






大模型推理优化技术概述
KVcache一句话总结:
KV cache其实就是通过空间换取时间的方式,通过缓存Attention中的K和V来实现推理优化。
注意力机制
公式
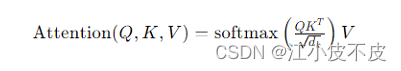
其中:
- Q 表示查询(Query)矩阵
- K 表示键(Key)矩阵
- V 表示值(Value)矩阵
- dk 是键向量的维度,用于缩放因子,防止内积后的数值过大导致梯度消失问题
- softmax函数是用来归一化权重的
计算过程
- 矩阵乘法(QKT):首先,计算查询矩阵Q和键矩阵K的转置的点积。这一步是为了计算每个查询和所有键之间的相似度。
- 缩放(除以 dk):将上述点积的结果除以dk的值。这一步是为了控制点积的大小,防止梯度在训练过程中消失。
- 应用softmax函数:接着对每一行应用softmax函数,将点积的结果转换成概率形式(即注意力权重)。这些权重表示了在计算最终输出时,各个值的重要程度。
- 加权和(乘以 V):最后,将这些注意力权重应用于值矩阵V。通过加权求和的方式,合成最终的输出。权重较大的值会在输出中占据更主要的位置,这样模型就可以关注对当前任务更重要的信息。
KV cache背景
在探讨模型推理的效率时,我们面临一个关键问题:每次推理都输入完整的前文数据是一种资源消耗较大的做法。这种方法导致了大量的冗余计算,因为当文本长度从S增加到S+1时,对于前S个token的处理(包括Embedding映射、KQV映射、注意力权重计算、以及前馈网络(FFN)层的操作)在连续的推理过程中是重复的。这种重复是由于模型参数是固定的,每次的计算结果是一样的。
理想情况下,我们可能会考虑只输入新的token(即第S+1个token)来减少计算负担。然而,这种方法在实际应用中是行不通的。尽管最终输出似乎只由最后一个token决定,但注意力机制的实质是依赖于整个序列的,它需要利用前文中的Key和Value向量来有效载入并处理历史信息。因此,不能简单地忽略前面的文本数据。
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/3362602ff0022ef16d628edc2b3d4825.png)
在每一步生成中,仅使用输入序列中的最后一个token的注意力表示,即可预测出下一个token。但模型还是并行计算了所有token的注意力表示,其中产生了大量冗余的计算(包含qkv映射,attention计算等),并且输入的长度越长,产生的冗余计算量越大。
KV cache 计算过程
b j = ∑ i = 1 n s o f t m a x ( q j ⋅ k i ) v i b^j= ∑^{n}_{i=1}softmax(q^j⋅k^i)v^i bj=i=1∑nsoftmax(qj⋅ki)vi
输入:中国的首都
预测:是
- 计算中国的首都每个token的k,v,以及对应的注意力计算结果b1,b2,b3。
- 使用b3预测下一个token,得到:是。
- 缓存[k1,k2,k3],[v1,v2,v3]
输入:中国的首都是
预测:北
- 计算是的,q,k,v。
- 更新缓存[k1,k2,k3,k4],[v1,v2,v3,v4]
- 计算b4,预测下一个token,得到北。
输入:中国的首都是北
预测:京
- 计算北的,q,k,v。
- 更新缓存[k1,k2,k3,k4,k5],[v1,v2,v3,v4,v5]
- 计算b5,预测下一个token,得到京。
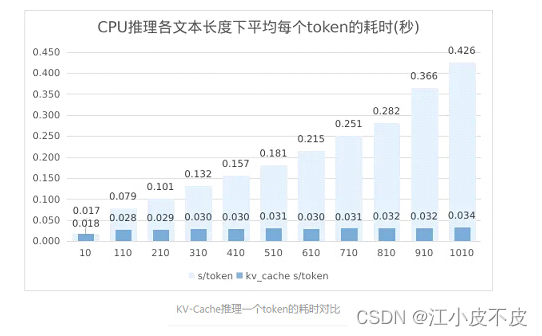
