







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 跨平台支持:UI-TARS 支持桌面、移动和网页环境,提供标准化的行动定义,兼容多种平台操作。
- 多模态感知:能够处理文本、图像等多种输入形式,实时感知和理解动态界面内容。
- 自动化任务执行:通过自然语言指令,自动化完成打开应用、搜索信息、填写表单等复杂任务。
正文(附运行示例)
UI-TARS 是什么
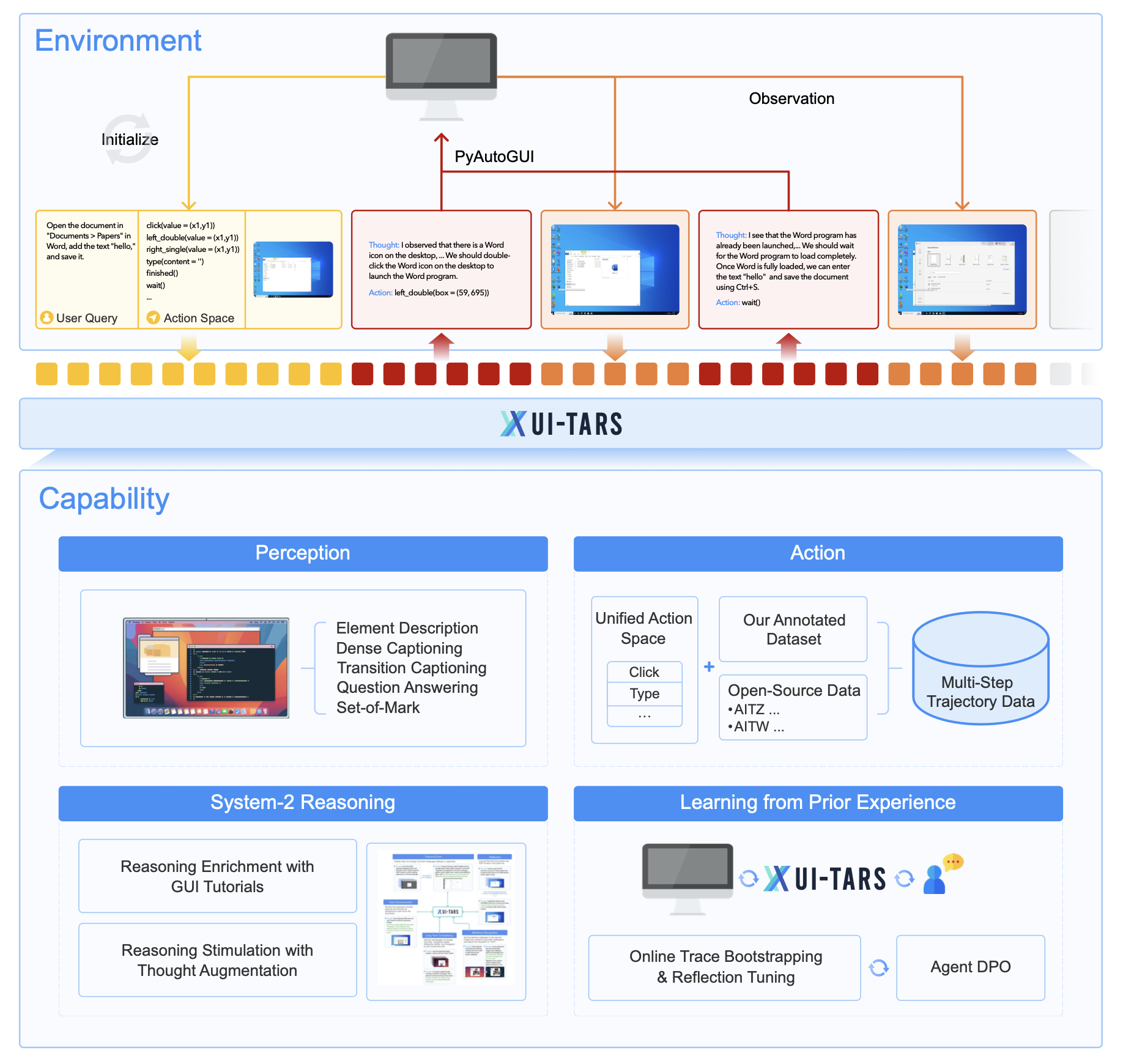
UI-TARS 是字节跳动推出的新一代原生图形用户界面(GUI)代理模型,旨在通过自然语言实现对桌面、移动设备和网页界面的自动化交互。它具备强大的感知、推理、行动和记忆能力,能够实时理解动态界面,并通过多模态输入(如文本、图像)执行复杂的任务。
UI-TARS 的核心优势在于跨平台的标准化行动定义,支持桌面、移动和网页等多种环境。结合了快速直观反应和复杂任务规划的能力,支持多步推理、反思和错误纠正。此外,它还具备短期和长期记忆功能,能够更好地适应动态任务需求。
UI-TARS 的主要功能
- 多模态感知:UI-TARS 能处理文本、图像等多种输入形式,实时感知和理解动态界面内容,支持跨平台(桌面、移动、网页)的交互。
- 自然语言交互:用户可以通过自然语言指令与 UI-TARS 对话,完成任务规划、操作执行等复杂任务。支持多步推理和错误纠正,能像人类一样处理复杂的交互场景。
- 跨平台操作:支持桌面、移动和网页环境,提供标准化的行动定义,同时兼容平台特定的操作(如快捷键、手势等)。
- 视觉识别与交互:UI-TARS 能通过截图和视觉识别功能,精准定位界面元素,并执行鼠标点击、键盘输入等操作,适用于复杂的视觉任务。
- 记忆与上下文管理:具备短期和长期记忆能力,能够捕捉任务上下文信息,保留历史交互记录,从而更好地支持连续任务和复杂场景。
- 自动化任务执行:可以自动化完成一系列任务,如打开应用、搜索信息、填写表单等,提高用户的工作效率。
- 灵活部署:支持云端部署(如 Hugging Face 推理端点)和本地部署(如通过 vLLM 或 Ollama),满足不同用户的需求。
- 扩展性:UI-TARS 提供了丰富的 API 和开发工具,方便开发者进行二次开发和集成。
UI-TARS 的技术原理
- 增强感知能力:UI-TARS 使用大规模的 GUI 截图数据集进行训练,能对界面元素进行上下文感知和精准描述。通过视觉编码器实时抽取视觉特征,实现对界面的多模态理解。
- 统一行动建模:UI-TARS 将跨平台操作标准化,定义了一个统一的行动空间,支持桌面、移动端和 Web 平台的交互。通过大规模行动轨迹数据训练,模型能够实现精准的界面元素定位和交互。
- 系统化推理能力:UI-TARS 引入了系统化推理机制,支持多步任务分解、反思思维和里程碑识别等推理模式。能在复杂任务中进行高层次规划和决策。
- 迭代训练与在线反思:解决数据瓶颈问题,UI-TARS 通过自动收集、筛选和反思新的交互轨迹进行迭代训练。在虚拟机上运行,能从错误中学习并适应未预见的情况,减少人工干预。
如何运行 UI-TARS
云端部署
推荐使用 HuggingFace Inference Endpoints 进行快速部署。我们提供了两种文档供用户参考:
- 英文版:https://juniper-switch-f10.notion.site/GUI-Model-Deployment-Guide-17b5350241e280058e98cea60317de71
- 中文版:https://bytedance.sg.larkoffice.com/docx/TCcudYwyIox5vyxiSDLlgIsTgWf#U94rdCxzBoJMLex38NPlHL21gNb
本地部署 [vLLM]
推荐使用 vLLM 进行快速部署和推理。你需要使用 vllm>=0.6.1。
pip install -U transformers
VLLM_VERSION=0.6.6
CUDA_VERSION=cu124
pip install vllm==${VLLM_VERSION} --extra-index-url https://download.pytorch.org/whl/${CUDA_VERSION}
下载模型
我们在 Hugging Face 上提供了三种模型大小:2B、7B 和 72B。为了获得最佳性能,推荐使用 7B-DPO 或 72B-DPO 模型(取决于你的 GPU 配置):
- 2B-SFT:https://huggingface.co/bytedance-research/UI-TARS-2B-SFT
