







TCJA-SNN: 时空联合注意力机制在脉冲神经网络中的应用
Zhu R J, Zhang M, Zhao Q, et al. Tcja-snn: Temporal-channel joint attention for spiking neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024.
摘要
脉冲神经网络 (Spiking Neural Networks, SNNs) 因其生物合理性、能量效率和强大的时空(spatio-temporal)信息表示能力而受到广泛关注。鉴于注意力机制在提升神经网络性能中的重要作用,将注意力机制整合到 SNNs 中展示了巨大的潜力,可以实现高效能和高性能计算。
在本文中,我们提出了一种新颖的 SNNs 时空联合注意力机制,称为 TCJA-SNN。所提出的 TCJA-SNN 框架能够 有效地从空间和时间两个维度评估脉冲序列的重要性 。
具体来说,我们的主要技术贡献包括:
1)我们通过压缩操作将脉冲流(spike stream)压缩为一个平均矩阵,然后利用基于高效一维卷积(1-D convolutions)的两种局部注意力机制,分别在时间和通道层面促进全面的 特征提取 。
2)我们引入了一种新方法——交叉卷积融合 (Cross Convolutional Fusion, CCF) 层,用于建模时间和通道范围之间的相互依赖性。这一层有效地打破了这两个维度的独立性,实现了特征之间的交互。
实验结果表明,所提出的 TCJA-SNN 在所有标准静态和神经形态数据集(包括 FashionMNIST、CIFAR10、CIFAR100、CIFAR10-DVS、N-Caltech 101 和 DVS128 Gesture)上均优于现有最先进的方法。此外,我们通过利用变分自编码器 (Variational Autoencoder, VAE) 将 TCJA-SNN 框架有效地应用于 图像生成任务 。据我们所知,这是首次将 SNN-注意力机制用于高层分类和低层生成任务。我们的实现代码可在 ridgerchu/TCJA: [TNNLS 2024] Implementation of "TCJA-SNN: Temporal-Channel Joint Attention for Spiking Neural Networks"获取。
关键词
脉冲神经网络(Spiking neural networks),时空信息(Spatiotemporal information),注意力机制(Attention mechanism),神经形态数据集(Neuromorphic datasets.)
I. 介绍
脉冲神经网络 (Spiking Neural Networks, SNNs) 因其相比传统人工神经网络 (Artificial Neural Networks, ANNs) 更低的能耗和更高的鲁棒性而成为一个有前途的研究领域 [1], [2]。这些特性使得 SNNs 在时间数据处理和功耗关键应用中具有很大潜力 [1], [3]。
近年来,通过将 反向传播 引入 SNNs 中取得了显著进展 [3]–[10],这使得可以将各种 ANN 模块整合到 SNN 架构中,包括批归一化块 [11] 和残差块 [12]。通过这些基于 ANN 的方法,我们可以在保留 SNN 二进制脉冲特性所带来的能效的同时,训练大规模的 SNNs。
尽管取得了显著进展,但由于其独特的训练模式,SNNs 尚未能充分利用深度学习的卓越表示能力,主要是因为它们 难以有效地建模复杂的通道时间关系 。
为了解决这一问题,Zheng 等人 [11] 引入了一种用于时间维度的批归一化方法,克服了梯度消失和阈值输入平衡问题。
[11] H. Zheng, Y. Wu, L. Deng, Y. Hu, and G. Li, “Going Deeper With Directly-Trained Larger Spiking Neural Networks,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021, pp. 11 06211 070.
另一方面,Wu 等人 [13] 提出了一种名为 NeuNorm 的方法,解决了通道层面的挑战。NeuNorm 包括一个辅助神经元,该神经元调整由前一层生成的刺激强度,在提高性能的同时,模拟视网膜(retina)和附近细胞的活动,以增加生物合理性。
如何理解通道方面的挑战?
[13] Y. Wu, L. Deng, G. Li, J. Zhu, Y. Xie, and L. Shi, “Direct Training for Spiking Neural Networks: Faster, Larger, Better,” in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2019, pp. 13111318.
然而,现有的方法分别处理时间和通道信息,导致联合信息提取的能力有限。
鉴于 SNNs 在每个时间步重用(reuse)网络参数,存在未开发(untapped)的潜力,可以在时间和通道维度上进行重新校准。
特别是 Yao 等人 [14] 提出的 TA-SNN。在 ANNs 中的先前研究 [15], [16] 经常利用注意力机制来解决多维动态问题带来的挑战 。注意力机制受人类认知过程的启发,使得选择性地关注相关信息,同时忽略无关数据。这种方法在 SNNs 领域显示出潜力,值得进一步探索 [14]。
[14] M. Yao, H. Gao, G. Zhao, D. Wang, Y. Lin, Z. Yang, and G. Li, “Temporal-wise Attention Spiking Neural Networks for Event Streams Classification,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 10 201–10 210.
