







1. SVM
可支持向量机这个概念最早是由Vapnik领导下的AT&TBell实验室研究小组在1963年提出。可支持向量机是一种在概率统计和分类回归问题上非常有效的解决技术,在模式识别领域中发挥着重要的作用。在各种线性、非线性、小样本、高维模式问题中可支持向量机都表现出了其独有的优势,并能通过各种函数拟合和曲线拟合解决其他的机器学习问题。因此,可支持向量机只经过了短时间的发展就取得了许多重要的成果,并被广泛应用在字符识别、生物信息识别、文本理解等前沿领域。
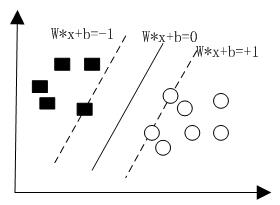
可支持向量机(support vector machine)的分类规则,即使在样本量非常少的情况下,都可以通过寻求结构化最小风险和最小置信范围来优化分类规则,并得出最优的统计规律。简单的说,可支持向量机就是一种二分类模型,通过确定最佳的分界线,即使得分界线离样本两边的数据集的距离最小,这样就确定了间隔最大的线性分类器,通过间隔最大化,就可以将好多分类问题转化为一个凸二次规划问题或者正则化的合页损失函数的最小化问题来求解。在求解凸二次规划的最优化问题中,可支持向量机是一个最好的选择。
根据实际解决问题的情形,可支持向量机可以分为线性可分模型和线性不可分模型两类。
对于线性可分的情形,首先要做的就是构造一个Logistic回归。例如,给定一些数据集,里面包含两种类别。用x表示数据集,y表示数据集所属的类别,则线性分类器就是在N维空间构造一个超平面,用这个超平面将这两个类分开。
而这个超平面可以表示为下面的公式
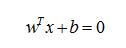
Logistic回归就是一个0/1分类的模型。可以实现将自变量从负无穷到正无穷映射到0到1上。如果用x表示n维特征向量,则Logistic函数的公式如下
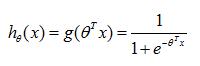
令x为自变量,为因变量,画出的函数曲线如下图所示,可以看出Logistic函数将结果映射到0到1之间。
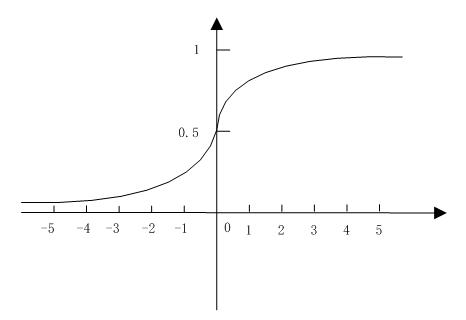
二维Logistic函数曲线
并且,将该函数的概率公式描述如下
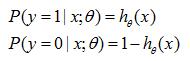
从公式可以看出,该概率主要与相关。而Logistic回归就是不断训练样本,使得正样本都满足大于0,负样本都满足小于0。最后实现的效果如下图所示。
Logistic回归效果图
当超平面与两边的点距离间隔最大的时候,这个超平面就是最佳的超平面。
我们用来表示点x到超平面的距离。当的符号于y的符号一致,则判别正确,如果不一致,则判别错误。因此,可以用来表示判别结果的正确性,并将此定义为函数间隔(functional margin),则公式表示为
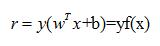
但是由于函数间隔并不能完美的表示点到超平面的距离,于是又引入了几何间隔(geometrical margin)。如下图所示的,点A到超平面的垂点为点B,假设点A到超平面的距离为r,w为超平面的垂向量。则有下面公式成立
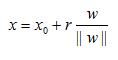
其中,表示w的范数。令f(x)=0,从而解出几何间隔r。
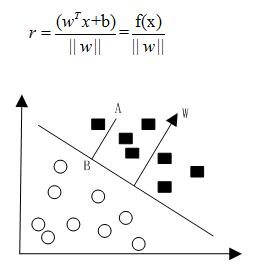
几何间隔图
当超平面离数据点的间隔越大,则可信度就越大。所以,想要确定最优的超平面就得先确定最大的间隔,即下图中的gap/2。
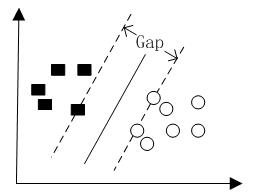
因此,定义最大间隔分类器(maximum margin classifier)max(r),当令r等于1时,得出下面公式
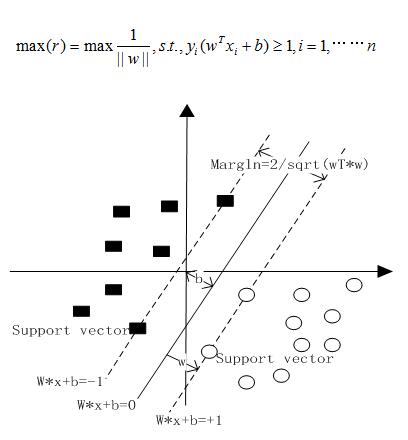
最大间隔分类器模型
而对于线性不可分的情况,SVM可以通过一个核函数,映射到一个更高维的空间,直到线性可分为止。如下图所示,对于在二维空间线性不可分的情形,通过将其映射到三维空间,实现可分。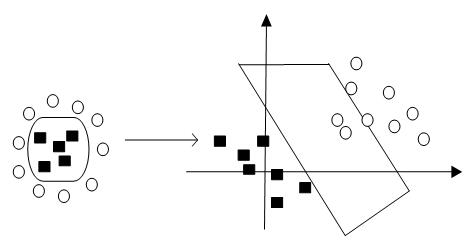
二维空间到三维空间的映射情形
建立非线性机器学习需要分为两个基本步骤:
1)将非线性数据映射到一个新的特征空间
2)在新的特征空间,使用线性分类器进行分类
在特征空间中定义线性分类器公式如下
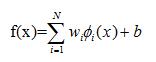
考虑到线性分类器的对偶性质,可以将上述公式用测试集和训练集的内积形式来表示
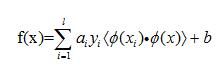
SVM的关键在于核函数。低维空间向量集中线性可分的情形通常很容易解决,而大部分情形是非线性可分的,这时候就得将低维空间的信息映射到高维空间,在高维空间实现线性可分。虽然该方法解决了低维空间线性不可分的问题,但是也带来了计算复杂度的增加,而SVM的应用正好可以巧妙地解决这个问题,通过在低维空间学习在高维空间分类大大的减少了分类时间。SVM从低维空间向高维空间的映射主要通过核函数机制实现。在SVM理论中,解决不同的问题需要采用不同的核函数,核函数的选取将会对后续解决问题产生大的影响。常用的核函数有以下4种:
(1)线性核函数
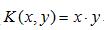
(2)多项式核函数
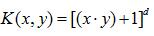
(3)径向基函数
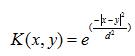
(4)双层神经网络模型的核函数
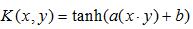
