







UCI 人类活动识别数据集是以智能手机采集的传感器数据为基础的活动识别,创建于2012年,实验团队来自意大利热那亚大学。在2012年的论文《Human Activity Recognition on Smartphones using a Multiclass Hardware-Friendly Support Vector Machine》中,采用机器学习算法建模,提供了该数据集分类性能的baseline。在2013年的论文《A Public Domain Dataset for Human Activity Recognition Using Smartphones》中,对数据集进行了全面描述。
这些数据是从30名年龄在19岁到48岁之间的志愿者身上收集的,这些志愿者将智能手机绑在腰间,进行6项标准活动中的一项,通过开发的手机软件记录运动数据。同时记录每个执行活动的志愿者的视频,后期根据这些视频和传感器数据进行手动标记所属运动类别(类似剪辑视频中的音画同步)。执行的六项活动如下:
Walking;Walking Upstairs;Walking Downstairs;Sitting;Standing;Laying;
选择30名年龄在19-48岁之间的志愿者作为研究对象。记录的运动数据是来自智能手机(特别是三星Galaxy S II)的x、y和z加速度计数据(线性加速度)和陀螺仪数据(角速度),采样频率为 50Hz(每秒50个数据点)。每名志愿者进行两次活动序列,第一次在设备位于腰间左侧,第二次测试时,智能手机由用户自己按喜好放置。
原始数据不可用。数据集,提供了数据集的预处理版本。预处理步骤包括:
使用噪声滤波器对加速度计和陀螺仪进行预处理。
将数据分割成2.56秒(128个数据点)的固定窗口,重叠50%。
将加速度计数据分为重力(总)和人体运动分量。
我们使用手机加速度计和陀螺仪以50Hz 的采样率收集了三轴线性加速度和角速度信号。使用中值滤波器和截止频率为 20Hz的三阶低通Butter-worth滤波器对这些信号进行了预处理,以降低噪声。 该速率足以捕获人体运动,因为其能量的99%包含在15Hz以下[3]。 使用另一个巴特沃斯低通滤波器将具有重力和人体运动成分的加速度信号分离为人体加速度和重力。 假定重力仅具有低频分量,因此从实验中我们发现,对于恒定重力信号,0.3Hz是最佳转折频率。
将特征工程应用于窗口数据,并提供具有这些经过特征工程的数据。从每个窗口中提取了人类活动识别领域中常用的一些时间和频率特征。结果是一个561元素的特征向量。数据集根据受试者的数据分为训练集(70%)和测试集(30%),例如,训练21名受试者,测试9名受试者。
论文提出一个问题的框架,通过有分类标签的数据样本进行建模训练,以预测预测新对象上的运动活动。乍一看比较难理解的几个数据:
