









 该博客介绍了CVPR2018年Adobe提出的一种图像篡改检测方法,利用RGB流和噪声流的双流Faster R-CNN,并采用bilinear pooling层。通过在公开数据集上的实验,该方法展现出对图像缩放和压缩的鲁棒性,且精度高于其他方法。论文提供了GitHub代码实现,可用于直接应用或进一步研究。
该博客介绍了CVPR2018年Adobe提出的一种图像篡改检测方法,利用RGB流和噪声流的双流Faster R-CNN,并采用bilinear pooling层。通过在公开数据集上的实验,该方法展现出对图像缩放和压缩的鲁棒性,且精度高于其他方法。论文提供了GitHub代码实现,可用于直接应用或进一步研究。
论文: Learning Rich Features for Image Manipulation Detection
GitHub:https://github.com/LarryJiang134/Image_manipulation_detection
https://github.com/WaLittleMoon/Learning-Rich-Features-for-Image-Manipulation-Detection
CVPR2018 Adobe出品

图像篡改检测,有别于传统的目标检测。图像篡改包含了图像拼接,图像复制黏贴,图像去除等等操作。
本文基于RGB流(RGB stream)和噪声流(noise stream),提出了双流Faster-RCNN的图像篡改检测。并且使用 bilinear pooling layer替代Faster-RCNN中的roi pooling。在公开数据集上取得了 state-of-the-art的效果。并且该方法对图片缩放,压缩具有很强的鲁棒性。
主要贡献:
- 展示了如何将Faster-RCNN应用于图像篡改。通过 bilinearly pooling 操作融合RGB特征和基于 steganalysis rich model (SRM) 的噪声特征。
- 相比于其他的图像篡改检测方法,本文的方法具有更高的精度。
网络结构:
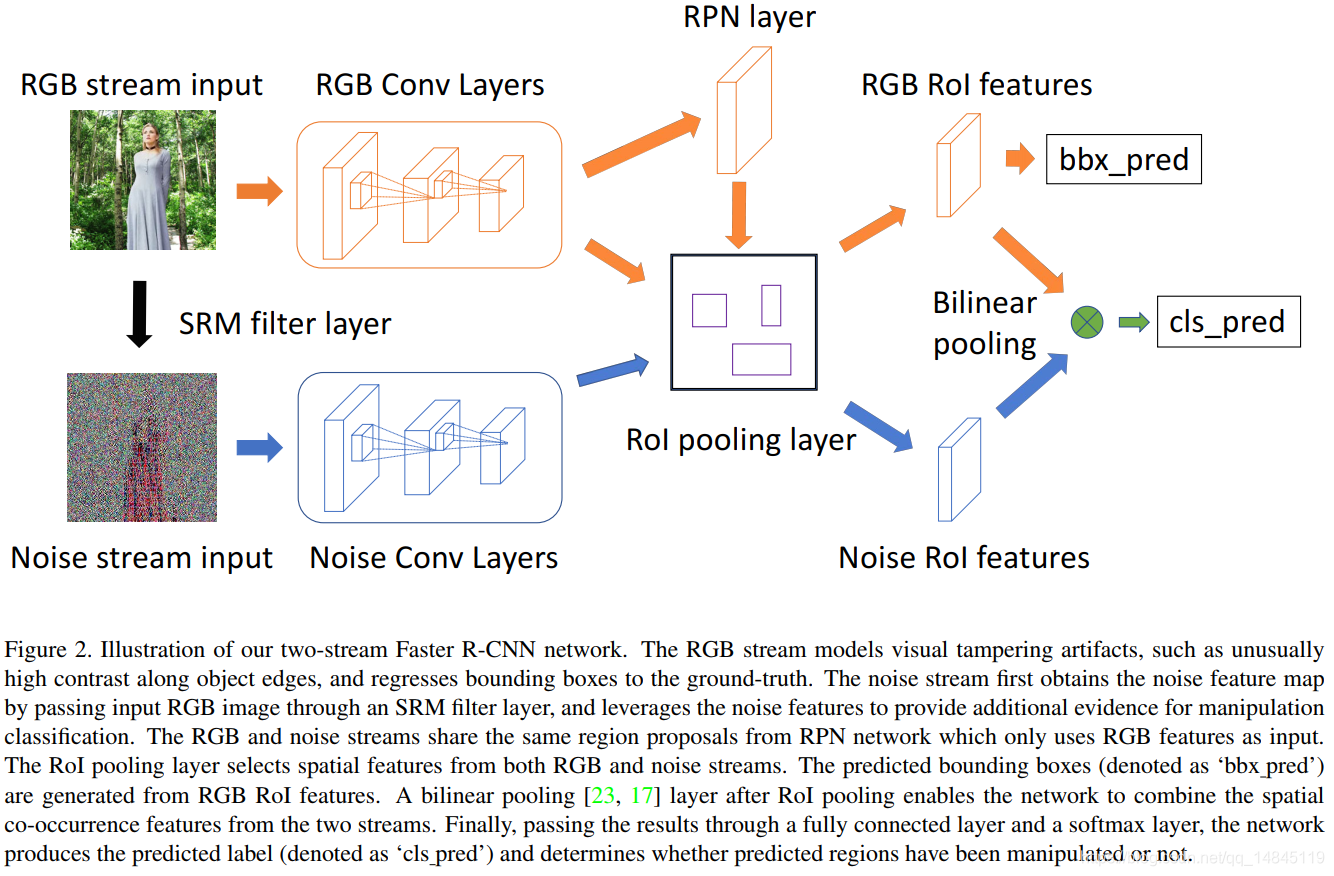
整个网络包含2个输入,第一个为rgb图片输入,第二个为噪声流输入。噪声流通过使用SRM滤波方法得到。
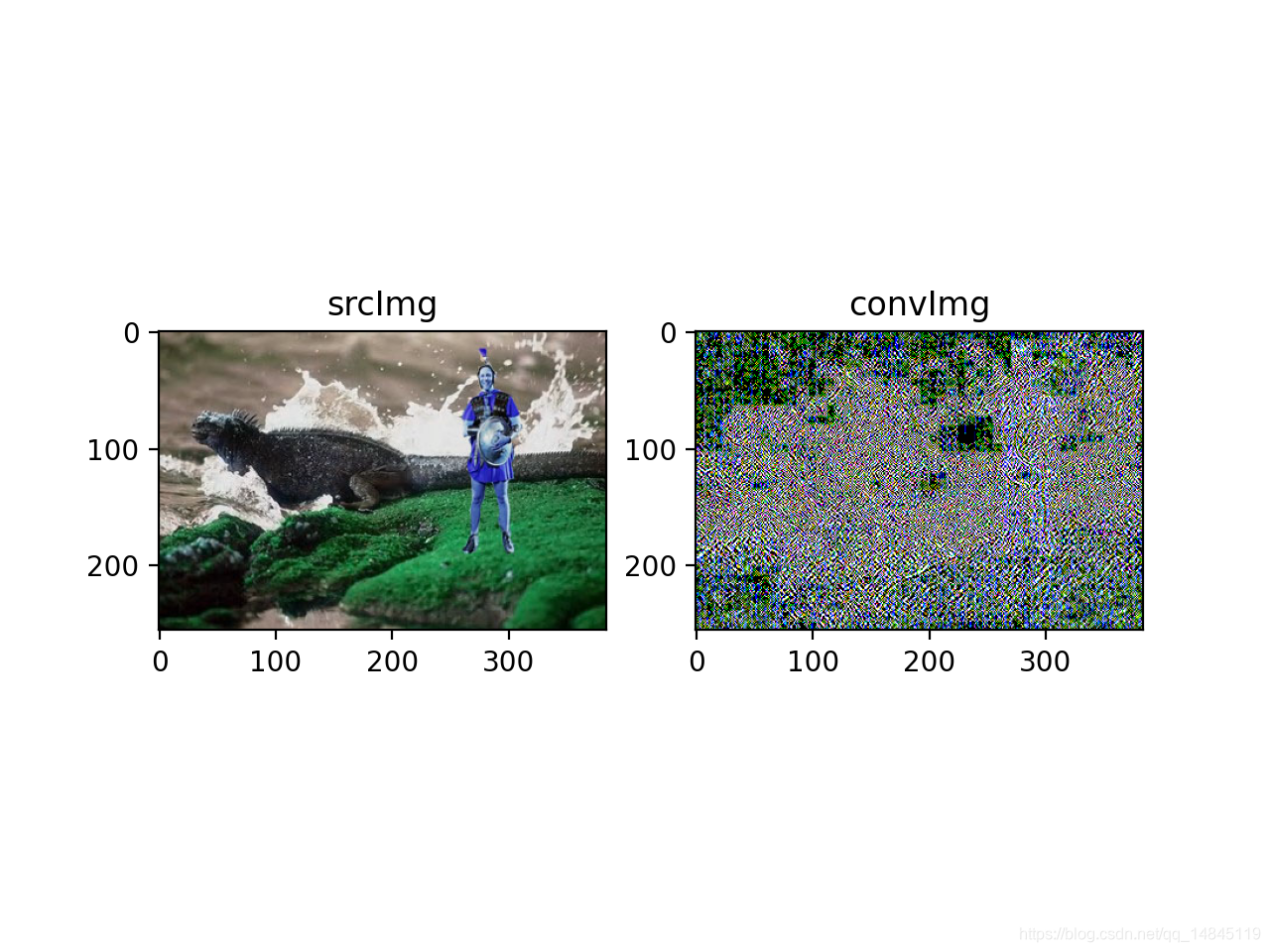
通过实验证实,在SRM方法中仅仅使用3个滤波器也可以达到和使用30个滤波器相同的效果。最终使用 5 × 5 × 3的滤波器。