SVM的特征如下:
(1)SVM的学习机制就是一个凸优化问题的求解过程,根据已知的有效算法来发现未知的全局最小值。而其他类型的机器学习方法,像各种基于神经网络的模型,都是采用贪心算法来求解局部最小值,很多时候就是局部最小值和全局最小值的差距。
(2)SVM总是可以确定一个离两种类型的数据总距离最远的决策边界。当然这个边界的确定还需要用户提供相关参数,像核函数类型、松弛变量等。
(3)哑变量的引入可以使SVM用于解决数据分类问题。
(4)正如下图仿真所看到的,SVM对于两类线性和非线性问题都能得到很好的解决,但是对于三类及以上问题就会有比较明显的出错情形。因此,SVM最擅长解决二类问题,在解决多类问题上有待后续改进。
SVM在线性和非线性问题的效果如下图所示。其中,第一个图的两个种类数目为100,SVM类型为C_SVC,核类型为LINEAR,迭代次数为10000,第二个图两个种类数目为80,SVM类型为C_SVC,核类型为RBF,迭代次数为100000,第三个图三个种类数目为100,SVM类型为C_SVC,核类型为RBF,迭代次数为100。
从图中可以看出对于两类线性问题,只要迭代次数足够大,可以得到完美的分类效果。对于非线性的问题,SVM也能给出相当不错的解答,远远高于逻辑模式(GLM)以及决策树模式(DT),因为后两者都是使用了直线方法。

1) 两种类线性可分 2) 两种类线性不可分 3) 三种类线性不可分
SVM分类模型
1) 两种类线性可分
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml/ml.hpp>
#include <iostream>
using namespace std;
using namespace cv;
#define DATANUM 100
void drawcross(Mat& src,Point &pt, Scalar sclr, double width)
{
Point up, down, left, right;
up = down = left = right = pt;
up.y = up.y - 6;
down.y = down.y + 6;
left.x=left.x-6;
right.x=right.x+6;
line(src, up, down, sclr, width);
line(src, left, right, sclr, width);
}
int main()
{
// 视觉表达数据的设置(Data for visual representation)
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
// step 1: //建立训练数据( Set up training data)
float labels[DATANUM];
float trainingData[DATANUM][2];
RNG rng;
int ii,jj;
for(int i=0;i<DATANUM;i++)
{
ii=rng.uniform(1, 512);jj=rng.uniform(1, 512);
while(ii==jj)
{
ii=rng.uniform(1, 512);jj=rng.uniform(1, 512);
}
trainingData[i][0]=ii;trainingData[i][1]=jj;
if (-1.732*ii+300*1.732-jj>0)
labels[i] = 1;
else
labels[i] = -1;
}
Mat labelsMat(DATANUM, 1, CV_32FC1, labels);
Mat trainingDataMat(DATANUM, 2, CV_32FC1, trainingData);
/*cout<<labelsMat<<endl;
cout<<trainingDataMat<<endl;*/
// step 2: //设置支持向量机的参数(Set up SVM's parameters)
CvSVMParams params;
params.svm_type = CvSVM::C_SVC;
params.kernel_type = CvSVM::LINEAR;
params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 10000, 1e-6);
// step 3: // 训练支持向量机(Train the SVM)
CvSVM SVM;
SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
// step 4: //显示由SVM给出的决定区域 (Show the decision regions given by the SVM)
Vec3b green(0, 255, 0), blue(255, 0, 0);
for (int i=0; i<image.rows; i++)
{
for (int j=0; j<image.cols; j++)
{
Mat sampleMat = (Mat_<float>(1,2) << i,j);
float response = SVM.predict(sampleMat);
if (fabs(response-1.0) < 0.0001)
{
image.at<Vec3b>(j, i) = green;
}
else if (fabs(response+1.0) < 0.001)
{
image.at<Vec3b>(j, i) = blue;
}
}
}
//显示训练数据 (Show the training data)
int thickness = -1;
int lineType = 8;
for (int i=0;i<DATANUM;i++)