统计图如下,当关闭KV-Cache时,随着文本长度从10增长到1000,推理一个token从17ms增长到426ms,推理步长越大,效率越来越低,而当开启KV-Cache时,推理一个token的耗时基本稳定维持在30ms左右,只呈现出小数点后第三位上的略微增长趋势,推理长度几乎没有对推理效率产生负面影响。
缺点
用KV cache做推理时的一些特点:
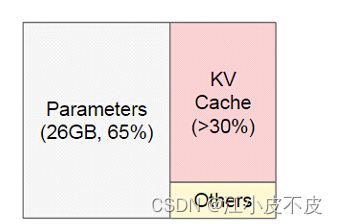
- 随着prompt数量变多和序列变长,KV cache也变大,对gpu显存造成压力
- 由于输出的序列长度无法预先知道,所以我们很难提前为KV cache量身定制存储空间
PageAttention
论文地址:
https://arxiv.org/abs/2309.06180
概述
大型语言模型 (LLM) 的高吞吐量服务需要一次批处理足够多的请求。然而,现有系统很困难,因为每个请求的键值缓存(KV 缓存)内存很大,并且会动态增长和收缩。如果管理效率低下,这些内存可能会因碎片和冗余重复而被严重浪费,从而限制了批处理大小。为了解决这个问题,我们提出了 PagedAttention,这是一种受操作系统中经典虚拟内存和分页技术启发的注意力算法。在此基础上,我们构建了 vLLM,这是一个 LLM 服务系统,它实现了(1)KV cache内存几乎为零的浪费,以及(2)在请求内和请求之间灵活共享 KV cache,以进一步减少内存使用。我们的评估表明,与最先进的系统(例如 FasterTransformer 和 Orca)相比,在相同延迟水平下,vLLM 将流行 LLM 的吞吐量提高了 2-4倍。对于更长的序列、更大的模型和更复杂的解码算法,这种改进更加明显。
背景:
- KV cache内存的巨大需求:每个请求的KV缓存内存需求巨大,且随请求数量增加而快速增长。
- 内存碎片化和冗余占用:现有系统的内存管理不善,导致大量内存碎片和冗余占用,限制了批处理大小。
解决方法:
PagedAttention通过将KVcache划分为固定大小的块进行存储,这些块可以在非连续的物理内存空间中存储,从而减少内存碎片并允许跨请求共享内存。具体步骤如下: - 分块存储:将请求的KVcache划分为固定大小的块,每个块包含一定数量的键值对。
- 非连续存储:这些块可以存储在非连续的物理内存空间中,灵活分配内存。
- 内存共享:允许跨请求共享KVcache块,提高内存利用率。
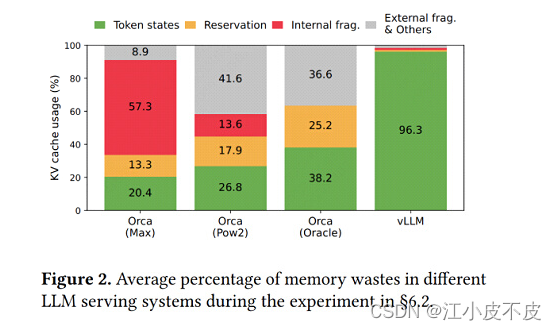
常规KV cache存储分配
通过下图可以看出,常规kv cache,造成了极大的显存资源浪费。

单个请求
通过虚拟表进行映射,更合理的分配显存。
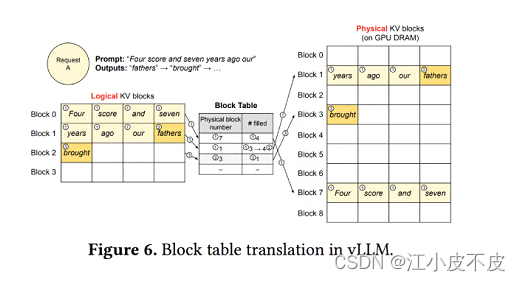
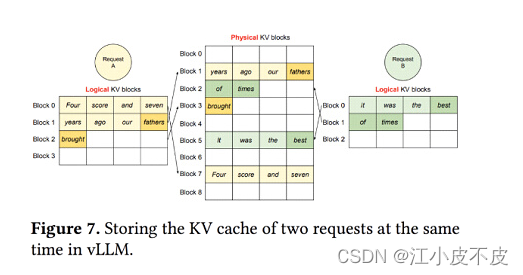
多个请求
多个请求到来的时候,充分利用显存空间
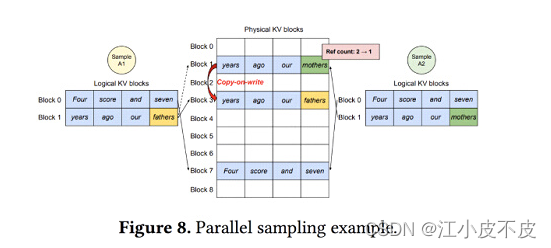
共享内存
对于相同的请求进行共享显存,更多应用在让大模型生成多个回答,以及使用思维树的时候。
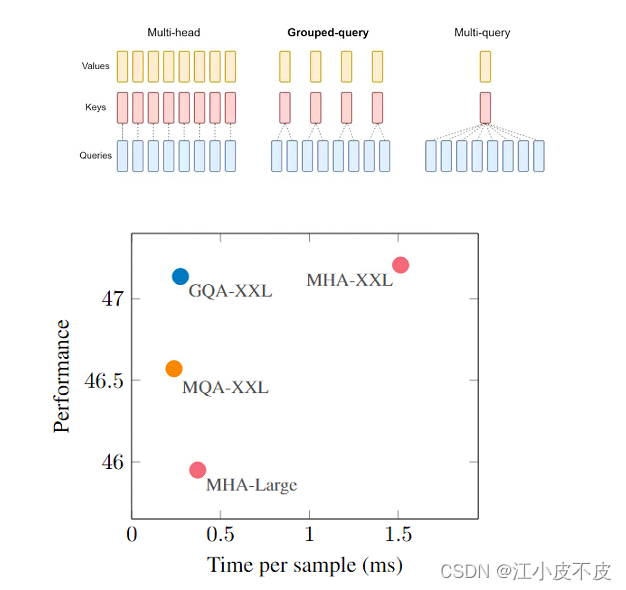
MHD、MQA、GQA注意力机制
GQA论文地址:
https://arxiv.org/pdf/2305.13245
- Llama 2 系列模型。更大的模型(70B)使用分组查询注意 (GQA) 来提高推理可扩展性。
- Llama 3 系列模型。8 和 70B 版本均使用分组查询注意 (GQA) 来提高推理可扩展性。
- Qwen2 等模型