例如,在神经科学领域,Bernert 等人 [17] 提出了一种基于注意力的脉冲时序依赖性可塑性 (Spike-Timing-Dependent Plasticity, STDP) SNN 来解决脉冲分类问题。
[17] M. Bernert and B. Yvert, “An Attention-Based Spiking Neural Network for Unsupervised Spike-Sorting,” International Journal of Neural Systems, vol. 29, no. 8, pp. 1 850 059:1–1 850 059:19, 2019.
此外,Yao 等人 [14] 将通道注意力块整合到 SNN 的时间输入中,如图 1-a 所示,在训练期间评估帧的重要性,并在推理期间排除无关帧。
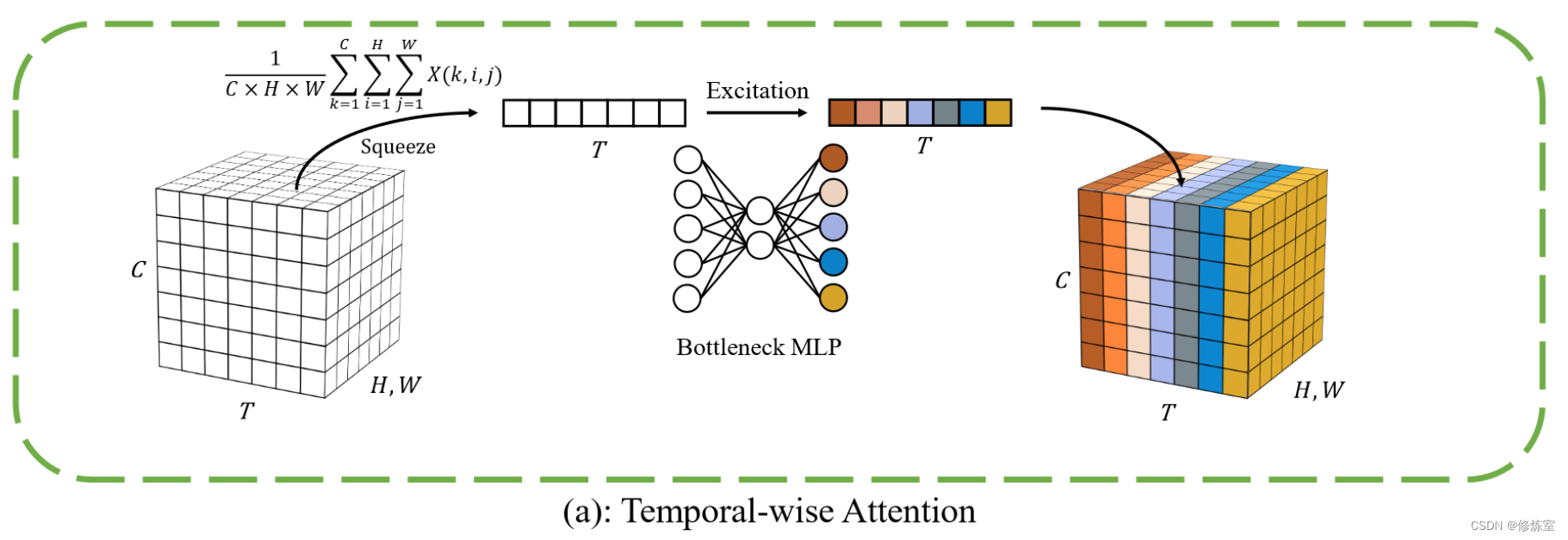
尽管仅在时间维度上使用了注意力,但是这种注意力机制也显著提高了网络性能。
在本文中,我们在 SNNs 中引入了时间和通道注意力机制,并通过高效的一维卷积实现;图 1-b 显示了整体结构。
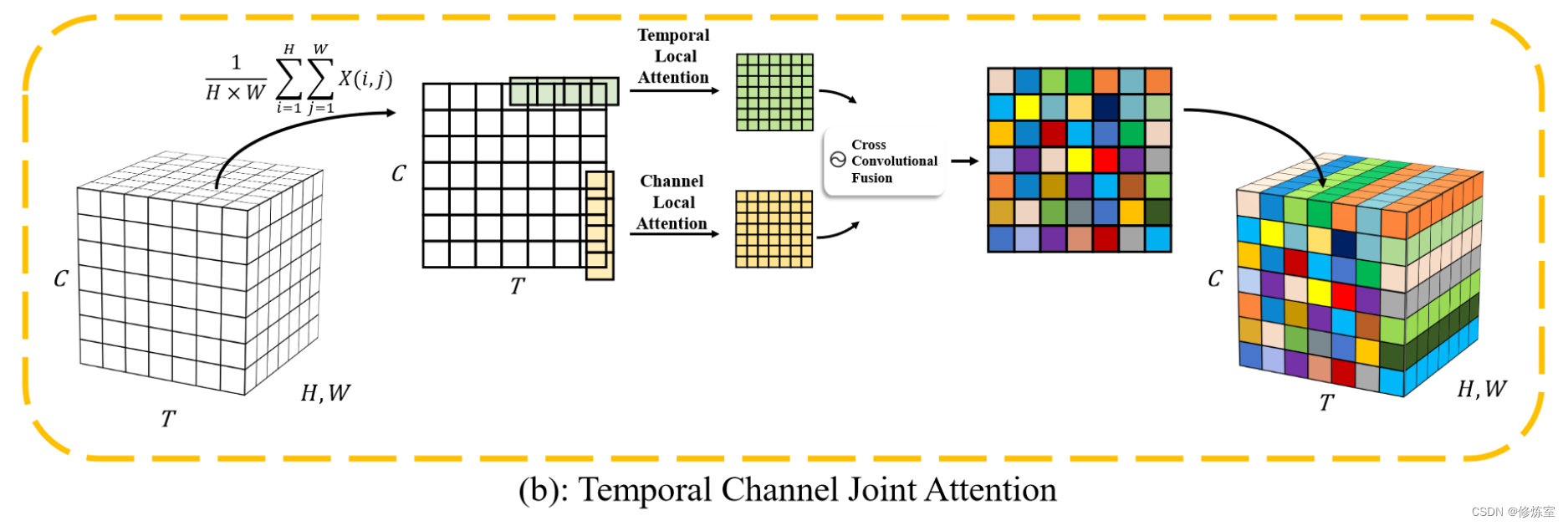
图 1. 我们的时间-通道联合注意力与现有的时间注意力 [14] 有何不同,后者通过 挤压 和 激励 模块估计每个时间步骤的显着性。
- T 表示时间步骤
- C 表示通道
- H、W 表示空间分辨率。
通过利用两个独立的 1-D 卷积层和交叉卷积融合 (CCF) 操作,我们的时间-通道联合注意力建立了时间步骤和通道之间的关联。
我们认为这种协同机制可以增强学习特征的区分能力,使得 SNNs 中的时间通道学习变得更加容易。
本工作的主要贡献可以总结如下:
