







文章目录
参考:《大模型导论》
预训练+微调就是不要从头开始造轮子,在已有大模型基座上,针对特定领域进行少量语料的训练
全量微调硬件资源消耗巨大、时间成本高,冻结预训练语言模型的大多数层,微调下游层,效果不是很好PETF(高效参数微调)运用越来越多,低硬件、训练少量参数,取得与全量微调近似的效果
1. 监督微调 SFT
步骤:
- 预训练(大数据集)
- 微调(目标任务数据集)
- 评估(在目标任务上的性能)
缺点:
- 依赖
大量的标注数据 - 依赖 基座模型的能力
非主流了
2. 高效参数微调 PEFT
目的:减少微调参数量
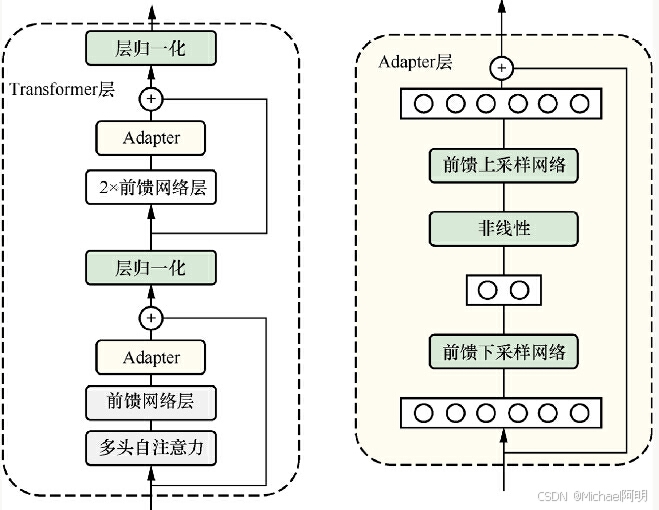
2.1 适配微调 Adapter tuning
添加 Adapter 结构
2.2 Prefix tuning
在输入token前构造虚拟token,只训练前缀参数
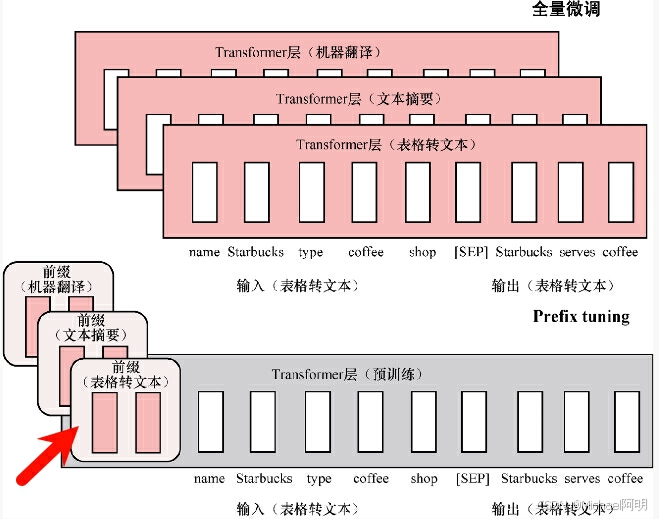
实验发现,该方法训练不稳定、模型表现存在轻微下滑,训练时加入 MLP 多层感知机,推理时去掉 MLP
2.3 Prompt tuning
将任务的输入嵌入到一个提示上下文中,让大模型根据这段提示推断任务目标。通过优化提示的表示来引导模型更好地完成特定任务,而无需修改模型本身
-
少量参数优化
不调整模型的预训练权重,仅在模型输入前添加一个可学习的嵌入向量,并对其进行训练。 -
迁移性强
Prompt Tuning 在小样本场景下表现优异,尤其适用于需要对多个任务快速迁移的场景。 -
高效
减少训练时间和存储资源需求,适用于资源受限的设备。 -
与预训练模型兼容
依赖模型的大规模预训练能力,Prompt Tuning 可以直接在各类预训练模型上应用。
用代码理解:
软提示
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载预训练模型和分词器
model_name = "gpt-neo-125M"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 定义软提示的嵌入向量
prompt_embeddings = torch.randn(5, model.config.hidden_size, requires_grad=True)
# 可学习向量
# 输入数据
inputs = tokenizer("What is the capital of China?", return_tensors="pt")
inputs_embeds = model.get_input_embeddings()(inputs.input_ids)
# 拼接软提示嵌入
inputs_embeds = torch.cat([prompt_embeddings, inputs_embeds], dim=1)
# 模型前向传播
outputs = model(inputs_embeds=inputs_embeds)
print(outputs.logits)
硬提示:在提示词上做文章,不需要训练
from transformers import pipeline
# 加载预训练模型
classifier = pipeline("fill-mask", model="bert-base-uncased")
# 定义硬提示模板
template = "The sentiment of this text is [MASK]."
# 输入文本
text = "I love this movie! It's fantastic and heartwarming."
# 将输入文本嵌入到提示模板中
input_text = f"{text} {template}"
# 模型预测
output = classifier(input_text)
# 显示结果
for prediction in output:
print(f"Predicted word: {prediction['token_str']}, Confidence: {prediction['score']:.4f}")
2.4 P-tuning v1/v2
与Prefix tuning相比,P-tuning v1 没有将额外的可训练部分置于输入的Token之前,而是选择不固定的位置
Prefix tuning在ransformer架构中的每个注意力层中都加入前缀,并使用MLP进行初始化。而P-tuning v1则只在输入时加入嵌入,使用LSTM和MLP结构进行初始化
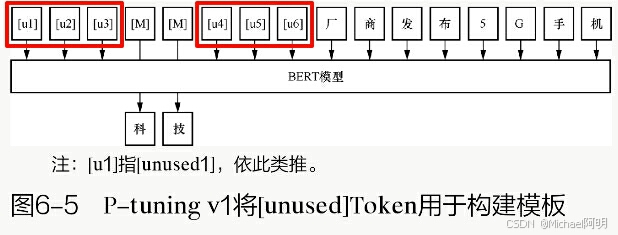
P-tuning v2 在多层输入序列都加入 Prompt Token,可学习参数更多,表达能力更强
2.5 低秩适配 LoRA
LoRA 的数学依据来源于矩阵的低秩近似理论,可以看下矩阵的SVD奇异值分解。
在预训练权重外加入旁路低秩矩阵A、B,只训练 A\B的参数