{
if (labels[i]==1)
circle( image, Point(trainingData[i][0], trainingData[i][1]), 5, Scalar( 0, 0, 0), thickness, lineType);
//drawcross(image,Point(trainingData[i][0], trainingData[i][1]),Scalar(0, 0, 0), 1);
else
//circle( image, Point(trainingData[i][0], trainingData[i][1]), 5, Scalar(255, 255, 255), thickness, lineType);
drawcross(image,Point(trainingData[i][0], trainingData[i][1]),Scalar(255, 255, 255), 1);
}
// step 5://显示支持向量 (Show support vectors)
thickness = 2;
lineType = 8;
int c = SVM.get_support_vector_count();
for (int i=0; i<c; i++)
{
const float* v = SVM.get_support_vector(i);
circle( image, Point( (int) v[0], (int) v[1]), 6, Scalar(255, 0, 0), thickness, lineType);
}
imshow("SVM Simple Example", image); // 显示图像
waitKey();
return 0;
}
2) 两种类线性不可分 :
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml/ml.hpp>
#include <iostream>
using namespace std;
using namespace cv;
void drawcross(Mat& src,Point &pt, Scalar sclr, double width)
{
Point up, down, left, right;
up = down = left = right = pt;
up.y = up.y - 6;
down.y = down.y + 6;
left.x=left.x-6;
right.x=right.x+6;
line(src, up, down, sclr, width);
line(src, left, right, sclr, width);
}
void drawCross(Mat &img, Point center, Scalar color)
{
int col = center.x > 2 ? center.x : 2;
int row = center.y> 2 ? center.y : 2;
line(img, Point(col -2, row - 2), Point(col + 2, row + 2), color);
line(img, Point(col + 2, row - 2), Point(col - 2, row + 2), color);
}
int newSvmTest(int rows, int cols, int testCount)
{
if(testCount > rows * cols)
return 0;
Mat img = Mat::zeros(rows, cols, CV_8UC3);
Mat testPoint = Mat::zeros(rows, cols, CV_8UC1);
Mat data = Mat::zeros(testCount, 2, CV_32FC1);
Mat res = Mat::zeros(testCount, 1, CV_32SC1);
int row,col;
//Create random test points
for (int i= 0; i< testCount; i++)
{
row = rand() % rows;
col = rand() % cols;
if(testPoint.at<unsigned char>(row, col) == 0)
{
testPoint.at<unsigned char>(row, col) = 1;
data.at<float>(i, 0) = float (col) / cols;
data.at<float>(i, 1) = float (row) / rows;
}
else
{
i--;
continue;
}
if (row>100&&row<300&&col>100&&col<500)
{
rectangle(img,Rect(col-5,row-5,10,10), CV_RGB(255, 0, 0));
res.at<unsigned int>(i, 0) = 1;
}
else
{
<span style="white-space:pre"> </span>drawcross(img,Point(col, row), CV_RGB(0, 255, 0), 1);
res.at<unsigned int>(i, 0) = 2;
}
}
/START SVM TRAINNING//
CvSVM svm;// = CvSVM();
CvSVMParams param;
CvTermCriteria criteria;
criteria= cvTermCriteria(CV_TERMCRIT_EPS, 100000, FLT_EPSILON);
param= CvSVMParams (CvSVM::C_SVC, CvSVM::RBF, 10.0, 8.0, 1.0, 10.0, 0.5, 0.1, NULL, criteria);