1)我们通过协同考虑时间和通道注意力,将一个即插即用(plug-and-play)块引入 SNNs 中,这在同一阶段建模时间和通道信息,达到更好的适应性和生物解释性。据我们所知,这是 首次尝试将时间通道注意力机制整合到最广泛使用的基于 LIF 的 SNNs 中 。
2)提出了一种具有交叉感受野的交叉卷积融合 (Cross Convolutional Fusion, CCF) 操作,以利用关联信息。它不仅利用卷积的优点来最小化参数,还有效地整合了时间和通道维度的特征。
3)实验结果表明,TCJA-SNN 在静态和神经形态数据集的分类任务中优于以往的方法,并且在 生成任务 中也表现良好。
II. 相关工作和动机
A. 脉冲神经网络的训练技术
近年来,直接应用各种人工神经网络 (Artificial Neural Networks, ANNs) 算法来训练深度脉冲神经网络 (Spiking Neural Networks, SNNs) 的方法,包括基于梯度下降的方法,已经得到了广泛关注。然而,脉冲的不可微性是一个重大挑战。
用于触发脉冲的 Heaviside 函数的导数在除原点外的所有地方都为零,使得基于梯度的学习不可行 。为克服这一障碍,常用的解决方案是
- ANN 到 SNN [18][20]
- 代理梯度下降方法 (Surrogate Gradient Descent Method) [21]–[28]。
在前向传递过程中,保留 Heaviside 函数,而在反向传递过程中,用代理函数替代它。代理函数的 一种简单选择是脉冲操作符 (Spike-Operator) [29],其梯度类似于平移后的 ReLU 函数 。
[29] J. K. Eshraghian, M. Ward, E. Neftci, X. Wang, G. Lenz, G. Dwivedi, M. Bennamoun, D. S. Jeong, and W. D. Lu, “Training Spiking Neural Networks Using Lessons From Deep Learning,” ArXiv, 2021.
