







 该文介绍了用于人类活动识别的两个数据集,HAR和HAPT,它们基于30名志愿者的日常活动记录,使用智能手机上的加速度计和陀螺仪数据。数据经过预处理,包括滤波和特征提取,用于多变量时间序列的分类和聚类。HAPT数据集提供了原始采样数据,而HAR数据集包含了预处理后的特征向量和标签。
该文介绍了用于人类活动识别的两个数据集,HAR和HAPT,它们基于30名志愿者的日常活动记录,使用智能手机上的加速度计和陀螺仪数据。数据经过预处理,包括滤波和特征提取,用于多变量时间序列的分类和聚类。HAPT数据集提供了原始采样数据,而HAR数据集包含了预处理后的特征向量和标签。
Human Activity Recognition database 由 30 名志愿者在携带带有嵌入式惯性传感器的腰部智能手机进行日常生活活动 (ADL) 的记录中构建而成。有两个版本的数据,第一个版本发布于2012年,更新后的版本发布于2015年。
version 1:UCI HAR Dataset
updated version:HAPT Data SET
Associated Tasks:
- Multivariate Time-Series Classification 分类
- Multivariate Time-Series Clustering 聚类
UCI HAR Dataset
基本信息
总共选取了30 名志愿者,年龄范围在19-48 岁年龄段。每个人在腰部佩戴智能手机进行六项活动(WALKING、WALKING_UPSTAIRS、WALKING_DOWNSTAIRS、SITTING、STANDING、LAYING)。同时使用嵌入式加速度计和陀螺仪采集数据,原始数据是以 50Hz 的恒定速率捕获了 3 轴线性加速度和 3 轴角速度。获得的数据集被随机分成两组,其中 70% 的志愿者(也就是21名志愿者)被选择用于生成训练数据,剩下30% 的志愿者(也就是9名志愿者)被选择用于生成测试数据。
在这个版本中,传感器的信号首选通过噪声滤波器进行预处理,然后每个样本以2.56秒这一固定的时间窗口选取数据,也就是128个采样点的数据。而传感器加速度信号具有重力和身体运动分量,使用巴特沃斯低通滤波器将其分离为身体加速度和重力加速度。假设了重力只有低频分量,因此使用了截止频率为 0.3 Hz 的滤波器。在每个时间窗口中,计算了时域和频域的特征向量,具体的计算方法可以看features_info.txt这个文件。
需要说明所有的数据都已经处理到[-1, 1]。
每一个样本都包含以下信息
- 来自加速度计的三轴总加速度和估计的身体加速度;
- 来自陀螺仪的三轴角速度;
- 时域和频域的 561 个特征向量;
- 标签;
- 志愿者标识符;
文件目录如下
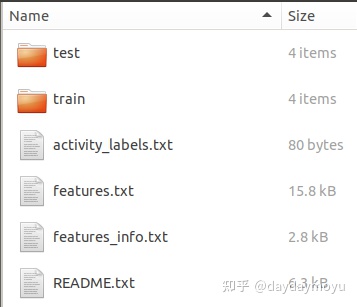
整个数据集包含以下文件
| 文件名 | 说明 |
|---|---|
| 'README.txt' | 数据集说明文件 |
| 'features_info.txt' | 每一个样本特征计算方法说明文件 |
| 'features.txt' | 计算的时域和频域特征集合,包括所有特征的名称列表,总共561种特征 |
| 'activity_labels.txt' | 六项活动对应的标签(1-6) |
| 'train/X_train.txt' | 训练集 |
| 'train/y_train.txt' | 训练标签 |
| 'train/subject_train.txt' | 一共7353行,每行标识为每个样本对应的志愿者编号,范围是1-30 |
| 'train/Inertial Signals/total_acc_x_train.txt' | Shape: 7352*128。来自智能手机加速度计 X 轴的加速度信号,以标准重力单位“g”表示。 每行是一个128维的向量 |
| 'train/Inertial Signals/total_acc_y_train.txt' | Shape: 7352*128。来自智能手机加速度计 Y 轴的加速度信号,以标准重力单位“g”表示。 每行是一个128维的向量 |
| 'train/Inertial Signals/total_acc_z_train.txt' | Shape: 7352*128。来自智能手机加速度计 Z 轴的加速度信号,以标准重力单位“g”表示。 每行是一个128维的向量 |
| 'train/Inertial Signals/body_acc_x_train.txt' | Shape: 7352*128。总加速度减去重力得到的身体加速度信号,X轴 |
| 'train/Inertial Signals/body_acc_y_train.txt' | Shape: 7352*128。总加速度减去重力得到的身体加速度信号,Y轴 |
| 'train/Inertial Signals/body_acc_z_train.txt' | Shape: 7352*128。总加速度减去重力得到的身体加速度信号,Z轴 |
| 'train/Inertial Signals/body_gyro_x_train.txt' | Shape: 7352*128。陀螺仪测量的每个采样窗口样本的X轴的角速度矢量, 单位为单位为弧度/秒 |
| 'train/Inertial Signals/body_gyro_y_train.txt' | Shape: 7352*128。陀螺仪测量的每个采样窗口样本的Y轴的角速度矢量, 单位为单位为弧度/秒 |
