







使用YOLO Pose和SVM进行动作分类识别的教程
在本文中,我们将探讨如何将YOLO Pose与支持向量机(SVM)结合,进行人体动作分类识别。YOLO Pose作为一个优秀的姿态估计工具,能够提取人体的关键点,而支持向量机(SVM)则是一种强大的监督学习模型,能够根据提取的特征对动作进行分类。通过这两个工具的结合,我们可以实现高效的动作识别。
1. 项目概述
动作识别(Action Recognition)是计算机视觉领域的重要任务之一,广泛应用于安防监控、运动分析和人机交互等领域。YOLO Pose可以从视频帧中实时提取人体姿态信息,而SVM则用于基于这些姿态特征进行分类。在此过程中,YOLO Pose负责检测人体关键点,SVM根据这些关键点进行分类。
2. 环境搭建
2.1 安装必要的库
首先,确保安装了以下库:
- OpenCV:用于处理视频和图像。
- PyTorch:用于深度学习模型。
- scikit-learn:用于实现SVM分类器。
- YOLO Pose:用于姿态估计。
使用以下命令安装所需的库:
pip install opencv-python torch torchvision torchaudio scikit-learn
2.2 下载YOLO Pose模型
YOLO Pose是YOLO系列模型的一种,能够实时进行人体姿态估计。我们可以使用YOLO Pose的开源实现(如进行姿态估计。
cd yolov7
pip install -r requirements.txt
下载预训练的YOLO Pose模型并测试。
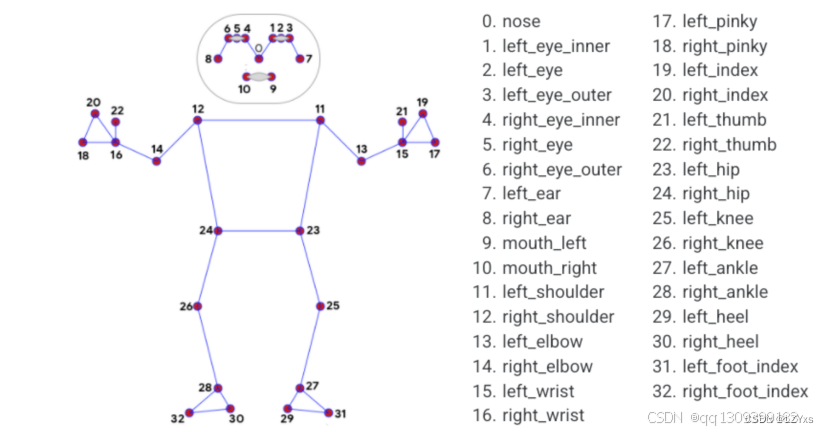
3. 姿态估计
YOLO Pose模型的核心功能是从图像或视频中提取人体的关键点。具体步骤如下:
3.1 加载YOLO Pose模型
首先,加载YOLO Pose模型。以下是一个示例代码,展示如何使用YOLO Pose模型进行姿态估计。
import torch
from pathlib import Path
import cv2
import numpy as np
# 加载YOLOv7模型
model = torch.hub.load('WongKinYiu/yolov7', 'yolov7', pretrained=True)
# 加载图像
img_path = "path_to_image.jpg"
img = cv2.imread(img_path)
# 将图像转化为RGB并传入模型
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
results = model(img_rgb)
# 提取关键点
keypoints = results.pandas().xywh[0]['keypoints'] # 获取检测到的人体关键点
print(keypoints)
在YOLO Pose模型中,keypoints将返回一个包含检测到的人体关节点坐标的数据框(DataFrame)。

