






写在前面的话:
适值毕业之季,因毕业论文的需要,又恰好看到这篇博文,写的甚是不错,因此,进行了翻译,作为我的第一篇博文。这里给出原作者Blog Address(http://www.erogol.com/brief-history-machine-learning/)。
欢迎转载,但转载之前请注明出处,谢谢。。。。
机器学习就是在非精确编程的情况下,让计算机根据训练过程进行自我学习的科学。在过去的十年中,机器学习极大的促进了好多高新技术的发展,包括无人驾驶、语音识别、网络搜索、人类基因组认知等。机器学习已经渗透进了人们生活的方方面面,我们无时无刻不在与之打交道。该领域的许多国内外研究学者认为,机器学习是让机器达到人类智能水平的最佳方式。有研究显示,在执行不同的任务中,机器学习已经达到与人类98.98%的相似度或者更高。
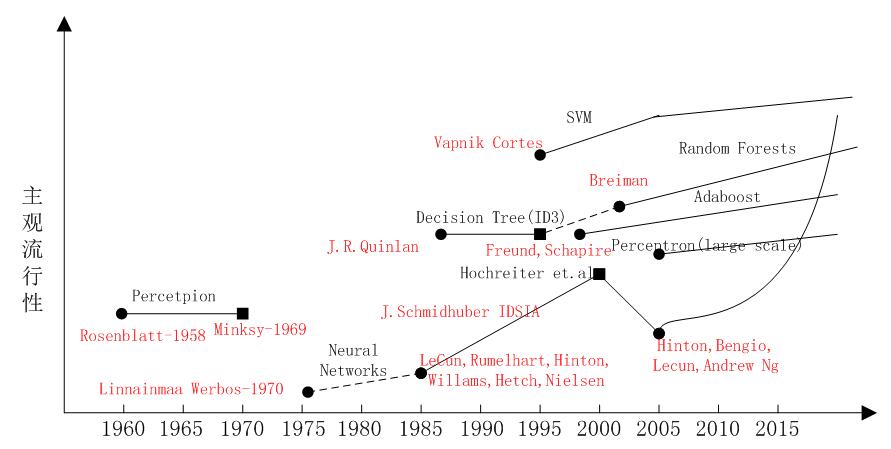
My subjective ML timeline (click for larger)
我的主观机器学习时间表
Since the initial standpoint of science, technology andAI, cientists following Blaise Pascal and Von Leibniz ponder about a machinethat is intellectually capable as much as humans. Famous writers likeJules Verne , Frank Baum (Wizard of OZ), Marry Shelly (Frankenstein), GeorgeLucas (Star Wars) dreamed artificial beings
resembling human behaviors or even more,swamp humanizedskills in different contexts.
本着科学、技术和人工智能最初的观点,科学家们跟随着布莱士·帕斯卡(制作了第一台数字计算器) 和冯莱布尼茨(德国古典哲学家)思考着一台在智力和能力上与人类平分秋色的机器。著名的作家像儒勒·凡尔纳(法国作家,被誉为“科幻小说之父”)、弗兰克·鲍姆(绿野仙踪),玛丽雪莱(怪人),乔治·卢卡斯(星球大战)梦想着和人类行为很像的人造生物,他们在不同的场合可以表现出不同的人性化技巧,甚至比人类更像人类自己。

Pascal's machine performingsubtraction and summation - 1642
帕斯卡的可以进行加减法运算的机器 - 1642
Machine Learning is oneof the important lanes of AI which is very spicy hot subject in the research orindustry. Companies, universities devote many resources to advance theirknowledge. Recent advances in the field propel very solid results for differenttasks, comparable to human performance (98.98% at Traffic Signs - higher thanhuman-).
机器学习作为人工智能领域重要分支中的一个,无论在研究还是工业领域都是一个非常火热的主题。企业和大学投入很多资源来推进机器学习理论的发展。
在该领域的最新进展推动了不同任务产生革命性的结果,相当于人类的表现(高达98.98%的交通标志识别率,甚至比人类的识别率更高)。
HereI would like to share a crude timeline of Machine Learning and sign some of themilestones by no means complete. In addition, you should add "up to myknowledge" to beginning of any argument in the text.