- 7B-SFT:https://huggingface.co/bytedance-research/UI-TARS-7B-SFT
- 7B-DPO:https://huggingface.co/bytedance-research/UI-TARS-7B-DPO
- 72B-SFT:https://huggingface.co/bytedance-research/UI-TARS-72B-SFT
- 72B-DPO:https://huggingface.co/bytedance-research/UI-TARS-72B-DPO
启动 OpenAI API 服务
运行以下命令启动一个兼容 OpenAI 的 API 服务:
python -m vllm.entrypoints.openai.api_server --served-model-name ui-tars --model <path to your model>
然后你可以使用以下代码与模型进行交互:
import base64
from openai import OpenAI
instruction = "search for today's weather"
screenshot_path = "screenshot.png"
client = OpenAI(
base_url="http://127.0.0.1:8000/v1",
api_key="empty",
)
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
```\nThought: ...
Action: ...\n```
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
left_double(start_box='<|box_start|>(x1,y1)<|box_end|>')
right_single(start_box='<|box_start|>(x1,y1)<|box_end|>')
drag(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
hotkey(key='')
type(content='') #If you want to submit your input, use \"\
\" at the end of `content`.
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', direction='down or up or right or left')
wait() #Sleep for 5s and take a screenshot to check for any changes.
finished()
call_user() # Submit the task and call the user when the task is unsolvable, or when you need the user's help.
## Note
- Use Chinese in `Thought` part.
- Summarize your next action (with its target element) in one sentence in `Thought` part.
## User Instruction
"""
with open(screenshot_path, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode("utf-8")
response = client.chat.completions.create(
model="ui-tars",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt + instruction},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{encoded_string}"}},
],
},
],
frequency_penalty=1,
max_tokens=128,
)
print(response.choices[0].message.content)
资源
- GitHub 仓库:https://github.com/bytedance/UI-TARS
- arXiv 技术论文:https://arxiv.org/pdf/2501.12326
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









