







元学习中数据集的划分,依据论文剖析元任务,支持集,查询集
文章目录
前言
本文依据一篇中文核心期刊来聊聊元学习中的数据集划分,论文是小样本下基于原型网络的轴向柱塞泵故障诊断模型
一、数据集以及数据集的划分

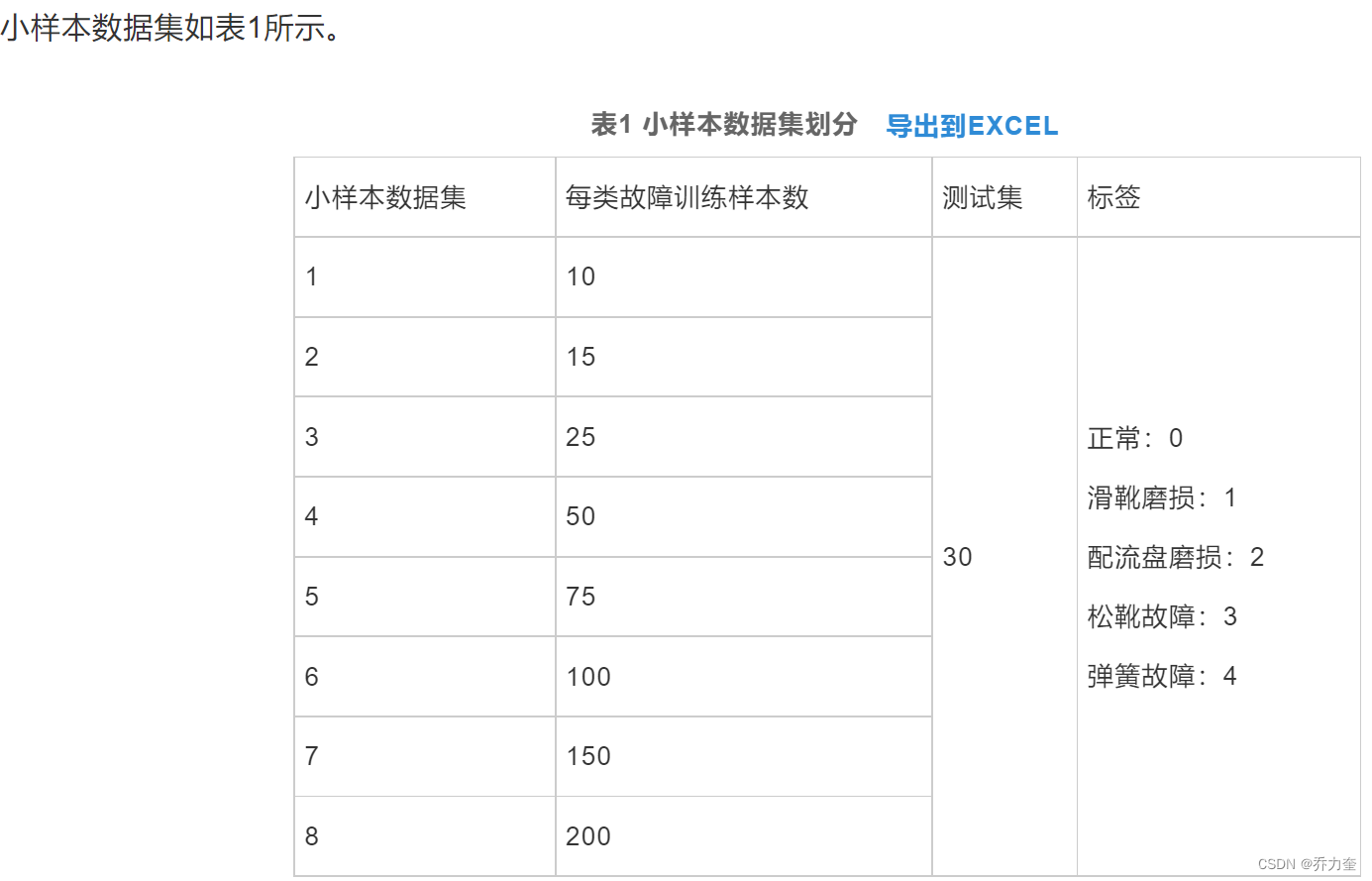
二、训练阶段的任务,支持集,查询集的使用

三、测试阶段的任务,支持集,查询集的使用

总结—以及我对元学习中任务,支持集,查询集的理解
-
深度学习需要海量的数据来进行训练模型,使模型能够在回归与分类问题上有着优良的表现。但是在实际问题中,往往没有那么多数据,这就引出了元学习。利用少量的数据来使模型在回归与分类问题上处理的很好,但是数据少,如何才能表现好呢,这就需要使模型学会学习,当一个模型拥有了学会学习的能力,他就会面对新的任务也能够表现良好,具体的来说就是通过少量的样本使模型学会这些数据层面的知识,而不仅仅是数据中的具体内容,如数据的分布、不同数据的特征表示。
-
为了让模型依据少量的数据学会学习,我们需要对这些少量的数据进行打包处理,把他们变成一个个的任务,我们结合一个具体的实例,来介绍元学习中任务,支持集,查询集的构造过程。
-
有一个图像数据集叫:Omniglot,Omniglot包含1623个不同的火星文字符,每个字符包含20个手写的case。这个任务是判断每个手写的case属于哪一个火星文字符。如果我们要进行N-ways,K-shot(数据中包含N个字符类别,每个字符有K张图像)的一个图像分类任务。比如20-ways,1-shot分类的意思是说,要做一个20分类,但是每个分类下只有1张图像的任务。我们可以依据Omniglot构建很多N-ways,K-shot任务,这些任务将作为元学习的任务来源。构建的任务分为训练任务(Train Task),测试任务(Test Task)。每个任务包含自己的训练数据、测试数据,在元学习里,分别称为Support Set和Query Set。

















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