561 :特征工程之后的特征数,关于这些特征的说明,在数据集中的 features.txt和features_info.txt 作了详细说明,因为我们都是使用处理好的九轴传感器数据来建立深度学习模型,此处不再赘述。
128:数据集shape的第二个维度 128,看论文就很清楚了,在 2.56 秒的固定宽度滑动窗口中对时间信号进行采样,有 50% 的重叠。(2.56sec×50Hz = 128cycles)
7352 和 2947:数据集中将训练集和测试集中的传感器数据按照一个特征一个txt的格式各分成了9个文件,如下图所示。7352 和 2947 是测试集和训练集中每个txt文件shape的第一个维度,表示重采样之后的样本个数。一定要理解好数据集的shape!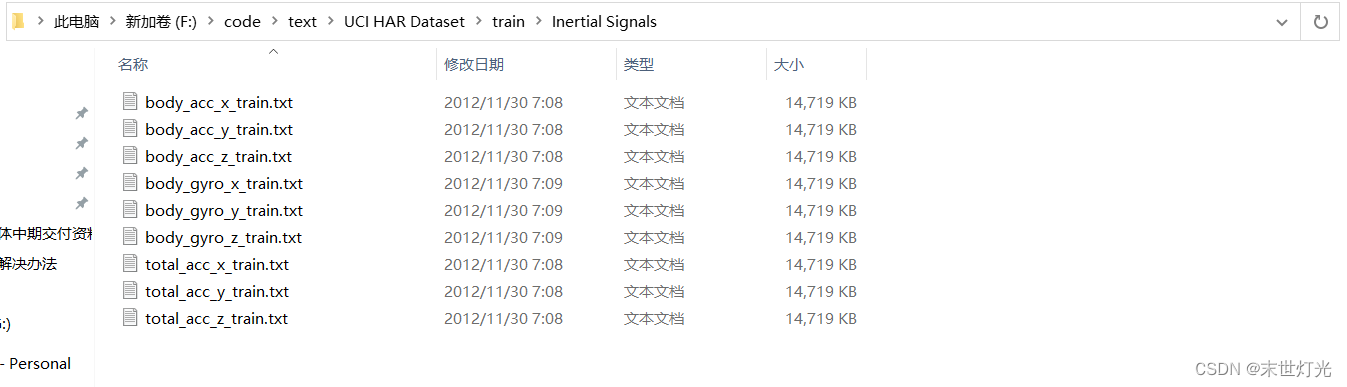
训练集和测试集文件下的文件,文件格式相同、数量相同。我们以训练集文件夹下的文件为例说明:
一级目录:
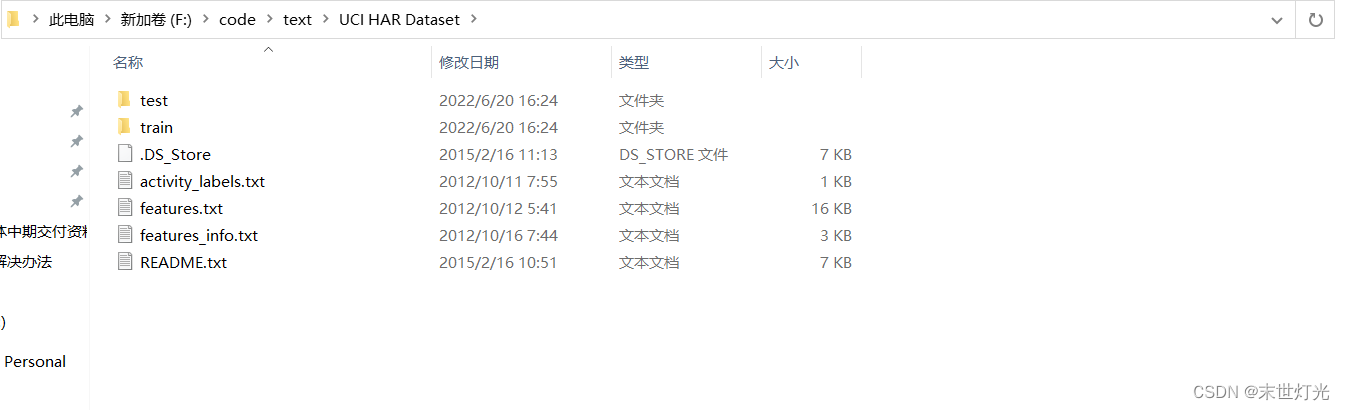
test:测试集数据;train:训练集数据;activity_labels.txt:活动的真实标签(6个);features.txt:特征工程的特征;features_info.txt:特征工程处理说明;
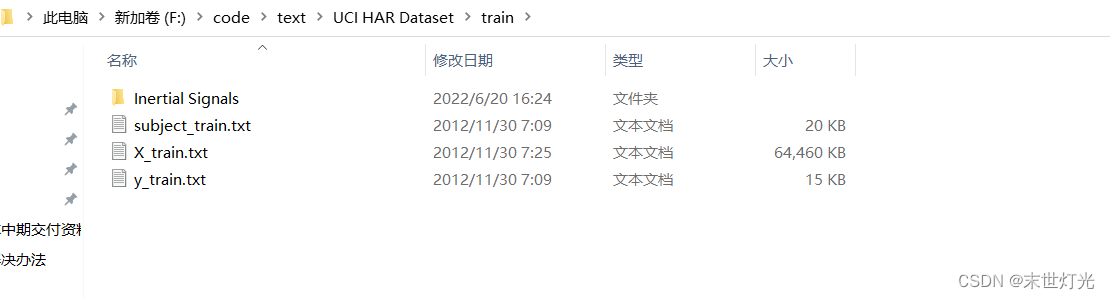
X_train.txt:未经处理的原始数据,这个不用,可以不关心;
y_train.txt:活动类别标签(数字1-6表示),shape为(7352,1);说明:注意这里的标签是从1开始表示第一类,而one-hot编码是从0开始,注意编码的时候要减去1!这个在以后的建模过程中会遇到,先说明一下。
subject train.txt:将训练集的每一个样本与志愿者编号(1-30)对应,即给每条样本记录属于哪位志愿者做标识,shape为(7352,1);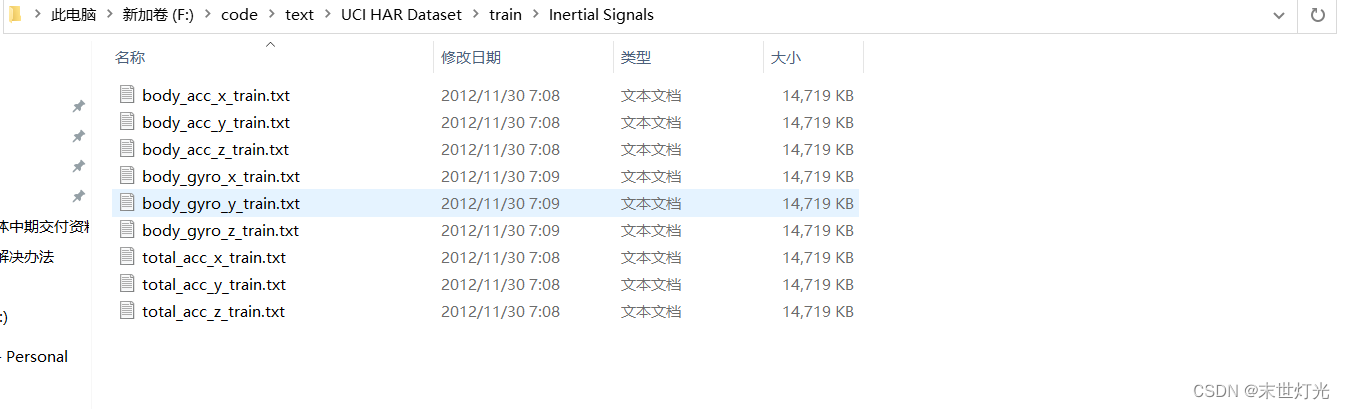
body_acc_x_train.txt、body_acc_y_train.txt、body_acc_z_train.txt:三轴的加速度数据;
body_gyro_x_train.txt、body_gyro_y_train.txt、body_gyro_z_train.txt:三轴的陀螺仪数据(角速度);
total_acc_x_train.txt、total_acc_y_train.txt、total_acc_z_train.txt:三轴的重力加速度数据;
test 文件夹下的文件结构跟 train 文件夹下是相同的,只是shape不一样。本文和以后的几篇文章中,使用的都是这两个文件夹下的数据作为训练数据和测试数据,不使用原始数据和经过特征工程的数据。
更多精彩内容请关注:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











