






3D Scene Geometry-Aware Constraint for Camera Localization with Deep Learning
基于深度学习的3D几何感知约束的相机定位
这是一篇通过深度值和位姿监督posenet,并把两者融合到连续帧重投影误差LOSS中
摘要
摄像机定位是自主驾驶车辆和移动机器人实现全局定位的基础和关键环节,可以实现环境感知、路径规划和运动控制。近年来,基于卷积神经网络的端到端方法得到了广泛的研究,以实现甚至超过基于三维几何的传统方法。在这项工作中,我们提出了一个紧凑的网络绝对相机姿态回归。在这些传统方法的启发下,通过充分利用包括运动、深度和图像内容在内的所有可用信息,提出了一种三维场景几何感知约束。通过定义像素级的光度损失和图像级的结构相似性损失,我们将此约束作为正则化项添加到我们提出的网络中。为了对我们的方法进行基准测试,使用我们提出的方法和技术状态测试了不同的挑战场景,包括室内和室外环境。实验结果表明,该方法在预测精度和收敛效率上都有显著提高。
贡献
1.提出了一种深度神经网络结构,可以直接从输入图像中估计出摄像机的绝对姿态。2.通过利用深度传感器信息,应用额外的3D场景几何感知约束来提高预测精度。如前所述,稀疏的深度信息将足以获得显著的定位精度提高。这意味着我们的方法可以适用于任何类型的深度传感器(稀疏或密集)。3.对室内和室外数据集进行了广泛的实验评估,以将我们的方法与最先进的方法进行比较。同时,我们证明了所提出的额外的三维场景几何感知约束可以很容易地添加到其他网络中,从而提高性能。
方法
作者利用连续帧的之间的pose和深度,能够从一张图像重建出另一张图像,这是自监督深度估计的基本思想,作者利用这种思路,在已知深度和绝对位姿条件下设计连续帧重建以达到训练pose网络的目的。
如图在pose训练过程中连续两个图像
I
t
I_t
It和
I
t
−
1
I_{t-1}
It−1和相应的深度图以及真实pose作为监督,pose网络通过建立欧几里德距离约束作为每次预测的损失项,学习两幅图像的权重并预测绝对姿态。对于运动相机,两个连续的图像通常是重叠的,它们的绝对姿态可以被三维场景几何约束。在本文中,这种三维场景几何感知约束被描述为光度误差和SSIM误差。与文献〔24〕中只采用相对变换作为几何约束来学习绝对姿态的方法相比,本文采用三维场景几何感知约束作为像素级的损失,利用更多的信息(包括相对变换、三维信息和像素强度)来学习全局的摄像机定位。
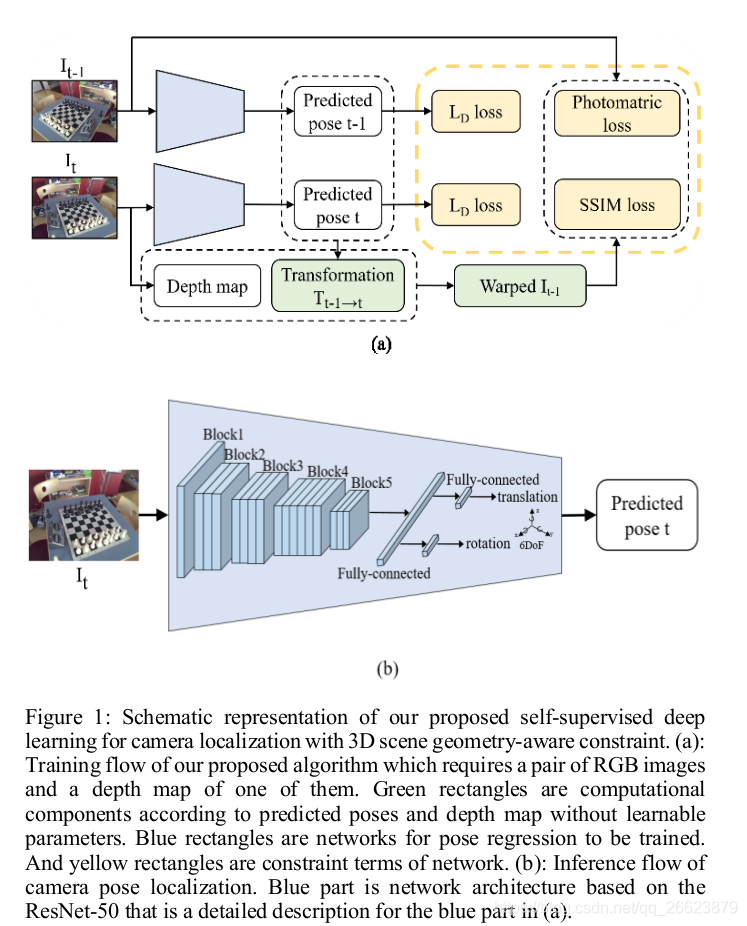 ### Warping computation
### Warping computation
两帧之间的像素间的几何投影

深度的选择
作者文中提到不需要密集的深度信息。因此,我们可以从深度传感器(结构光相机、飞行时间相机、立体传感器和三维激光雷达)或立体式深度计算算法中提取它,例如两个重叠图像中匹配点的三角剖分方法,并知道它们之间的变换。但是,要确保在我们的模型中不引入额外的深度误差。
Loss
1.欧式距离

2.重投影误差
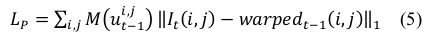
3.
结构相似性约束这种约束试图从场景中提取结构信息,就像人类视觉系统一样。两个图像I_x和I_y的相似性表示为:
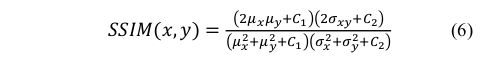
结果
1.位姿估计结果
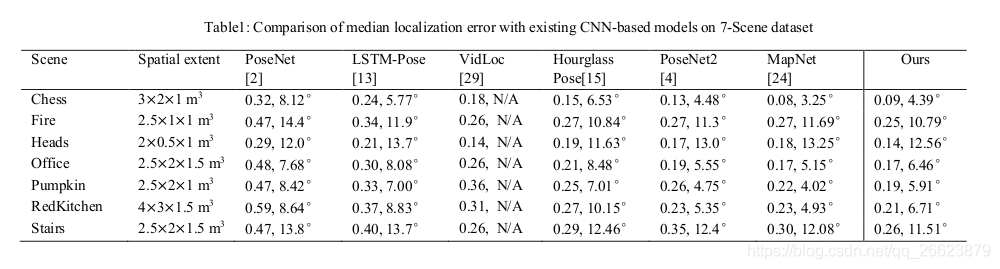 2.Micsoft scense 位姿估计结果
2.Micsoft scense 位姿估计结果
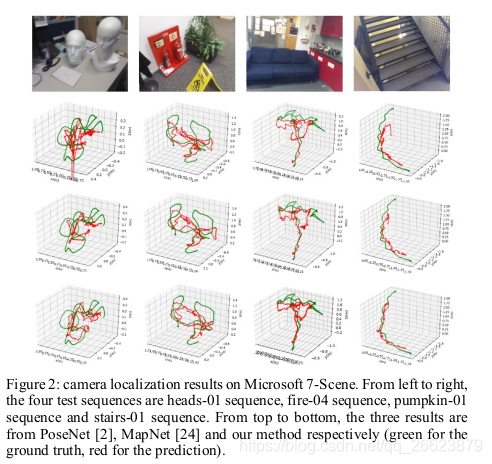 3.
3.














 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









