







论文链接:https://arxiv.org/abs/1804.02767
作者:Joseph Redmon, Ali Farhadi
发布时间:2018年4月8日发布
论文总结
对比YOLOv2,YOLOv3使用了更大的backbone(darknet-19 vs darknet-53),同时在backbone中使用了残差。在检测头的特征提取上,YOLOv3使用了特征金字塔的概念,将上采样的特征与backbone对应大小的特征concat起来使用。
YOLOv3使用了多尺度预测的概念,缓解了小目标检测的问题。但使用了更大的模型,速度不如YOLOv2。
损失函数和YOLOv2一样,同时是偏差处理的方式。
在当时对比的检测器为SSD和RetinaNet,是比那些检测器要快一些的。在0.5-0.95的mAP指标上,YOLOv3略有不足。但作者认为这不重要,是mAP这个指标不足以反馈检测器的效果。其认为使用0.5的mAP足以。
论文简介
Bounding Box Prediction
bbox的预测上,和YOLOv2一样,使用Logistic回归的方式处理,如下列公式所示,模型预测的( t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th)处理后得到最终预测值( b x , b y , b w , b h b_x,b_y,b_w,b_h bx,by,bw,bh)。
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h \begin{aligned} b_x&=\sigma(t_x)+c_x \\ b_y&=\sigma(t_y)+c_y \\ b_w&=p_we^{t_w} \\ b_h&=p_he^{t_h} \\ \end{aligned} bxbybwbh=σ(tx)+cx=σ(ty)+cy=pwetw=pheth
其中, ( c x , c y ) (c_x,c_y) (cx,cy)是边框中心对每个格子左上角的偏离; ( p w , p h ) (p_w,p_h) (pw,ph)是预设anchor boxes的宽长。
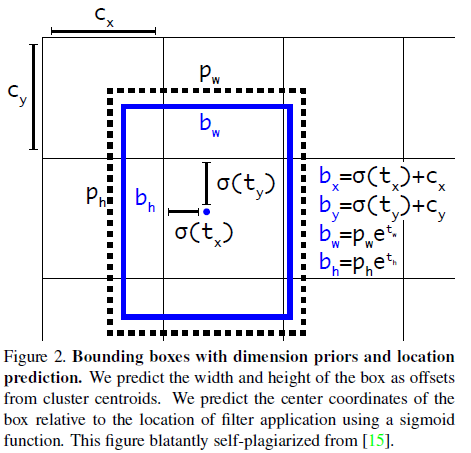
边框预测使用的损失函数是MSE Loss。
框的置信度也使用logistic处理。
若预测的bounding box和GT bbox重叠不是最多的,但又超过了一个阈值(文中选为
0.5
0.5
0.5),那么在训练中作者选择忽略这些bbox,就像Faster RCNN一样。但和Faster RCNN不一样的是,YOLOv3对每个GT对象只赋予一个正目标。若非正目标,则对坐标和类别不产生Loss,只对对象置信度(objectness)产生loss。
Class Prediction
类别的损失函数使用二元交叉熵。因为作者认为目标可能是多类别的(对于一些数据集),且Softmax也不是好性能的必要选项。因此选择使用Logistic回归代替Softmax。
Predictions Across Scales
YOLOv3引入了多尺度预测的概念,也就是在不同层级的feature map预测bbox。YOLOv3在3个尺度上预测bbox,在 N × N N\times N N×N大小的feature maps上,输出的tensor大小为 N × N × [ 3 ∗ ( 4 + 1 + c l a s s e s ) ] N\times N\times [3*(4+1+classes)] N×N×[3∗(4+1+classes)],其中 3 3 3为每个尺度上预测 3 3 3个bbox,有 3 3 3个预设的anchor, 4 4 4为bbox的4个项 { t x , t y , t w , t h } \{t_x,t_y,t_w, t_h\} {tx,ty,tw,th}, 1 1 1为bbox的置信度,classes在coco数据集中为 80 80 80;
在每个层级的特征提取上,使用上采样的特征以及对应backbone中的特征进行concat,意在使用上采样特征的高级语义特征和backbone中的细粒度特征。
YOLOv3的原始网络中,一共在 3 3 3个层级上预测,每个层级上使用 3 3 3个anchor,故一共有 9 9 9个anchor,需要使用kmeans聚类 9 9 9个簇。
Feature Extractor
YOLOv3使用的backbone网络是Darknet-53,比YOLOv2使用的backbone(Darknet-19)要大不少,但对比ResNet101和ResNet152要好一些。
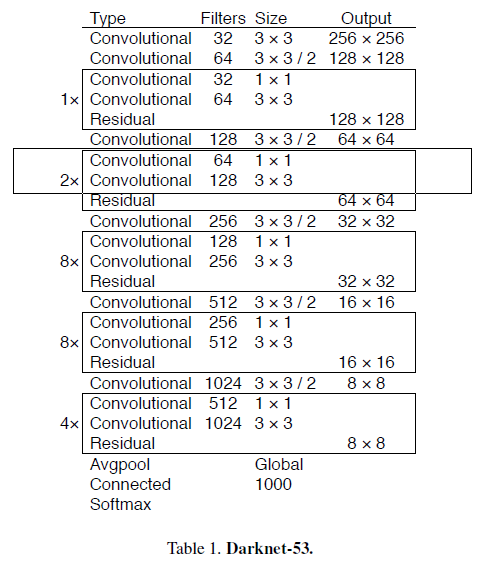
下面的速度对比测试,是在TitanX的GPU上,使用 256 × 256 256\times 256 256×256分辨率的输入进行测试的。