MHA
多头注意力机制是Transformer模型中的核心组件。在其设计中,"多头"意味着该机制并不只计算一种注意力权重,而是并行计算多种权重,每种权重都从不同的“视角”捕获输入的不同信息。
- hidden_state经过线性层得到q、k、v
- q、k、v经过split后增加一个维度:num_heads
- q、k计算注意力分数score
- softmax对注意力分数进行归一化得到注意力权重attention_probs
- 用注意力权重和值计算输出:output
- 对注意力输出进行拼接concat
import torch
from torch import nn
class MutiHeadAttention(torch.nn.Module):
def __init__(self, hidden_size, num_heads):
super(MutiHeadAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
## 初始化Q、K、V投影矩阵
self.q_linear = nn.Linear(hidden_size, hidden_size)
self.k_linear = nn.Linear(hidden_size, hidden_size)
self.v_linear = nn.Linear(hidden_size, hidden_size)
## 输出线性层
self.o_linear = nn.Linear(hidden_size, hidden_size)
def forward(self, hidden_state, attention_mask=None):
batch_size = hidden_state.size()[0]
query = self.q_linear(hidden_state)
key = self.k_linear(hidden_state)
value = self.v_linear(hidden_state)
query = self.split_head(query)
key = self.split_head(key)
value = self.split_head(value)
## 计算注意力分数
attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))
if attention_mask != None:
attention_scores += attention_mask * -1e-9
## 对注意力分数进行归一化
attention_probs = torch.softmax(attention_scores, dim=-1)
output = torch.matmul(attention_probs, value)
## 对注意力输出进行拼接
output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)
output = self.o_linear(output)
return output
def split_head(self, x):
batch_size = x.size()[0]
return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)
MQA
多查询注意力(MQA)可能导致质量下降和训练不稳定,并且训练针对质量和推理优化的单独模型可能不可行。此外,虽然一些语言模型已经使用了多查询注意力,如PaLM但许多语言模型没有,包括公开可用的语言模型,如T5和LLaM.