参考代码:
import numpy as np
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('Sp_D_NRN_A_ani0056_cha0062_0437.jpg',1)
kernal = np.array([[[0,0,0,0,0],[0,-1/4,2/4,-1/4,0],[0,2/4,-4/4,2/4,0],[0,-1/4,2/4,-1/4,0],[0,0,0,0,0]],
[[-1/12,2/12,-2/12,2/12,-1/12],[2/12,-6/12,8/12,-6/12,2/12],[-2/12,8/12,-12/12,8/12,-2/12],[2/12,-6/12,8/12,-6/12,2/12],[-1/12,2/12,-2/12,2/12,-1/12]],
[[0,0,0,0,0],[0,0,0,0,0],[0,1/2,-2/2,1/2,0],[0,0,0,0,0],[0,0,0,0,0]]])
dst_r = (cv2.filter2D(img[:,:,0], -1, kernal[0,:,:]) + cv2.filter2D(img[:,:,1], -1, kernal[0,:,:]) + cv2.filter2D(img[:,:,2], -1, kernal[0,:,:]))/3
dst_g = (cv2.filter2D(img[:,:,0], -1, kernal[1,:,:]) + cv2.filter2D(img[:,:,1], -1, kernal[1,:,:]) + cv2.filter2D(img[:,:,2], -1, kernal[1,:,:]))/3
dst_b = (cv2.filter2D(img[:,:,0], -1, kernal[2,:,:]) + cv2.filter2D(img[:,:,1], -1, kernal[2,:,:]) + cv2.filter2D(img[:,:,2], -1, kernal[2,:,:]))/3
dst = cv2.merge([dst_r, dst_g, dst_b])
titles = ['srcImg','convImg']
imgs = [img, dst]
# 画图进行展示
for i in range(2):
plt.subplot(1,2,i+1)
plt.imshow(imgs[i])
plt.title(titles[i])
plt.show()效果:
然后两个输入都基于卷积网络进行处理。同样是根据实验证实,只对RGB分支进行RPN操作的效果最佳。

两个分支的特征,都经过bilinearly pooling后,进行了特征融合。Rgb的特征只进行矩形框的回归。Rgb+noise的特征进行分类操作,输出图片是否被篡改过。
损失函数:
RPN loss:
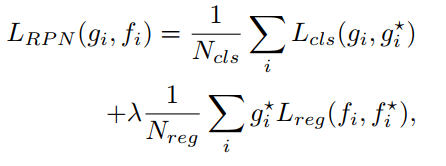
分类为交叉熵loss,回归为smooth L1。
λ为超参数,实际取值为10
整体loss:
![]()
整体loss包括RPN的loss,最终的分类loss,矩形框回归loss。
实验结果:


实验测试:

其他数据测试,

总结:
- 直接拿开源模型,在自己的数据集上实测,确实是有一些效果的。感觉如果结合自己的实际场景进行训练,应该是会有不错的效果。
- 基于vgg16作为backbone的网络有1.2G,确实模型比较大。

















 9014
9014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