在我们的工作中,我们超越了传统的代理梯度方法,引入了另外两种代理函数:
- ATan 代理函数
- 由 [30] 和 [31] 设计的三角形代理函数。
[30] W. Fang, Z. Yu, Y. Chen, T. Masquelier, T. Huang, and Y. Tian, “Incorporating Learnable Membrane Time Constant To Enhance Learning of Spiking Neural Networks,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 26612671.
[31] G. Bellec, D. Salaj, A. Subramoney, R. Legenstein, and W. Maass, “Long short-term memory and learning-to-learn in networks of spiking neurons,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018.
这些代理函数具有 激活特定样本范围的能力,使其特别适合训练深度 SNNs 。通过扩展代理函数的种类,我们旨在增强训练过程并提高深度 SNNs 的性能。
B. 注意力机制在卷积神经网络中的应用
在人工神经网络 (ANNs) 领域,Hu 等人 [15] 引入的挤压与激励 (Squeeze and Excitation, SE) 块已被证明是增强表示的高效模块。 SE 块可以无缝地整合到网络中,仅需增加少量参数即可重新校准通道信息 。
通过挤压和全连接操作,SE 块允许网络为每个通道学习一个可训练的缩放因子。这个重新校准(recalibration)过程显著提高了各个通道的区分能力。
最近,Yao 等人 [14] 将 SE 块的应用 扩展到脉冲神经网络 (SNNs) 中,形成了一种时间注意力机制 。这一创新方法使 SNNs 能够 识别关键的时间帧 ,而不受噪声或干扰的影响。
通过整合时间注意力机制,该方法在各种数据集上实现了最先进的性能。这一成就提供了有力的证据,证明注意力机制在 SNNs 中具有巨大的潜力。SE 块的利用和时间注意力机制的引入代表了 SNNs 领域的重大进展。这些技术不仅增强了 SNNs 的表示能力,还提供了有效利用注意力机制以提升性能的见解。
在第三节中,我们将探索并进一步利用这些注意力机制,以提高 SNNs 的性能并充分释放其在复杂时间数据处理任务中的潜力。
C. 动机
基于上述分析,在 SNNs 中利用时间注意力机制在有效处理与时间相关的数据流方面取得了显著进展。
此外,在生物神经网络 [32] 和人工神经网络 (ANNs) [15] 中,重新校准卷积层内的通道特征具有相当大的提升性能的潜力。