在这里我想和大家分享一个机器学习的粗略时间表和一些善不完整的里程碑标志。 此外,如果你打算对我的这篇文章做任何评论,请以“基于我的知识”这句话开始。
First step towardprevalent ML was proposed by Hebb, in 1949, based on aneuropsychological learning formulation. It is calledHebbian Learning theory. Witha simple explanation, it pursues correlations between nodes of a RecurrentNeural Network (RNN). It memorizes any commonalities on the networkand serves like a memory later. Formally, the argument states that;
Let us assume that thepersistence or repetition of a reverberatory activity (or "trace")tends to induce lasting cellular changes that add to its stability.… Whenan axon ofcell A is near enough to excite a cell B and repeatedly orpersistently takes part in firing it, some growth process or metabolic changetakes place in one or both cells such that A's efficiency, as one of thecells firing B, is increased.[1]
Hebb于1949年基于神经心理学的学习机制开启机器学习的第一步,此后被称为Hebbian学习理论。一个简单的解释,它追求一种递归神经网络(RNN)节点之间的相关性,通过记忆网络共性实现像人类记忆一样的工作。从形式上看,论点表明;
让我们假设一个反射活动的持续或重复(或“跟踪”)往往会产生持久的细胞变化,以增加其稳定性…当细胞A的轴突离细胞B足够近,并且重复不断的参与激活细胞B,一些生长过程或者代谢变化在这一个或者这两个细胞中都发生了,因此,作为一个不断激励细胞B的细胞A的效率被提升[1]。
In 1952, Arthur Samuel at IBM, developed a program playingCheckers. The program was able to observe positions and learn aimplicit model that gives better moves for the latter cases. Samuel played somany games with the program and observed that the program was able toplay better in the course of time.
1952,IBM科学家亚瑟塞缪尔开发了一个跳棋程序。该程序能够通过观察当前位置,并学习一个隐含的模型,从而为后续动作提供更好的指导。塞缪尔发现,伴随着该游戏程序运行时间的增加,其可以实现越来越好的后续指导。
With thatprogram Samuel confuted the general providence dictating machines cannot gobeyond the written codes and learn patterns like human-beings. Hecoined “machine learning, ” which he defines as;a field of studythat gives computer the ability without being explicitly programmed.
通过这个程序,塞缪尔驳倒了普罗维登斯提出的机器无法超越人类,像人类一样写代码和学习的模式。他创造了“机器学习”,并将它定义为“可以提供计算机能力而无需显式编程的研究领域”。

F. Rosenblatt
罗森布拉特
In 1957, Rosenblatt's Perceptron was the secondmodel proposed again with neuroscientific background and it is more similar totoday's ML models. It was a very exciting discovery at the time and it waspractically more applicable than Hebbian's idea. Rosenblatt introduced thePerceptron with the following lines;
The perceptronis designed to illustrate some of the fundamental properties of intelligentsystems in general, without becoming too deeply enmeshed in the special, andfrequently unknown, conditions which hold for particular biologicalorganisms.[2]
