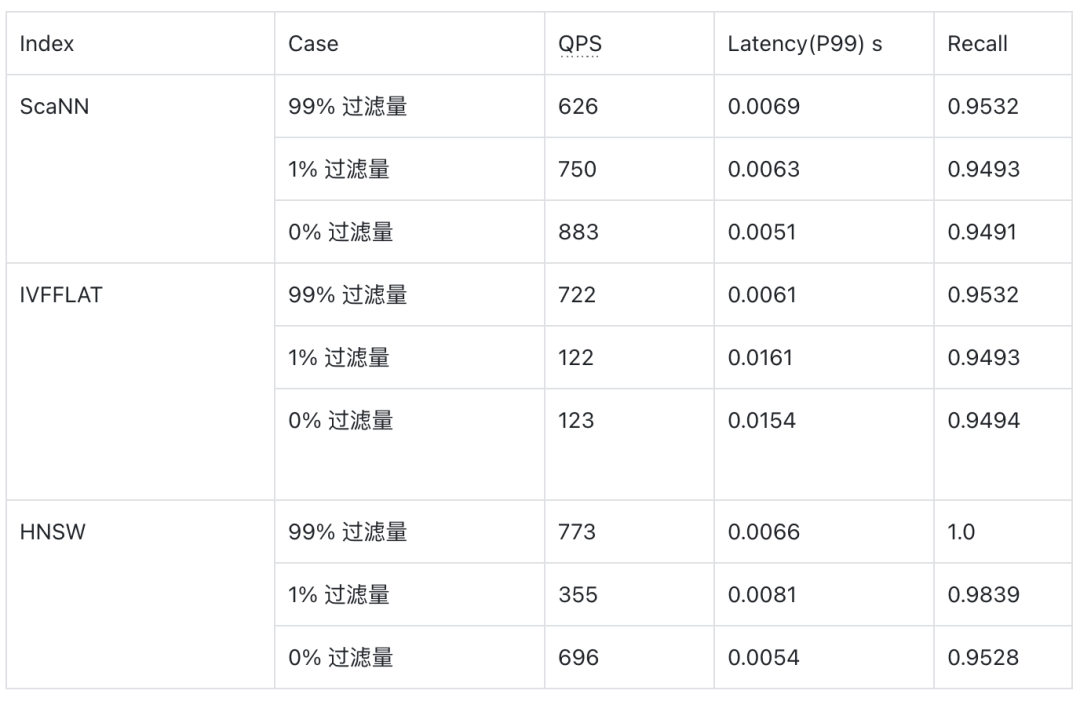
下表是 ScaNN、HNSW 和 IVFFLAT 在 Cohere1M(768维)的数据集下的性能表现,数据来自于 VectorDBBench。
-
Iterator
Pymilvus 中提供了 iterator接口,可以通过迭代器的方式拉取数据,Query 和 Range Search 场景下,通过迭代器可以获取超过 16384 条数据限制的数据。Iterator 类似于 ES 的 scroll 接口和关系数据库中的 cursor,比较适合后台批

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