然而,现有的基于 SNNs 的工作仅处理时间或通道维度的数据,从而限制了联合特征提取的能力。为了说明时间步骤和通道维度之间的关系,我们提供了一个可视化表示。这是通过显示输入帧以及来自初始 2-D 卷积层的几个相邻通道输出实现的,如图 2 所示。
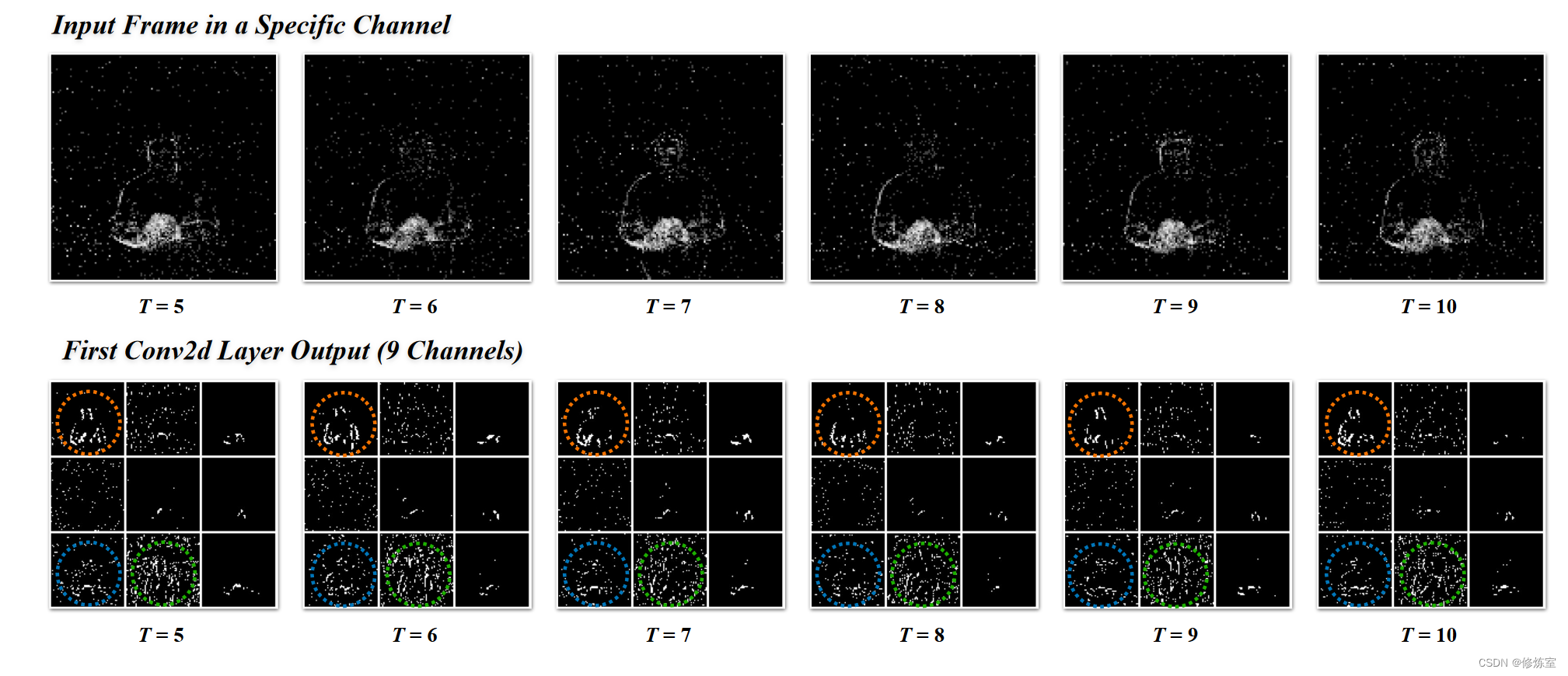
图 2. 接近时间步长与通道之间的相关性。
- 顶行是从 DVS128 手势数据集中选择的输入帧。
- 底行九格中的每个图形表示第一个 2-D 卷积层的通道输出。
很明显,在具有不同时间步长的通道中存在显着的相关性,这促使我们合并时间和通道信息。
正如圆圈所示,可以从周围的时间步和通道中区分出类似的脉冲模式。
为了充分利用这些关联信息,我们提出了 TCJA 模块,这是一种新方法,用于建模时间和通道帧关联。此外,考虑到注意力机制不可避免地增加模型参数,我们尝试采用 1-D 卷积操作,在模型性能和参数之间取得合理的平衡 。
为什么使用一维卷积就可以取得平衡?这是干了什么?
此外,现有的 SNN 注意力机制主要优先考虑分类任务,忽视了生成任务的需求。我们的目标是引入一种注意力机制,能够熟练处理分类和生成任务,从而建立一种通用的 SNNs 注意力机制。
III. 方法论
A. 泄露-积分与发放模型 (Leaky-Integrate-and-Fire Model)
为了模拟生物神经元的功能,已经提出了多种脉冲神经元模型 [33], [34],其中漏积积分与发放 (Leaky-Integrate-and-Fire, LIF) 模型 [35] 在简洁性和生物合理性之间取得了很好的平衡。LIF 神经元的膜电位动态可以描述为 [13]:
τ d V ( t ) d t = − ( V ( t ) − V r e s e t ) + I ( t ) (1) \tau \frac{dV(t)}{dt} = -(V(t) - V_{reset}) + I(t) \tag{1} τdtdV(t)=−(V(t)−Vreset)+I(t)(1)
其中
- τ \tau τ 表示时间常数
- V ( t ) V(t) V(t) 表示时间 t t t 时神经元的膜电位
- I ( t ) I(t) I(t) 表示来自突触前神经元的输入。
为了更好地进行计算,该 LIF 模型可以描述为一个显式迭代版本 [1]:
{ V n t = H n t − 1 + 1 τ ( I n t − 1 − ( H n t − 1 − V r e s e t ) ) S n t = Θ ( V n t − V t h r e s h o l d ) H n t = V n t ⋅ ( 1 − S n t ) (2) \begin{cases} V_n^t = H_n^{t-1} + \frac{1}{\tau} (I_n^{t-1} - (H_n^{t-1} - V_{reset})) \\ S_n^t = \Theta(V_n^t - V_{threshold}) \\ H_n^t = V_n^t \cdot (1 - S_n^t) \end{cases} \tag{2} ⎩
⎨
⎧Vnt=Hnt−1+τ1(Int−1−(Hnt−1−Vreset))Snt=Θ(Vnt−Vthreshold)Hnt=Vnt⋅(1−Snt)(2)
其中
- V n t V_n^t Vnt 表示第 n n n 层神经元在时间 t t t 的膜电位
- τ \tau τ 是时间常数
- S S S 是具有二进制值的脉冲张量
- I I I 表示来自上一层的输入
- Θ ( ⋅ ) Θ(·) Θ(⋅) 表示 Heaviside 阶跃函数
- H H H 表示脉冲后的复位过程。
作为一种主流的神经元模型, 基于 LIF 的脉冲神经网络 (SNN) 模型可以直接使用代理梯度方法 [24] 进行训练 ,以达到最先进的性能 [14], [30], [36]。
此外,LIF 模型非常适合常见的机器学习框架,因为它允许在空间和时间维度上进行前向和反向传播。在我们的方法中,LIF 模型的参数设置如下:
- τ = 2 \tau = 2 τ=2
- V r e s e t = 0 V_{reset} = 0 Vreset=0
- V t h r e s h o l d = 1 V_{threshold}= 1 Vthreshold=1
B. 时空联合注意力机制 (TCJA)
如前所述,我们认为当前时间步的帧与其在通道和时间维度上的相邻帧存在显著的关联。这种关联使得我们可以采用一种机制来建立这两个维度之间的联系。
最初,我们使用全连接层来建立时间和通道信息之间的关联,因为它提供了这两个维度之间最直接和显著的联系。然而,随着通道数和时间步数的增加,参数数量以 T 2 × C 2 T² × C² T2×C2 的比率迅速增长,如图 3 所示。
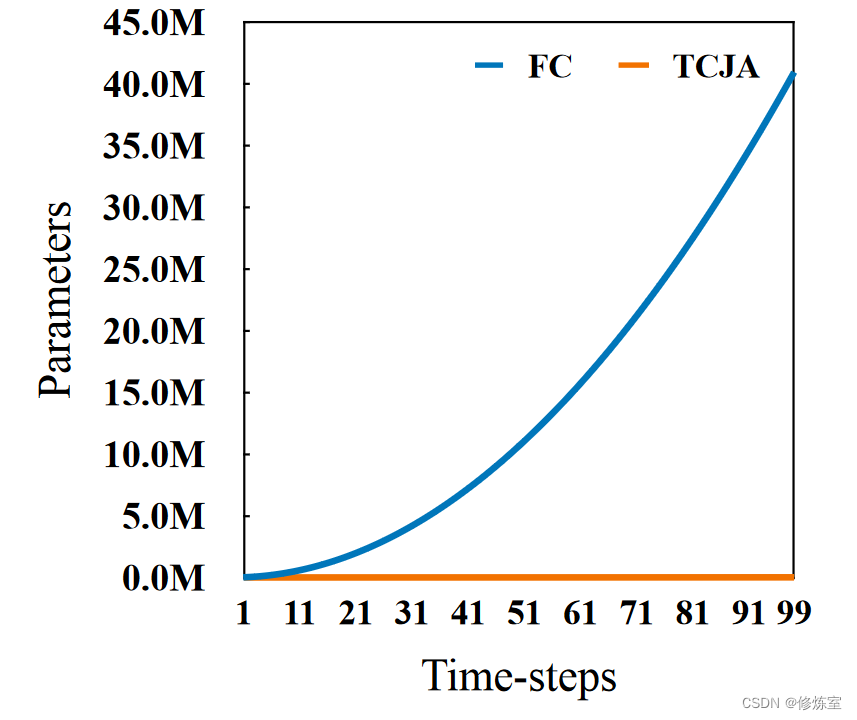
图 3. 当通道大小 C = 64 时全连接(FC)层和 TCJA 层之间的参数增长曲线。
我们随后尝试利用 2-D 卷积层来构建这种注意力机制。然而,由于固定的核大小,这种方法遇到了局限性,限制了感受野到一个有限的局部区域。在传统的卷积神经网络 (CNN) 中,通过增加层数可以扩展感受野 [37], [38]。
然而,在注意力机制的背景下,类似于卷积网络的层堆叠的可行性受到限制,从而在采用 2D 卷积时限制了感受野(the receptive field)。
出于这个原因,有必要 在增加感受野的同时减少参数数量 。