- hidden_state经过线性层得到q、k、v
- q、k、v经过split后增加一个维度:num_heads(q = num_heads,k=1,v=1)。相当于多个query,即多查询。
- q、k计算注意力分数score
- softmax对注意力分数进行归一化得到注意力权重attention_probs
- 使用注意力权重和值计算输出:output
- 对注意力输出进行拼接concat
import torch
from torch import nn
class MutiQueryAttention(torch.nn.Module):
def __init__(self, hidden_size, num_heads):
super(MutiQueryAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
## 初始化Q、K、V投影矩阵
self.q_linear = nn.Linear(hidden_size, hidden_size)
self.k_linear = nn.Linear(hidden_size, self.head_dim) ###
self.v_linear = nn.Linear(hidden_size, self.head_dim) ###
## 输出线性层
self.o_linear = nn.Linear(hidden_size, hidden_size)
def forward(self, hidden_state, attention_mask=None):
batch_size = hidden_state.size()[0]
query = self.q_linear(hidden_state)
key = self.k_linear(hidden_state)
value = self.v_linear(hidden_state)
query = self.split_head(query)
key = self.split_head(key, 1)
value = self.split_head(value, 1)
## 计算注意力分数
attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))
if attention_mask != None:
attention_scores += attention_mask * -1e-9
## 对注意力分数进行归一化
attention_probs = torch.softmax(attention_scores, dim=-1)
output = torch.matmul(attention_probs, value)
output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)
output = self.o_linear(output)
return output
def split_head(self, x, head_num=None):
batch_size = x.size()[0]
if head_num == None:
return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)
else:
return x.view(batch_size, -1, head_num, self.head_dim).transpose(1,2)
GQA
引入分组查询注意力 (GQA),这是多 头语言模型的泛化。查询注意力,它使用多于一个,少于查询头数量的键值头。经过训练的GQA 实现了接近多头注意力 的质量,并且速度与 MQA 相当。
- hidden_state经过线性层得到q、k、v
- q、k、v经过split后增加一个维度:num_heads(q = num_heads,k=group_num,v=group_num)。相当于把多头分组了,比如原先有10个头,那就是10个query,分成5组,每组2个query,1个value,1个key。
- q、k计算注意力分数score
- softmax对注意力分数进行归一化得到注意力权重attention_probs
- 使用注意力权重和值计算输出:output
- 对注意力输出进行拼接concat
import torch
from torch import nn
class MutiGroupAttention(torch.nn.Module):
def __init__(self, hidden_size, num_heads, group_num):
super(MutiGroupAttention, self).__init__()
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
self.group_num = group_num
## 初始化Q、K、V投影矩阵
self.q_linear = nn.Linear(hidden_size, hidden_size)
self.k_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)
self.v_linear = nn.Linear(hidden_size, self.group_num * self.head_dim)
## 输出线性层
self.o_linear = nn.Linear(hidden_size, hidden_size)
def forward(self, hidden_state, attention_mask=None):
batch_size = hidden_state.size()[0]
query = self.q_linear(hidden_state)
key = self.k_linear(hidden_state)
value = self.v_linear(hidden_state)
query = self.split_head(query)
key = self.split_head(key, self.group_num)
value = self.split_head(value, self.group_num)
## 计算注意力分数
attention_scores = torch.matmul(query, key.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.head_dim))
if attention_mask != None:
attention_scores += attention_mask * -1e-9
## 对注意力分数进行归一化
attention_probs = torch.softmax(attention_scores, dim=-1)
output = torch.matmul(attention_probs, value)
output = output.transpose(-1, -2).contiguous().view(batch_size, -1, self.head_dim * self.num_heads)
output = self.o_linear(output)
return output
def split_head(self, x, group_num=None):
batch_size,seq_len = x.size()[:2]
if group_num == None:
return x.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1,2)
else:
x = x.view(batch_size, -1, group_num, self.head_dim).transpose(1,2)
x = x[:, :, None, :, :].expand(batch_size, group_num, self.num_heads // group_num, seq_len, self.head_dim).reshape(batch_size, self.num_heads // group_num * group_num, seq_len, self.head_dim)
return x
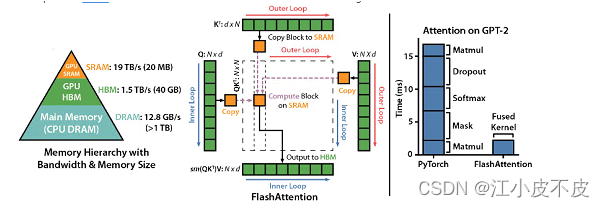
Flash Attention
论文地址:
https://arxiv.org/abs/2205.14135
本质上是通过重计算。把矩阵计算中的QKV进行拆分,复制到SRAM中,进行计算,再取出来。


















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