r 一般选择:1、2、4、8,领域跨度大的,可适当增大
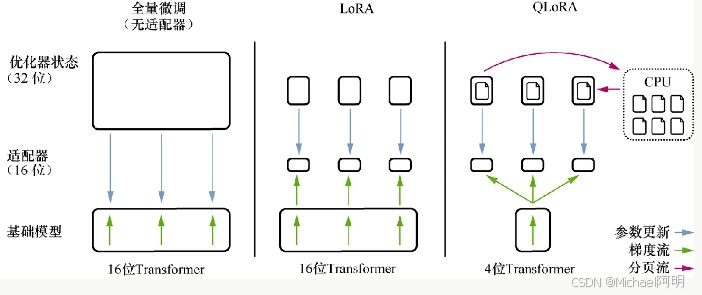
2.6 QLoRA
Q 是量化的缩写
- 4位精度微调,训练过程中将 4位精度数据反量化位16位精度
- 分页优化,GPU空间不够时,将优化器状态转移到 CPU内存
2.7 IA3
IA3 的诞生背景是为了改进LoRA。
- 通过 学习向量 对
激活层加权进行缩放,从而获得更强的性能,仅引入相对少量的新参数 - 这些学习后的向量被注入Transformer架构的
注意力层和前馈网络层中 - 可以大幅减少可训练参数的数量
2.8 AdaLoRA
传统 LoRA 使用固定的低秩参数 r,但不同的层对任务的敏感性和重要性不同,固定 r 可能导致资源分配不均
- 在 AdaLoRA 中,r 不是固定值,而是
每层动态调整的 裁剪对角矩阵中秩较小的- 适合资源有限的场景,如边缘设备上的大模型部署
3. PEFT 库
pip install peft
https://pypi.org/project/peft/
- 不同的微调,参数不一样
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1
)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
"trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282"
可以看到需要训练的参数占比只有 0.19%
- 保存模型
model.save_pretrained('model_path')
- 推理
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
model = AutoPeftModelForCausalLM.from_pretrained("ybelkada/opt-350m-lora").to("cuda")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
4. SFT、PEFT 对比
| 特性 | SFT | PEFT |
|---|---|---|
| 参数更新范围 | 全部参数 | 部分参数 |
| 效率 | 高计算和存储成本 | 高效,资源需求低 |
| 性能 | 通常更优 | 与 SFT 接近 |
| 存储需求 | 整个模型 | 只需存储小参数模块 |
| 适用场景 | 高性能单任务优化 | 多任务适配,资源有限时的优选 |


















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