在第 IV-G5 节中,我们提供了关于感受野的详细理论分析。
为了在最小化参数使用的同时有效地结合时间和通道注意力维度,并最大化感受野,我们提出了一种新颖的注意力机制,称为时空联合注意力机制 (Temporal-Channel Joint Attention,TCJA)。这种注意力机制以其全局交叉感受野(global crossreceptive field)为特征,并能够以相对较少的参数 (具体为 T 2 + C 2 T² + C² T2+C2 ) 实现有效的结果。
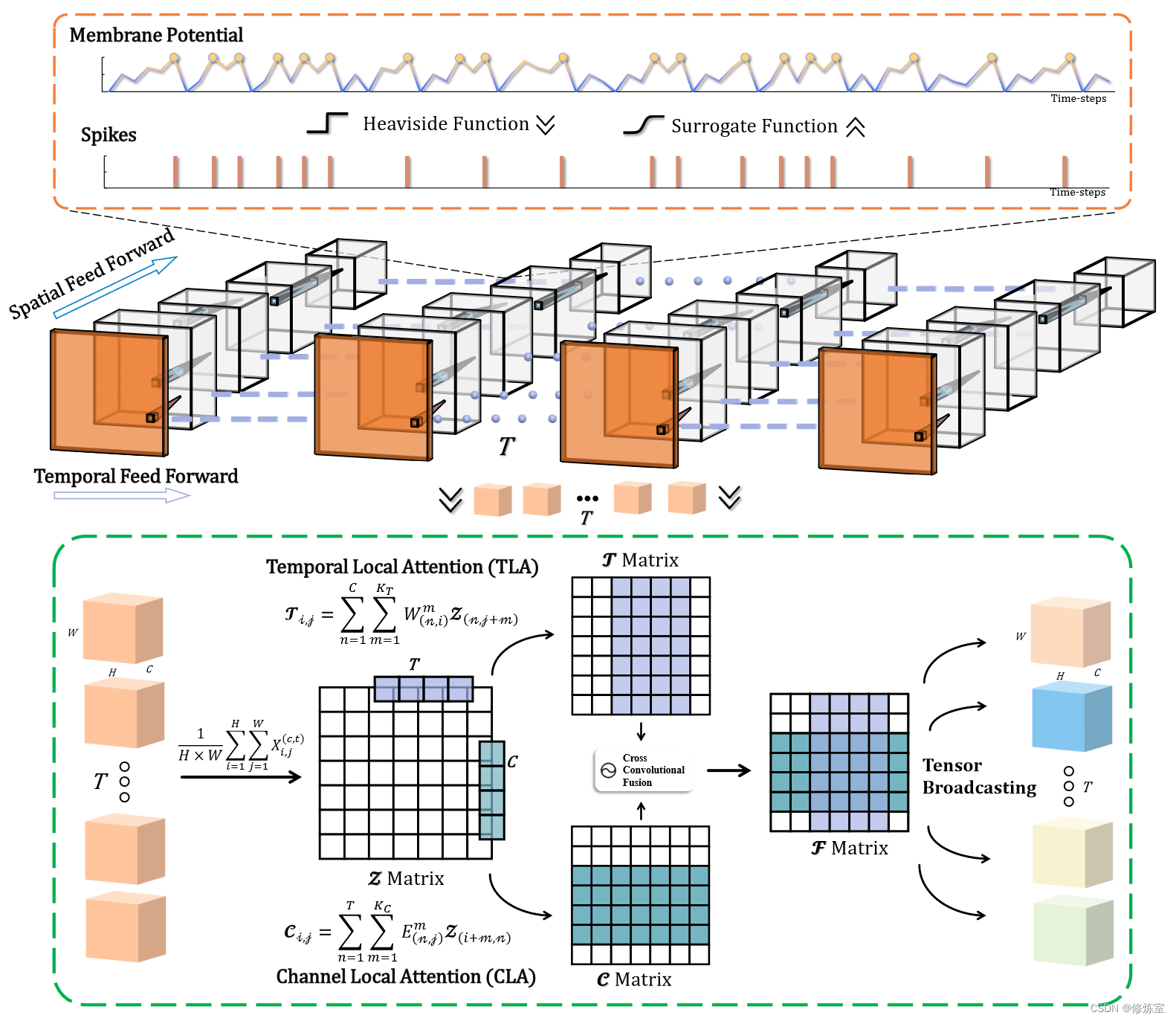
图 4. 带有 TCJA 模块的 SNN 框架。
在 SNN 中,信息以脉冲序列的形式传输,涵盖时间(temporal)和空间(spatial)维度。
- 在时间方面,脉冲神经元具有膜电位(V)和脉冲(S)的阈值前馈(如公式 2 所示),并使用代理函数进行反向传播。
- 在空间方面,数据以 ANN 的形式在层之间流动。TCJA 模块首先沿时间和空间维度压缩信息,然后应用 TLA 和 CLA 在时间和通道维度上建立关系,并通过 CCF 层将它们混合。
图 4 显示了所提出的 TCJA 的整体结构,我们将在下面详细介绍其关键组成部分。在第 III-B1 节中,我们利用输入帧上的压缩(squeezing)操作。接下来,在第 III-B2 和 III-B3 节中,我们分别介绍了时间局部注意力 (TLA) 机制和通道局部注意力 (CLA) 机制。最后,在第 III-B4 节中,我们介绍了交叉卷积融合 (CCF) 机制,以共同学习时间和通道的信息。
整个过程包括以下几个关键步骤:
- 压缩脉冲序列:首先将脉冲序列压缩成平均矩阵 Z Z Z。
- 时间局部注意力(TLA):对平均矩阵 Z Z Z 的每一行应用1-D卷积,以建立时间维度上的局部关联,得到 T T T 矩阵。
- 通道局部注意力(CLA):对平均矩阵 Z Z Z 的每一列应用1-D卷积,以建立通道维度上的局部关联,得到 C C C 矩阵。
- 交叉卷积融合(CCF):将 T T T 和 C C C 矩阵进行元素级乘法,通过 Sigmoid 函数处理得到融合信息矩阵 F F F。
- Tensor Broadcasting:利用广播机制将 F F F 矩阵扩展到与输入数据相同的维度,以便进行特征校准。
重新校准的特征用于增强网络对重要信息的关注,同时抑制不相关的信息,从而提高模型的性能。
模型的最终输出是通过累积脉冲活动来生成的:
- 计算每个神经元的发放率:通过累积脉冲活动,计算每个神经元在时间 𝑇 内的平均发放率。
- 定义预测标签:通过选择发放率最高的神经元的索引,来确定预测标签。
- 池化和投票:在最后一层添加一个 1-D 平均池化投票层,通过对每个类别的输出脉冲进行平均池化,生成一个 10 维向量。选择投票值最大的类别作为最终分类结果。
