







文章目录
一、AXI中的“顺序”
1. transaction ID
AXI的每个Channel都有ID信号,用于区分transaction的身份。围绕ID引申出transaction之间的顺序问题。
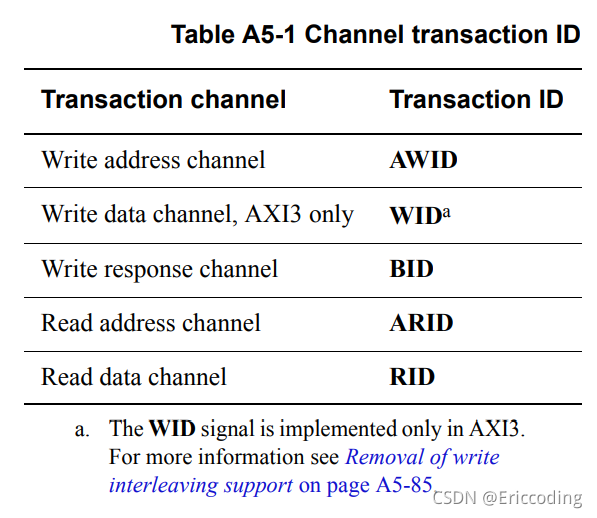
- Read transaction中,返回的读数据的RID需与相应读地址的ARID一致。
- Write transaction中,写数据的WID及写响应的BID需与相应写地址的AWID一致。
- Read transaction的ARID/RID与Write transaction的AWID/WID/BID即使相同也不具有相关关系。
2. 无需保序的情况
- 不同master发出的transaction之间没有保序要求。
- 不同ID的transaction之间没有保序要求。
- AWID与ARID相同的transaction之间没有保序要求。
3. 必须保序的情况
- 同一ARID的read transfer间需与address发出的顺序一致。
- 同一AWID的write transfer间需与address发出的顺序一致。
- 同一master发出的同一ID的transaction可能访问不同的slave,返回的RDATA或BRESP需
* 有关transaction/burst、transfer/beat的概念可见我的AXI系列笔记另一篇blog:《AXI总线的Burst Type以及地址计算 | WRAP到底是怎么一回事?》
4. 从interconnect的角度看ID
- 为ARID/AWID/WID额外增加master标识位,表示ID的master归属,master端无需了解其他master的ID。因此slave端收到的实际ARID/AWID/WID的位宽比master端发出的更大。
- 为RID/BID额外增加master标识位,表示RDATA或BRESP的去向。
- 同一master发出的同一ID的transaction可能访问不同的slave(根据地址范围判断,因此每笔transaction的地址范围不能超过单个slave所占有的地址范围),返回时interconnect需保证顺序与发出的addr一致。
二、Out of Order 乱序机制
1、什么是out of order乱序机制
既然 <一> 中提到了无需保序的几个类型,那么AXI的乱序机制也自然出自其中:
- 读乱序:对于read transaction,如果一个slave连续收到多个ARID不同的transaction(未必来自同一个master,满足了<一. 2>中前两条的情况),而slave返回读数据transaction时其RID的顺序与master发出的ARID顺序不同,则称为读乱序。

由上图的例子可见(略去握手信号),当slave连续收到ARID分别为ID0和ID1的读请求,由于未知原因,对ID1的响应速度比对ID0更快,slave可以先返回RID为ID1的读数据,再返回RID为ID0的读数据。读乱序机制可以提高总线的性能。如果严格保序,RID为ID1的读数据需等到ID0的读数据都返回之后才可返回,明显造成了性能的浪费。
其中读乱序的深度由read data reordering depth决定,代表slave中允许pending的adress个数。当read data reordering depth = 1时代表不允许读乱序。 - 写乱序:对于write transaction,如果一个slave连续收到多个AWID/WID不同的transaction(未必来自同一个master,满足了<一. 2>中前两条的情况),而slave返回BRESP时其BID与master发出的AWID/WID不同,则称为写乱序。
可以发现,乱序机制主要针对的是slave端,而与master的行为无关。
2、什么是interleaving交织机制
- 读交织:简单来说,读交织是out of order乱序的其中一种实现形式。<二.1>读乱序的例子展示的是transaction粒度的乱序,读交织进一步允许transfer粒度的乱序。是否支持读交织只与slave的设计有关。

如图所示,slave在返回了一个RID为ID2的读数据后,中间间插返回了ID0与ID1的读数据,最后才返回一个的ID2的读数据。但同一RID的读数据之间需要保序。由此可见,在读交织机制下,同一个transaction中间插了来自其他transaction的transfer,所以乱序的粒度是transfer级的。
* 有关transaction/burst、transfer/beat的概念可见我的AXI系列笔记另一篇blog:《AXI总线的Burst Type以及地址计算 | WRAP到底是怎么一回事?》 - 写交织:类似于读交织,每个transaction的写数据也会有一个WID,不同WID的写数据transfer可以间插发送。但同一WID的写数据之间需要保序。此时,乱序的粒度也精确到了transfer级。值得注意的是,相比于读交织,写交织还有两点额外的要求:
- 虽然允许不同WID的写交织,但是每笔transaction的第一个transfer需与写请求(AW req)发送的顺序严格一致。
- 为了避免死锁dead lock,支持写交织的slave必须一直支持写交织,不能某些时候支持,而某些时候不支持。 - 写交织在AXI4中被弃用:AMBA protocol中明确指出,在AXI3中所支持的write interleaving机制在AXI4中不再支持。也就是说,在AXI4中,写乱序只能在transaction粒度上进行,无法再精确到transfer粒度。
- WID的删除:transaction粒度的乱序,只需要用每笔transaction的写响应BID进行描述,而每个写数据transfer是不允许间插交织的,于是AXI4中也删除了W channel中的WID信号。
- AXI4不支持写交织的原因:AMBA protocol中并未对此给出明确的解释。但是仔细阅读写交织的描述,可以发现:
1)其相较于读交织有着额外的要求,这也意味着要实现写交织,在总线系统设计中需要增加复杂的逻辑,且容易产生死锁。2)对于同一master,master可以自行规划写数据的顺序(比如将不同写事务进行拆解重组),达到与写交织一样的效果。而只有在多master,且master的写速度不同时,写交织才能够派上用场,因此写交织的应用场景也不够广泛。
总结
- AXI的读写事务可以通过ID来进行区分,从而引入顺序的概念。
- out of order与interleaving的区别在于前者是transaction粒度的乱序,而后者是transfer粒度的乱序,可以说后者是前者的一种实现方式。
- 是否支持乱序只与slave有关,与master无关。
- AXI3中支持写交织,而AXI4中不再支持写交织。

















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









