







 本文探讨了Transformer模型中位置编码的重要性,介绍了绝对位置编码如训练式学习和三角式函数,以及相对位置编码如Transformer的相对位置表示、自适应编码和DeBERTa的方向编码。同时讨论了大模型的外推性问题及可能的解决方法,如CNN式处理和复数式位置编码的运用。
本文探讨了Transformer模型中位置编码的重要性,介绍了绝对位置编码如训练式学习和三角式函数,以及相对位置编码如Transformer的相对位置表示、自适应编码和DeBERTa的方向编码。同时讨论了大模型的外推性问题及可能的解决方法,如CNN式处理和复数式位置编码的运用。
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
绝对位置编码
1、训练式
学习的位置编码(Learned Position Embeddings):
相比于固定的正弦余弦编码,学习的位置编码是通过训练过程自动学习的。
每个位置编码是模型的参数之一,通过梯度下降等优化算法进行优化。
这种方法在某些任务中可能优于固定的正弦余弦编码,尤其是在位置信息对于任务非常重要时。
2、三角式
正弦和余弦函数编码(Sinusoidal Position Encoding):
Transformer模型中最初采用的方法。
对于每个位置i和每个维度d,使用正弦和余弦函数交替地生成位置编码,其中波长形成一个几何级数。
公式如下:
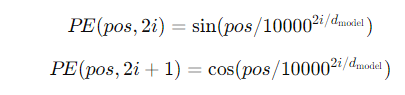
3、递归式
原则上来说,RNN模型不需要位置编码,它在结构上就自带了学习到位置信息的可能性(因为递归就意味着我们可以训练一个“数数”模型),因此,如果在输入后面先接一层RNN,然后再接Tran
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