1957年,罗森布拉特基于神经感知科学背景提出了第二模型,非常的类似于今天的机器学习模型。这在当时是一个非常令人兴奋的发现,它比赫布的想法更适用。罗森布拉特用以下的几行介绍了感知这个概念;
在通常意义上,这些概念旨在说明一些智能系统的本质属性,它们不会深深沉浸在特殊和经常未知的保持特定生物有机体的情形[2]。
After 3 yearslater, Widrow [4] engraved Delta Learning rule thatis then used as practical procedure for Perceptron training. It is alsoknown as Least Square problem. Combination of those two ideascreates a good linear classifier. However, Perceptron's excitement washinged by Minsky[3] in 1969 . He proposed the famous XORproblemand the inability of Perceptrons in such linearly inseparable datadistributions. It was the Minsky's tackle to NN community. Thereafter, NNresearches would be dormant up until 1980s
3年后,维德罗[4]首次使用Delta学习规则用于感知器的训练步骤。这种方法后来被称为最小二乘方法。这两者的结合创造了一个良好的线性分类器。1969年马文·明斯基[3]将感知器兴奋推到最高顶峰。他提出了著名的XOR问题和感知器数据线性不可分的情形。这是马文·明斯基的网络社区时代。此后,神经网络的研究将处于休眠状态,直到上世纪80年代。
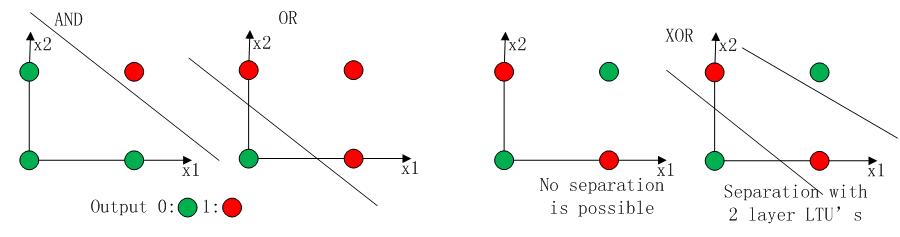
XOR problem which is nor linearlyseperable data orientation
非线性可分数据的XOR问题
There had beennot to much effort until the intuition of Multi-Layer Perceptron (MLP) wassuggested by Werbos[6] in 1981 with NN specific Backpropagation
(BP) algorithm, albeit BP idea had been proposed before by Linnainmaa[5] in 1970 in the name "reverse mode of automatic differentiation".Still BP is the key ingredient of today's NN architectures. With those newideas, NN researches accelerated again. In 1985 - 1986 NN researcherssuccessively presented the idea of MLP with practical BP training(Rumelhart, Hinton, Williams [7] - Hetch, Nielsen[8])
尽管BP神经的想法由林纳因马[5]在1970年提出,并将其称为“自动分化反向模式”。但是并未引起足够的关注。经过一些挫折后,多层感知器(MLP)由伟博斯[6]在1981年的神经网络反向传播(BP)算法中具体提出。当然BP仍然是今天神经网络架构的关键因素。有了这些新思想,神经网络的研究又加快了。1985 -1986神经网络研究人员先后提出了MLP与BP训练相结合的理念(鲁梅尔哈特,辛顿,威廉姆斯[7] -赫,尼尔森[8])。

From Hetch and Nielsen
来自赫和尼尔森
At the anotherspectrum, a very-well known ML algorithm was proposed by J. R. Quinlan[9] in 1986 that we callDecision Trees, morespecifically ID3algorithm. This was the spark point ofthe another mainstream ML. Moreover, ID3 was also released as asoftware able to find more real-life use case with its simplistic rulesand its clear inference, contrary to still black-box NN models.
从另一个方面来看,一个非常著名的ML算法由昆兰[9]在1986年提出,我们称之为决策树算法,更准确的说是ID3算法。这是另一个主流机器学习的火花点。此外,与黑盒神经网络模型截然不同的是,决策树ID3算法也被作为一个软件,通过使用简单的规则和清晰的参考可以找到更多的现实生活中的使用情况。
After ID3, manydifferent alternatives or improvements have been explored by the community(e.g. ID4, Regression Trees, CART ...) and still it is one of the active topicin ML.