svm.train(data, res, Mat(), Mat(), param);
for (int i= 0; i< rows; i++)
{
for (int j= 0; j< cols; j++)
{
Mat m = Mat::zeros(1, 2, CV_32FC1);
m.at<float>(0,0) = float (j) / cols;
m.at<float>(0,1) = float (i) / rows;
float ret = 0.0;
ret = svm.predict(m);
Scalar rcolor;
switch ((int) ret)
{
case 1: rcolor= CV_RGB(0, 0, 255); break;
case 2: rcolor= CV_RGB(255, 0, 0); break;
}
if (img.at<Vec3b>(i,j)[0]==0&&img.at<Vec3b>(i,j)[1]==0&&img.at<Vec3b>(i,j)[2]==0)
line(img, Point(j,i), Point(j,i), rcolor);
}
}
//Show support vectors
int sv_num= svm.get_support_vector_count();
for (int i= 0; i< sv_num; i++)
{
const float* support = svm.get_support_vector(i);
circle(img, Point((int) (support[0] * cols), (int) (support[1] * rows)), 5, CV_RGB(200, 200, 200));
}
imshow("dst", img);
waitKey();
return 0;
}
int main(int argc, char** argv)
{
return newSvmTest(400, 600, 80);
} 3) 三种类线性不可分
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/ml/ml.hpp>
#include <iostream>
using namespace std;
using namespace cv;
void drawcross(Mat& src,Point &pt, Scalar sclr, double width)
{
Point up, down, left, right;
up = down = left = right = pt;
up.y = up.y - 6;
down.y = down.y + 6;
left.x=left.x-6;
right.x=right.x+6;
line(src, up, down, sclr, width);
line(src, left, right, sclr, width);
}
void drawCross(Mat &img, Point center, Scalar color)
{
int col = center.x > 2 ? center.x : 2;
int row = center.y> 2 ? center.y : 2;
line(img, Point(col -2, row - 2), Point(col + 2, row + 2), color);
line(img, Point(col + 2, row - 2), Point(col - 2, row + 2), color);
}
int newSvmTest(int rows, int cols, int testCount)
{
if(testCount > rows * cols)
return 0;
Mat img = Mat::zeros(rows, cols, CV_8UC3);
Mat testPoint = Mat::zeros(rows, cols, CV_8UC1);
Mat data = Mat::zeros(testCount, 2, CV_32FC1);
Mat res = Mat::zeros(testCount, 1, CV_32SC1);
int row,col;
//Create random test points
for (int i= 0; i< testCount; i++)
{
row = rand() % rows;
col = rand() % cols;
if(testPoint.at<unsigned char>(row, col) == 0)
{
testPoint.at<unsigned char>(row, col) = 1;
data.at<float>(i, 0) = float (col) / cols;
data.at<float>(i, 1) = float (row) / rows;
}
else
{
i--;
continue;
}
if (row > ( 50 * cos(col * CV_PI/ 100) + 200) )
{
drawCross(img, Point(col, row), CV_RGB(255, 0, 0));
rectangle(img,Rect(col-5,row-5,10,10), CV_RGB(255, 0, 0));
res.at<unsigned int>(i, 0) = 1;
}
else
{
if (col > 200)
{
drawCross(img, Point(col, row), CV_RGB(0, 255, 0));
drawcross(img,Point(col, row), CV_RGB(0, 255, 0), 1);
