







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
大家好,我是蚝油菜花,今天跟大家分享一下 FireRedASR 这个小红书开源的工业级自动语音识别模型。
🚀 快速阅读
FireRedASR 是小红书开源的工业级自动语音识别模型,支持普通话、中文方言和英语。该模型在普通话 ASR 基准测试中达到了新的最佳水平(SOTA),并在歌词识别方面表现出色。
- 核心功能:FireRedASR 包含两个版本,FireRedASR-LLM 采用 Encoder-Adapter-LLM 框架,专注于极致的语音识别精度;FireRedASR-AED 采用基于注意力的编码器-解码器架构,平衡了高准确率与推理效率。
- 技术原理:FireRedASR-LLM 结合了大型语言模型(LLM)的能力,实现 SOTA 性能;FireRedASR-AED 利用经典的 AED 架构,确保高效推理。
FireRedASR 是什么
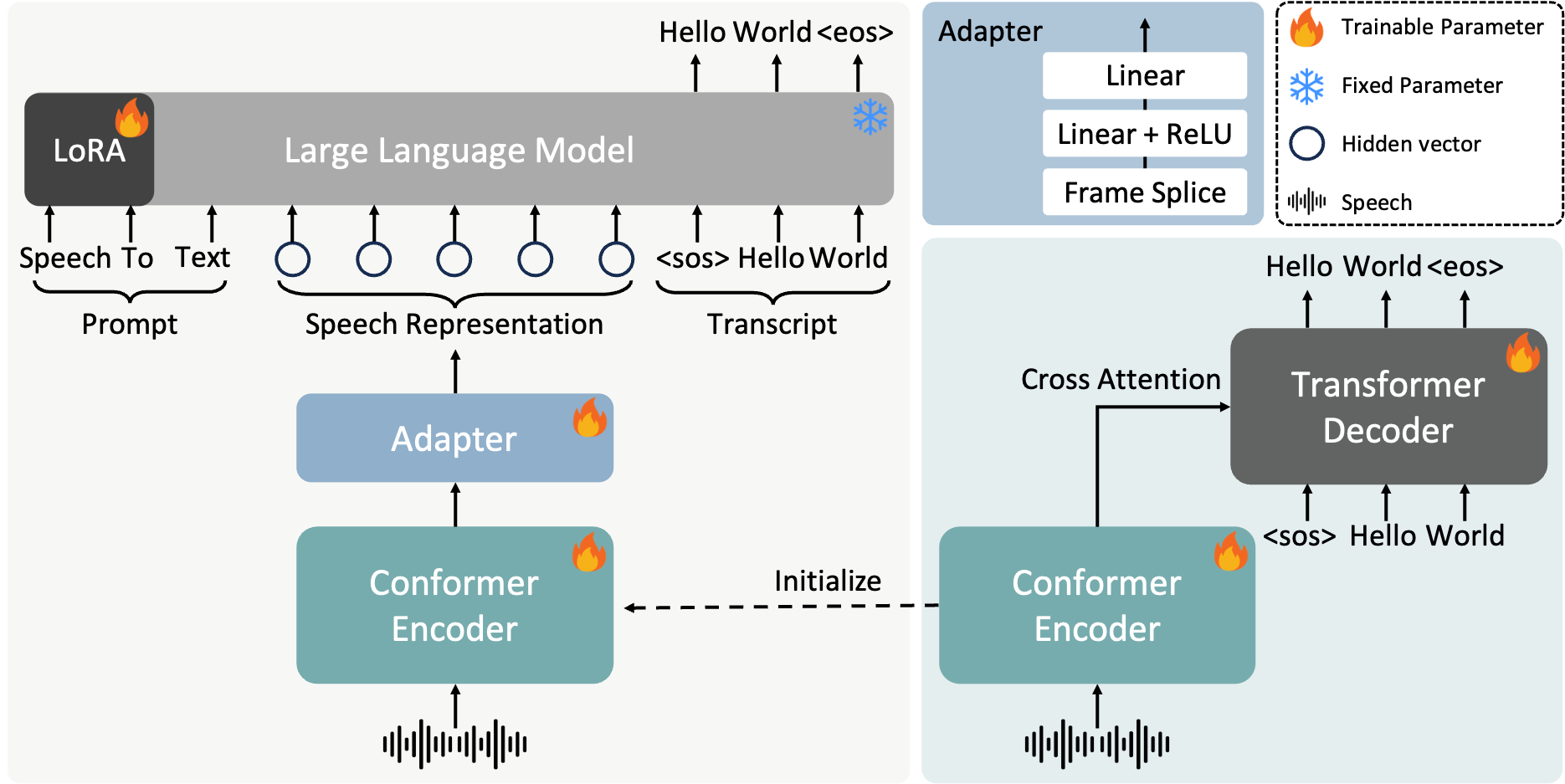
FireRedASR 是小红书开源的工业级自动语音识别(ASR)模型家族,支持普通话、中文方言和英语。它在普通话 ASR 基准测试中达到了新的最佳水平(SOTA),并在歌词识别方面表现出色。模型家族包含两个主要版本:
-
FireRedASR-LLM:采用 Encoder-Adapter-LLM 框架,基于大型语言模型(LLM)的能力,实现 SOTA 性能,支持无缝端到端语音交互。在普通话基准测试中平均字符错误率(CER)为 3.05%,相比之前的 SOTA 模型(3.33%)降低了 8.4%。
-
FireRedASR-AED:采用基于注意力的编码器-解码器(AED)架构,平衡高性能和计算效率,可作为基于 LLM 的语音模型中的有效语音表示模块。在普通话基准测试中平均 CER 为 3.18%,优于拥有超过 12B 参数的 Seed-ASR。
FireRedASR 的主要功能
- 高精度语音识别:FireRedASR 包含两个版本,FireRedASR-LLM 采用 Encoder-Adapter-LLM 框架,专注于极致的语音识别精度;FireRedASR-AED 采用基于注意力的编码器-解码器架构,平衡了高准确率与推理效率。
- 高效推理:FireRedASR-AED 参数量为 1.1B,平衡了高准确率与推理效率,适用于多种应用场景。
- 多场景适配:FireRedASR 在短视频、直播、语音输入和智能助手等多种日常场景下表现出色,与业内领先的 ASR 服务提供商和 Paraformer-Large 相比,CER 相对降低 23.7%~40.0%。
- 歌词识别能力:在歌词识别场景中,FireRedASR-LLM 的 CER 实现了 50.2%~66.7% 的相对降低,展现了极强的适配能力。
- 多语言支持:FireRedASR 支持普通话,在中文方言和英语语音识别方面表现出色,进一步拓宽了其应用范围。
- 开源与社区支持:FireRedASR 的模型和推理代码均已开源,推动语音识别技术的社区驱动改进和学术研究。
FireRedASR 的技术原理
FireRedASR-LLM
- Conformer 基础编码器:负责提取语音特征,生成连续的语音表示。
- 轻量级适配器:将编码器的输出转换为与 LLM 语义空间匹配的表示。
- 预训练文本 LLM:基于 Qwen2-7B-Instruct 初始化,用于生成最终的文本输出。
- 训练策略:在训练过程中,编码器和适配器是可训练的,LLM 的大部分参数保持固定,仅通过 Low-Rank Adaptation(LoRA)进行微调。确保编码器和适配器能有效地将语音特征映射到 LLM 的语义空间,同时保留 LLM 的预训练能力。
- 输入与推理:在推理时,输入包括提示(prompt)和语音,LLM 执行 next-token-prediction,生成识别文本。
FireRedASR-AED
- Conformer 编码器:基于 Conformer 模型处理语音特征,能同时捕捉局部和全局依赖关系。
- Transformer 解码器:采用 Transformer 架构进行序列转换,包含多头自注意力模块和前馈模块。