基于决策树ID3算法,很多不同的选择和改进已经由探索社区进行了尝试(像ID4、回归树、CART等),当然它仍然是机器学习领域的一个活跃主题。

a simple decision tree from Quinlan
一个简单的决策树,来自昆兰
One of the mostimportant ML breakthrough was Support Vector Machines (Networks)(SVM), proposed by Vapnik and Cortes[10] in 1995 withvery strong theoretical standing and empirical results. That was the timeseparating the ML community into two crowds as NN or SVM advocates. However thecompetition between two community was not very easy for the NN side after Kernelized version of SVM by near 2000s .(Iwas not able to find the first paper about the topic), SVM got the best of manytasks that were occupied by NN models before. In addition, SVM wasable to exploit all the profound knowledge of convex optimization,generalization margin theory and kernels against NN models. Therefore, it couldfind large push from different disciplines causing very rapidtheoretical and practical improvements.
其中一个最重要的ML的突破是支持向量机(SVM),是由瓦普尼克和科尔特斯[10]在大量理论和实证的条件下于1995年提出。从此将机器学习社区分为神经网络社区和支持向量机社区。然而两个社区之间的竞争并不那么容易,神经网络要落后SVM核化后的版本将近2000S(我将会找到第一个关于此话题的论文)。支持向量机在以前许多神经网络模型不能解决的任务中取得了良好的效果。此外,支持向量机能够利用所有的先验知识做凸优化选择,产生准确的理论和核模型。因此,它可以对不同的学科产生大的推动,产生非常高效的理论和实践改善。

An example of a separable problem ina 2 dimensional space.The support vectors,marked with grey squares,define themargin of largest separation between the two classes.
二维空间中的分类例子,灰色方框标记的可支持向量机,定义了两个类之间最大间隔的极限
From Vapnik and Cortes
来自瓦普尼克和科尔特斯
NN took another damageby the work of Hochreiter's thesis [40] in 1991 and Hochreiter et.al.[11] in 2001, showing the gradient loss after the saturation of NN unitsas we apply BP learning. Simply means, it is redundant to train NN units aftera certain number of epochs owing to saturated units hence NNs are very inclinedto over-fit in a short number of epochs.
在霍克赖特1991年和2001年的相关论文中指出,神经网络有着另外一个缺点,在我们应用BP神经网络学习的过程中,当神经网络单元饱和之后会产生梯度损失。简单来说,由于饱和神经单元的存在,在经过一定数量时间的训练,继续进行训练是冗余的,因此,在经过少量时间的训练后,神经网络是非常倾向于过饱和的。
Littlebefore, another solid ML model was proposed by Freund andSchapire in 1997 prescribed with boosted ensemble ofweak classifiers called Adaboost. This work also gave theGodel Prize to the authors at the time. Adaboost trains weak set of classifiersthat are easy to train, by giving more importance to hard instances. This modelstill the basis of many different tasks like face recognition and detection. Itis also a realization of PAC (Probably Approximately Correct) learningtheory. In general, so called weak classifiers are chosen as simple decisionstumps (single decision tree nodes). They introduced Adaboost as ;
The model we study canbe interpreted as a broad, abstract extension of the well-studied on-lineprediction model to a general decision-theoretic setting...[11]
不久之前,另一个著名的ML模型由弗罗因德和Schapire在1997年提出,它规定了一个弱分类器的集合并将其称为AdaBoost。这项工作的作者也因此被授予了哥德尔奖。AdaBoost通过给予更多的条件限制,很容易训练弱分类器数据集。这个模型仍然是许多复杂任务,如人脸检测识别的基础。同时这也实现了PAC学习理论。一般来说,AdaBoost选择所谓的弱分类器作为简单的决定树桩(单个的决策树支点)。AdaBoost被描述如下;
我们研究的这个模型可以被解释为一个学习良好的在线预测模型到一般决策理论的一个广泛、抽象的扩展[11]。
Another ensemblemodel explored by Breiman [12] in 2001 thatensembles multiple decision trees where each of them is curated by a randomsubset of instances and each node is selected from a random subset of features.Owing to its nature, it is called Random Forests(RF). RF hasalso theoretical and empirical proofs of endurance againstover-fitting. Even AdaBoost shows weakness to over-fitting and outlierinstances in the data, RF is more robust model against thesecaveats.(For more detail about RF, refer to my old post.).RF shows its success in many different tasks like Kaggle competitions as well.