Training
在训练过程中,没有使用硬负样本挖掘或其他类似的东西。有使用多尺度训练、一些数据增强,BN等一些标准方法。
论文实验
在COCO数据集上,与当时一些检测器进行对比,可以看到0.5IOU阈值的时候,Yolov3还是很强的,能和RetinaNet差不多,比SSD强不少。但当IOU阈值提升,YOLOv3的性能急剧下降,这意味着YOLOv3不能很好地对齐目标。
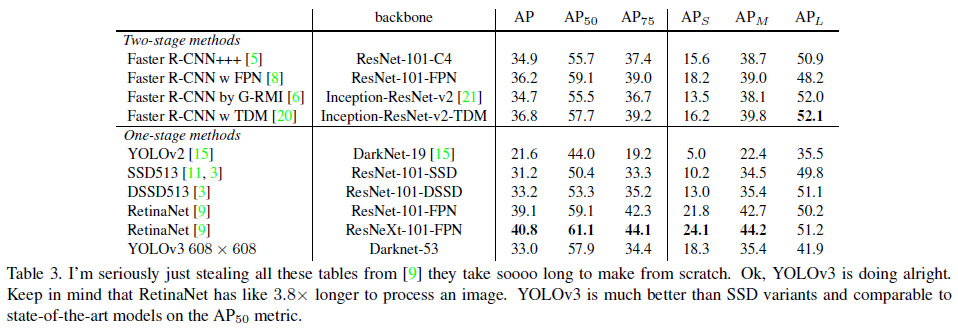
从上表也可以看到,YOLOv3在小目标预测上表现的还可以(对比YOLOv2好很多)。但在 A P M AP_M APM和 A P L AP_L APL上表现地相对差。
消融学习
使用线性激活函数来预测bbox的x和y为w和h的倍数,发现这样会降低模型的稳定性,效果不佳。
直接预测x和y,而不是使用logistic处理,会掉mAP。
使用Focal Loss也会掉 2 2 2个点的mAP。作者猜测可能是YOLOv3对Focal Loss试图解决的点有鲁棒性。因为YOLOv3具有单独的对象预测和条件类预测[conditional loss]。因此,对于大多数实例,类预测没有损失(作者猜测的,也不确定)。
双重IoU阈值和真实性分配的方式,对于YOLOv3也效果不佳。像Faster RCNN一样,在训练中使用两个IoU阈值,重叠率大于 0.7 0.7 0.7的,作为正样本,[0.3, 0.7]的IoU阈值选择忽略,小于 0.7 0.7 0.7的是负样本。
经过上述尝试,作者认为当前YOLOv3的训练策略是局部最优的。这些技术的其中一部分可能最终会产生良好的效果,但也许它们需要一些调整来稳定训练。
作者小结
作者认为,YOLOv3是一个好的检测器,又快又准确。在COCO上,YOLOv3在0.5到0.95的mAP指标不是很好,但在 0.5 0.5 0.5的指标上表现地很好。引用Russakovsky的结论:人类很难区分IOU为 0.3 0.3 0.3和 0.5 0.5 0.5的区别。作者认为,如果人类很难分辨出差异,那指标能有多重要呢?作者认为 0.5 0.5 0.5的IOU阈值已经足够有代表性了。















 1952
1952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