- 输入特征:输入特征为 80 维的 log Mel 滤波器组,经过全局均值和方差归一化处理。
- 训练数据:训练数据包含约 7 万小时的高质量普通话音频数据,以及约 1.1 万小时的英语音频数据。
如何运行 FireRedASR
1. 设置环境
创建一个 Python 环境并安装依赖项:
$ git clone https://github.com/FireRedTeam/FireRedASR.git
$ conda create --name fireredasr python=3.10
$ pip install -r requirements.txt
设置 Linux PATH 和 PYTHONPATH:
$ export PATH=$PWD/fireredasr/:$PWD/fireredasr/utils/:$PATH
$ export PYTHONPATH=$PWD/:$PYTHONPATH
将音频转换为 16kHz 16-bit PCM 格式:
ffmpeg -i input_audio -ar 16000 -ac 1 -acodec pcm_s16le -f wav output.wav
2. 快速启动
运行示例脚本:
$ cd examples/
$ bash inference_fireredasr_aed.sh
$ bash inference_fireredasr_llm.sh
3. 命令行使用
查看帮助信息:
$ speech2text.py --help
使用 AED 模型进行语音识别:
$ speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "aed" --model_dir pretrained_models/FireRedASR-AED-L
使用 LLM 模型进行语音识别:
$ speech2text.py --wav_path examples/wav/BAC009S0764W0121.wav --asr_type "llm" --model_dir pretrained_models/FireRedASR-LLM-L
4. Python 使用
from fireredasr.models.fireredasr import FireRedAsr
batch_uttid = ["BAC009S0764W0121"]
batch_wav_path = ["examples/wav/BAC009S0764W0121.wav"]
# 使用 FireRedASR-AED
model = FireRedAsr.from_pretrained("aed", "pretrained_models/FireRedASR-AED-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"nbest": 1,
"decode_max_len": 0,
"softmax_smoothing": 1.0,
"aed_length_penalty": 0.0,
"eos_penalty": 1.0
}
)
print(results)
# 使用 FireRedASR-LLM
model = FireRedAsr.from_pretrained("llm", "pretrained_models/FireRedASR-LLM-L")
results = model.transcribe(
batch_uttid,
batch_wav_path,
{
"use_gpu": 1,
"beam_size": 3,
"decode_max_len": 0,
"decode_min_len": 0,
"repetition_penalty": 1.0,
"llm_length_penalty": 0.0,
"temperature": 1.0
}
)
print(results)
资源
- GitHub 仓库:https://github.com/FireRedTeam/FireRedASR
- HuggingFace 仓库:https://huggingface.co/FireRedTeam/FireRedASR-AED-L
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