另一个集成决策树模型由布雷曼博士在2001年提出,它是由一个随机子集的实例组成,并且每个节点都是从一系列随机子集中选择。由于它的这个性质,被称为随机森林(RF)。随机森林也在理论和经验上证明了对过拟合的抵抗性。甚至连AdaBoost算法在数据过拟合和离群实例中都表现出了弱点,而随机森林是针对这些警告更稳健的模型(有关随机森林更多详细信息,请参阅我的老帖子)。随即森林RF在许多不同的任务,像Kaggle比赛等都表现出了成功的一面。
Random forestsare a combination of tree predictors such that each tree depends on the valuesof a random vector sampled independently and with the same distribution for alltrees in the forest. The generalization error for forests converges a.s.to a limit as the number of trees in the forest becomes large[12].
随机森林是树预测的组合,使得每一棵树依赖于随机向量的独立采样值,并在森林的所有树木相同的分布。随着随机森林中树木数量的增多,随机森林的泛化误差收敛到了一个限定值[12]。
As we comecloser today, a new era of NN called Deep Learning has beencommerced. This phrase simply refers NN models with many wide successivelayers. The 3rd rise of NN has begun roughly in 2005 withthe conjunction of many different discoveries from past and present by recent mavens Hinton, LeCun, Bengio, Andrew Ng and other valuableolder researchers. I enlisted some of the important headings (I guess, Iwill dedicate complete post for Deep Learning specifically) ;
时至今日,一个被成为深度学习的神经网络已经产生。这句话仅仅是指有着许多宽连续层的神经网络模型。随着辛顿、勒村、本希奥、吴恩达和其他有价值的研究者将过去和现在的许多不同的发现相结合,促使神经网络在2005年有了第三次快速的发展。我收录了重要标题中的一些(我猜想,我将会特别致力于深度学习领域的研究)。
GPU programmingGPU编程
ConvolutionalNNs [18][20][40] 卷积神经网络[18] [20][40]
DeconvolutionalNetworks [21] 解卷积网络[21]
Optimizationalgorithms优化算法
StochasticGradient Descent [19][22] 随机梯度下降[19][22]
BFGS and L-BFGS[23] 拟牛顿法和受限内存下的拟牛顿法[23]
ConjugateGradient Descent [24] 共轭梯度下降[24]
Backpropagation[40][19] 反向传播[40] [19]
Rectifier Units整流机组
Spa rsity[15][16] 稀疏
Dropout Nets[26] Dropout网[26]
Maxout Nets [25] MAXOUT网[25]
Unsupervised NNmodels [14] 无监督神经网络模型[14]
Deep BeliefNetworks [13] 深信念网络[13]
StackedAuto-Encoders [16][39] 堆积自动编码器[16][39]
Denoising NNmodels [17] 降噪神经网络模型[17]
With thecombination of all those ideas and non-listed ones, NN models are able to beatoff state of art at very different tasks such as Object Recognition, Speech Recognition,NLP etc. However, it should be noted that this absolutely does not mean, it isthe end of other ML streams. Even Deep Learning success stories growrapidly , there are many critics directed to training cost andtuning exogenous parameters of these models. Moreover, stillSVM is being used more commonly owing to its simplicity. (said but may cause ahuge debate)
随着这些已经列出的和还未列出的思想的结合,神经网络模型能够实现任何艰难的任务,如目标识别、语音识别、自然语言处理等。但是,应该注意的是,这绝对不意味着其他机器学习方法的终结。尽管深度学习的成功案例迅速增长,但是对这些模型的训练成本是相当高的,调整外部参数也是很麻烦。同时,SVM的简单性促使其仍然被广泛使用(虽然这样说,但很有可能引起大量的反对)。
Before finish, Ineed to touch on one another relatively young ML trend. After the growth of WWWand Social Media, a new term, BigData emerged andaffected ML research wildly. Because of the large problems arising from BigData, many strong ML algorithms are useless for reasonable systems (not for giantTech Companies of course). Hence, research people come up with a new set ofsimple models that are dubbed Bandit Algorithms [27 - 38](formallypredicated with Online Learning) that makeslearning easier and adaptable for large scale problems.