1. 通过压缩得到平均矩阵
为了有效捕捉帧之间在时间和通道维度上的关联,我们首先对输入帧流 X ∈ R T × H × W × C X ∈ R^{T × H × W × C} X∈RT×H×W×C 的空间特征图进行压缩操作,其中 C C C 表示通道大小, T T T 表示时间步。
压缩步骤计算一个平均矩阵 Z ∈ R C × T Z ∈ R^{C × T} Z∈RC×T ,平均矩阵 Z Z Z 的每个元素 Z ( c , t ) Z_{(c,t)} Z(c,t) 计算如下:
Z ( c , t ) = 1 H × W ∑ i = 1 H ∑ j = 1 W X ( c , t ) i , j (3) Z(c,t) = \frac{1}{H × W} \sum_{i=1}^{H} \sum_{j=1}^{W} X (c,t)_{i,j} \tag{3} Z(c,t)=H×W1i=1∑Hj=1∑WX(c,t)i,j(3)
其中, X ( c , t ) X^{(c,t)} X(c,t) 是 c c c 通道在时间步 t t t 的输入帧。
2. 时间局部注意力 (Temporal-wise Local Attention,TLA)
在压缩操作之后,我们提出了 TLA 机制来建立帧之间的时间关系。我们认为, 在特定时间步的帧与其相邻位置的帧有很大互动 。
因此,我们采用 1-D 卷积操作来建模时间维度上的局部对应关系,如图 4 所示。
图 4. 带有 TCJA 模块的 SNN 框架。
在 SNN 中,信息以脉冲序列的形式传输,涵盖时间和空间维度。
- 在时间方面,脉冲神经元具有膜电位(V)和脉冲(S)的阈值前馈(如公式 2 所示),并使用代理函数进行反向传播。
- 在空间方面,数据以 ANN 的形式在层之间流动。TCJA 模块首先沿时间和空间维度压缩信息,然后应用 TLA 和 CLA 在时间和通道维度上建立关系,并通过 CCF 层将它们混合。
具体来说,为了在时间层面捕捉输入帧的关联性,我们对平均矩阵 Z Z Z 的每一行执行 C C C 通道的 1-D 卷积,然后累积通过卷积平均矩阵 Z Z Z 的不同行得到的特征图。整个 TLA 过程可以描述为:
T i , j = ∑ n = 1 C ∑ m = 0 K T − 1 W ( n , i ) m Z ( n , j + m ) (4) T_{i,j} = \sum_{n=1}^{C} \sum_{m=0}^{K_T -1} W_{(n,i)}^m Z_{(n,j+m)} \tag{4} Ti,j=n=1∑Cm=0∑KT−1W(n,i)mZ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