3.2 关键点提取
YOLO Pose将每个检测到的人的关节点坐标提供给我们。这些坐标可以包括头部、肩膀、肘部、膝盖等。为了将这些关节点作为特征传入SVM,我们需要选择一些代表性特征,例如各个关节点之间的相对位置关系和角度。
# 提取关键点并构建特征向量
keypoints = np.array(keypoints).reshape(-1, 2) # 假设是 (num_keypoints, 2)
features = []
# 计算关节点之间的距离
for i in range(len(keypoints)):
for j in range(i + 1, len(keypoints)):
distance = np.linalg.norm(keypoints[i] - keypoints[j]) # 计算欧氏距离
features.append(distance)
# 将特征向量作为SVM输入
features = np.array(features)
4. 支持向量机(SVM)分类器
支持向量机(SVM)是一个强大的分类器,尤其在高维空间中表现出色。SVM的目标是找到一个超平面,将不同类别的样本分开。我们将使用SVM根据YOLO Pose提取的特征进行动作分类。
4.1 数据准备
为了训练SVM模型,我们需要一个包含标签的训练集。每个训练样本应该包含提取的特征以及对应的动作标签。
from sklearn import svm
from sklearn.model_selection import train_test_split
# 假设features包含提取的特征,labels包含对应的动作标签
features = np.array(features)
labels = np.array([0, 1, 2, 3]) # 举例:0-走路, 1-跑步, 2-跳跃, 3-坐下
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2)
4.2 训练SVM模型
4.3 分类预测
svm训练代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report
import joblib # 用于保存和加载模型
# 1. 加载数据
data = pd.read_csv('data.csv') # 假设数据存储在 'data.csv' 文件中
# 2. 提取特征和标签
X = data[['wrist', 'hp', 'hand']] # 特征列
y = data['class'] # 标签列
# 3. 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 4. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 5. 构建SVM模型并训练
model = SVC(kernel='linear') # 使用线性核的SVM模型
model.fit(X_train, y_train)
# 6. 评估模型
y_pred = model.predict(X_test)
print("分类报告:\n", classification_report(y_test, y_pred))
# 7. 保存模型和标准化器
joblib.dump(model, 'svm_model.pkl') # 保存训练好的模型
joblib.dump(scaler, 'scaler.pkl') # 保存标准化器
svm推理代码
import joblib
import numpy as np
# 1. 加载保存的模型和标准化器
model = joblib.load('svm_model.pkl') # 加载训练好的模型
scaler = joblib.load('scaler.pkl') # 加载标准化器
# 2. 准备新数据
new_data = np.array([[10, 20, 30]]) # 新数据:wrist=10, hp=20, hand=30
# 3. 对新数据进行标准化(与训练数据使用相同的标准化器)
new_data_scaled = scaler.transform(new_data)
# 4. 进行预测
prediction = model.predict(new_data_scaled)
# 5. 输出预测结果
print("预测结果:", prediction) # 输出预测结果(0 或 1)
一旦模型训练完毕,我们可以用它对新的样本进行预测。

5. 结果可视化
为了更直观地理解分类效果,可以将识别出的动作与原始视频或图像进行可视化。可以在图像上显示关键点并标注动作类别。
# 可视化结果
for keypoint in keypoints:
cv2.circle(img, (int(keypoint[0]), int(keypoint[1])), 5, (0, 255, 0), -1)
# 在图像上显示动作类别
action = predictions[0] # 假设这是第一个样本的预测
cv2.putText(img, f"Action: {action}", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
# 显示图像
cv2.imshow("Action Recognition", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
6. 进一步优化
6.1 增强数据集
为了提高模型的准确性,您可以通过数据增强(如旋转、缩放、平移等)扩充训练数据集。这有助于提升模型的鲁棒性,尤其在面对不同的姿态和角度时。
6.2 特征选择与降维
SVM的性能会受到特征数量和质量的影响。您可以使用PCA(主成分分析)等方法进行特征降维,减少冗余特征,提高计算效率。
6.3 深度学习替代SVM
如果你发现SVM的效果不够好,可以尝试使用深度学习方法(如卷积神经网络CNN或长短期记忆网络LSTM)来替代SVM,以更好地捕捉时间序列中的动态特征。
7. 总结
本教程展示了如何结合YOLO Pose进行人体姿态估计,并使用支持向量机(SVM)进行动作分类。YOLO Pose提供了人体的关键点信息,而SVM则根据这些关键点提取特征来分类不同的动作。这种方法结合了YOLO Pose的高效检测能力和SVM的强大分类性能,可以实现较为精准的动作识别。
未来,您可以进一步优化模型,通过数据增强、深度学习方法和其他高级技术提升识别精度和系统的实用性。


















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