结束之前,我需要提及另一个相对年轻的机器学习趋势。伴随着互联网和社会媒体的增长,一个新的名词,大数据正在疯狂的产生和影响着机器学习。因为伴随着大数据产生了许多大问题,许多强大的机器学习算法对于这样的合理的系统是无用的(当然不适用于大型高科技公司)。因此,研究人员想出了一个新的简单的被称为强盗算法[27-38]的模型(通过在线学习可以实现正式的预测),这
使得机器学习更容易,更加适合解决大数据问题。
I would like toconclude this infant sheet of ML history. If you found something wrong (youshould :) ), insufficient or non-referenced, please don't hesitate to warn mein all manner.
我很乐意总结机器学习历史的婴儿表。如果您发现一些错误的、不足的、未引用的,请用任何方式毫不犹豫的提醒我。
最后给出本文word版本的下载地址http://download.csdn.net/detail/qq_14845119/9510569
References ----
[1] Hebb D.O., The organization of behaviour.New York: Wiley & Sons.
[2]Rosenblatt,Frank. "The perceptron: a probabilistic model for information storage andorganization in the brain." Psychological review 65.6 (1958):386.
[3]Minsky,Marvin, and Papert Seymour. "Perceptrons." (1969).
[4]Widrow,Hoff "Adaptive switching circuits." (1960): 96-104.
[5]S.Linnainmaa. The representation of the cumulative rounding error of an algorithmas a Taylor expansion of the local rounding errors. Master’s thesis, Univ.Helsinki, 1970.
[6] P. J.Werbos. Applications of advances in nonlinear sensitivity analysis. InProceedings of the 10th IFIP Conference, 31.8 - 4.9, NYC, pages 762–770, 1981.
[7] Rumelhart,David E., Geoffrey E. Hinton, and Ronald J. Williams. Learning internalrepresentations by error propagation. No. ICS-8506. CALIFORNIA UNIV SAN DIEGOLA JOLLA INST FOR COGNITIVE SCIENCE, 1985.
[8] Hecht-Nielsen,Robert. "Theory of the backpropagation neural network." NeuralNetworks, 1989. IJCNN., International Joint Conference on. IEEE, 1989.
[9] Quinlan,J. Ross. "Induction of decision trees." Machinelearning 1.1 (1986): 81-106.
[10] Cortes,Corinna, and Vladimir Vapnik. "Support-vector networks." Machinelearning 20.3 (1995): 273-297.
[11] Freund,Yoav, Robert Schapire, and N. Abe. "A short introduction toboosting."Journal-Japanese Society For ArtificialIntelligence 14.771-780 (1999): 1612.
[12] Breiman,Leo. "Random forests." Machine learning 45.1 (2001): 5-32.
[13] Hinton,Geoffrey E., Simon Osindero, and Yee-Whye Teh. "A fast learning algorithmfor deep belief nets." Neural computation 18.7 (2006):1527-1554.
[14] Bengio,Lamblin, Popovici, Larochelle, "Greedy Layer-Wise Training of DeepNetworks", NIPS’2006
[15]Ranzato,Poultney, Chopra, LeCun " Efficient Learning of SparseRepresentations with an Energy-Based Model ", NIPS’2006
[16] OlshausenB a, Field DJ. Sparse coding with an overcomplete basis set: a strategyemployed by V1? Vision Res. 1997;37(23):3311–25. Available at: http://www.ncbi.nlm.nih.gov/pubmed/9425546.
[17] Vincent,H. Larochelle Y. Bengio and P.A. Manzagol, Extracting and Composing RobustFeatures with Denoising Autoencoders, Proceedingsof the Twenty-fifth International Conference on Machine Learning (ICML‘08),pages 1096 - 1103, ACM, 2008.