| 'train/Inertial Signals/body_gyro_z_train.txt' | Shape: 7352*128。陀螺仪测量的每个采样窗口样本的Z轴的角速度矢量, 单位为单位为弧度/秒 |
| 'test/*' | 与训练集的说明相同 |
读取数据、特征向量、标签
- 读取训练集中X轴的总加速度数据,其中每一行代表一个采样窗口的数据
# 读取X轴的总加速度数据, data_dir是HAR数据存放的路径
train_tot_acc_x = np.loadtxt(f'{data_dir}/train/Inertial Signals/total_acc_x_train.txt')
print(train_tot_acc_x.shape) # 打印数据大小
# 输出: (7352, 128)- 读取训练集中X轴的身体加速度数据,其中每一行代表一个采样窗口的数据
# 读取X轴的身体加速度数据, data_dir是HAR数据存放的路径
train_body_acc_x = np.loadtxt(f'{data_dir}/train/Inertial Signals/body_acc_x_train.txt')
print(train_body_acc_x.shape) # 打印数据大小
# 输出: (7352, 128)- 读取训练集中X轴的陀螺仪数据,其中每一行代表一个采样窗口的数据
# 读取X轴的陀螺仪数据, data_dir是HAR数据存放的路径
train_gyro_x = np.loadtxt(f'{data_dir}/train/Inertial Signals/body_gyro_x_train.txt')
print(train_gyro_x.shape) # 打印数据大小
# 输出: (7352, 128)- 读取每个采样窗口对应的特征向量,其中每一行代表一个采样窗口数据的所有特征
train_features = np.loadtxt(f'{data_dir}/train/X_train.txt')
print(train_features.shape) # 打印数据大小
# 输出: (7352, 561)- 读取每个采样窗口的标签
train_y = np.loadtxt(f'{data_dir}/train/y_train.txt')
print(train_y.shape) # 打印数据大小
# 输出: (7352,)HAPT Data SET
在更新的数据集中,作者提供了原始的采样数据,而不是经过处理后的数据。
新的数据集中,删除了 train和test目录下的Inertial Signals/* 这个文件夹,提供了原始数据的文件夹RawData,文件目录如下所示
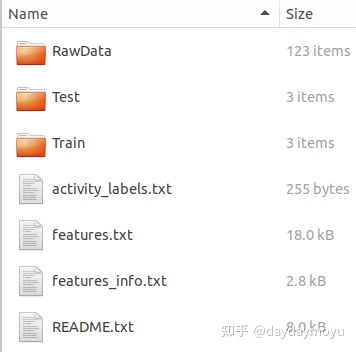
RawData目录下数据说明如下
- RawData/acc_exp[XX]_user[YY].txt:用户YY生成的实验编号 为XX 的原始三轴加速度信号 。每一行是一个以 50Hz 频率捕获的三轴加速度样本。
# Example, 读取编号为01用户生成编号为01的原始三轴加速度数据
data = np.loadtxt(f'{data_dir}/RawData/acc_exp01_user01.txt')
print(data.shape)
# 输出:(20598, 3)- RawData/gyro_exp[XX]_user[YY].txt:用户YY生成的实验编号 为XX 的原始陀螺仪信号 。每一行是一个以 50Hz 频率捕获的三轴陀螺仪样本。
# Example, 读取编号为01用户生成编号为01的原始三轴陀螺仪数据
data = np.loadtxt(f'{data_dir}/RawData/gyro_exp01_user01.txt')
print(data.shape)
# 输出:(20598, 3)- RawData/labels.txt:标签文件,每一行5个数据,分别表示experiment number ID,user number ID,activity number ID,Label start point,Label end point。
data = np.loadtxt(f'{data_dir}/RawData/labels.txt')
print(data.shape)
# 输出:(1214, 5)
print(data[0]) # 打印第一个样本标签信息
# 输出:[1.000e+00 1.000e+00 5.000e+00 2.500e+02 1.232e+03]
# experiment number ID:1
# user number ID:1
# activity number ID:5
# Label start point:250
# Label end point:1232使用HAR、HAPT进行实验的论文(不定期更新)
- Time-Series Representation Learning via Temporal and Contextual Contrasting. IJCAI2021.
- A new attention mechanism to classify multivariate time series. IJCAI2020.
- Unsupervised Representation Learning for Time Series with Temporal Neighborhood Coding. ICLR2021
- ......

















 8901
8901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