res.at<unsigned int>(i, 0) = 2;
}
else
{
drawCross(img, Point(col, row), CV_RGB(0, 0, 255));
rectangle(img,Rect(col-5,row-5,10,10), CV_RGB(0, 0, 255));
res.at<unsigned int>(i, 0) = 3;
}
}
}
/START SVM TRAINNING//
CvSVM svm;// = CvSVM();
CvSVMParams param;
CvTermCriteria criteria;
criteria= cvTermCriteria(CV_TERMCRIT_EPS, 100, FLT_EPSILON);
param= CvSVMParams (CvSVM::C_SVC, CvSVM::RBF, 10.0, 8.0, 1.0, 10.0, 0.5, 0.1, NULL, criteria);
svm.train(data, res, Mat(), Mat(), param);
for (int i= 0; i< rows; i++)
{
for (int j= 0; j< cols; j++)
{
Mat m = Mat::zeros(1, 2, CV_32FC1);
m.at<float>(0,0) = float (j) / cols;
m.at<float>(0,1) = float (i) / rows;
float ret = 0.0;
ret = svm.predict(m);
Scalar rcolor;
switch ((int) ret)
{
case 1: rcolor= CV_RGB(0, 0, 255); break;
case 2: rcolor= CV_RGB(255, 0, 0); break;
case 3: rcolor= CV_RGB(0, 255,0 ); break;
}
if (img.at<Vec3b>(i,j)[0]==0&&img.at<Vec3b>(i,j)[1]==0&&img.at<Vec3b>(i,j)[2]==0)
line(img, Point(j,i), Point(j,i), rcolor);
}
}
//Show support vectors
int sv_num= svm.get_support_vector_count();
for (int i= 0; i< sv_num; i++)
{
const float* support = svm.get_support_vector(i);
circle(img, Point((int) (support[0] * cols), (int) (support[1] * rows)), 5, CV_RGB(200, 200, 200));
}
imshow("dst", img);
waitKey();
return 0;
}
int main(int argc, char** argv)
{
return newSvmTest(400, 600, 100);
}2. Libsvm和Liblinear
国立台湾大学的Chih-Jen Lin博士提出了两个SVM库模型,分别是 Libsvm和Liblinear。其中,最先被提出的是Libsvm模型,这个模型主要用于处理少量数据的非线性分类问题,后续Liblinear也被提出,主要用于解决海量数据的线性分类问题。同时linear分类器还有其自身独特的特点,经过优化的linear分类器的复杂度和训练时间都是非常小的。即使在海量数据的分类学习上也表现出非常完美的性能,因此被广泛的用于解决大规模规数据的线性分类问题和回归问题。
(1)如果提取的特征向量远远大于样本数量,那么使用Liblinear
(2)对于样本数量很大,提取的特征数也很大的情形一般使用线性核,此时 LIBLINEAR的学习速率远高于LIBSVM.
(3)对于样本数量很大,提取的特征数却很小的情形一般使用RBF。如果这种情形下要使用线性核,则优先选择LIBLINEAR。
(4)所有线性问题都是用LIBLINEAR,而不要使用LIBSVM。
对于多分类(Multi-class classification)问题,LIBSVM和LIBLINEAR都是支持的。所谓多分类问题,就是说对每个测试数据的预测,数据库中的每个类别都是有可能存在的,只是概率高低的问题,但是最终只能输出一个类别作为预测结果。比如本文中对于场景中牛的预测,分类器对每个类别的事物都是有打分的,最终输出打分最高的那个作为最后的输出结果。再比如经典的字符识别问题,对于任意一幅测试图像,最后只能输出0-9中的其中一个。
LIBSVM与LIBLINEAR的实现方式是完全不同的。其中LIBSVM采用的是一对一的学习策略,就是说如果样本数据库中有k个类,理论上就需要训练 k(k-1)/2个分类器,这样带来的缺点就是随着样本数量的增加,训练的复杂度将会呈二次幂的形式增加,即使经过优化后的libsvm,其实际需要训练的分类器数量还是很大的。但是这样的一对一的训练策略也有一个好处,就是使每一个子分类的问题都是原来模型的一半,大大缩小训练样本数量,非常有利于整个模型的训练和学习。
与之相反的LIBLINEAR则采取了另一种训练学习策略,即一对多的学习规则。用一个分类器来表示数据库中的一类事物,副样本则用其他类别的分类器表示。由此明显的可以看出LIBLINEAR可以训练比LIBSVM更大规模的数据,同时训练时间更短。此外,人们还在LIBLINEAR分类器中集成了Crammerand Singer这种多分类算法,可以方便的通过一个目标函数学习所有类别对应的分类器。















 3811
3811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