[18] Fukushima,K. (1980). Neocognitron: A self-organizing neural network model for a mechanismof pattern recognition unaffected by shift in position. Biological Cybernetics,36, 193–202.
[19] LeCun,Yann, et al. "Gradient-based learning applied to documentrecognition."Proceedings of the IEEE 86.11 (1998): 2278-2324.
[20] LeCun,Yann, and Yoshua Bengio. "Convolutional networks for images, speech, andtime series." The handbook of brain theory and neural networks3361(1995).
[21] Zeiler,Matthew D., et al. "Deconvolutional networks." Computer Visionand Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
[22] S.Vishwanathan, N. Schraudolph, M. Schmidt, and K. Mur- phy. Accelerated trainingof conditional random fields with stochastic meta-descent. In InternationalConference on Ma- chine Learning (ICML ’06), 2006.
[23] Nocedal,J. (1980). ”Updating Quasi-Newton Matrices with Limited Storage.”Mathematics of Computation 35 (151):773782. doi:10.1090/S0025-5718-1980-05728
55-
[24] S.Yun and K.-C. Toh, “A coordinate gradient descent method for l1- regularizedconvex minimization,” Computational Optimizations and Applications, vol. 48,no. 2, pp. 273–307, 2011.
[25] GoodfellowI, Warde-Farley D. Maxout networks. arXiv Prepr arXiv …. 2013. Availableat: http://arxiv.org/abs/1302.4389. Accessed March 20, 2014.
[26] Wan L,Zeiler M. Regularization of neural networks using dropconnect. Proc ….2013;(1). Available at:http://machinelearning.wustl.edu/mlpapers/papers/icml2013_w
an13. AccessedMarch 13, 2014.
[27] Alekh Agarwal, Olivier Chapelle, Miroslav Dudik, JohnLangford, AReliable Effective Terascale Linear Learning System, 2011
[28] M. Hoffman, D. Blei, F. Bach, Online Learning for Latent DirichletAllocation, in Neural Information Processing Systems (NIPS) 2010.
[29] Alina Beygelzimer, Daniel Hsu, JohnLangford, and Tong Zhang Agnostic Active Learning Without Constraints NIPS2010.
[30] John Duchi, Elad Hazan, and Yoram Singer, Adaptive Subgradient Methods forOnline Learning and Stochastic Optimization, JMLR 2011& COLT 2010.
[31] H. Brendan McMahan, Matthew Streeter, Adaptive Bound Optimization for Online Convex Optimization, COLT 2010.
[32] Nikos Karampatziakis and JohnLangford, ImportanceWeight Aware Gradient Updates UAI2010.
[33] Kilian Weinberger, Anirban Dasgupta, JohnLangford, Alex Smola, Josh Attenberg, Feature Hashing for Large Scale Multitask Learning, ICML 2009.
[34] Qinfeng Shi, James Petterson, Gideon Dror, JohnLangford, Alex Smola, and SVN Vishwanathan, Hash Kernels for Structured Data, AISTAT 2009.
[35] JohnLangford, Lihong Li, and Tong Zhang, Sparse Online Learning via TruncatedGradient, NIPS 2008.
[36] Leon Bottou, Stochastic Gradient Descent, 2007.
[37] Avrim Blum, Adam Kalai, and JohnLangford Beating the Holdout: Bounds for KFoldand Progressive Cross-Validation. COLT99 pages203-208.
[38] Nocedal, J. (1980)."Updating Quasi-Newton Matrices with Limited Storage". Mathematics ofComputation 35: 773–782.
[39] D.H. Ballard. Modular learning in neural networks. In AAAI, pages 279–284, 1987.
[40] S. Hochreiter. Untersuchungen zudynamischen neuronalen Netzen. Diploma thesis, Institut f ̈ur In-formatik,Lehrstuhl Prof. Brauer, Technische Universit ̈at M ̈unchen, 1991. Advisor: J.Schmidhuber.














 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









