







深度学习自然语言处理 原创
作者:cola
meme是一种现代的交流形式,其模板具有基本的语义,任何人都可以在社交媒体上发布它。由于机器学习系统没有足够的上下文来理解meme,因为它比图像和文本有更丰富的内容,所以机器学习系统很难处理meme。为了让这类系统理解meme,这篇文章发布了一个相关知识库,称之为Know Your Meme Knowledge Base(KYMKB),这个知识库由54,000多张图片组成。KYMKB包括流行的meme模板、每个模板的示例以及关于模板的详细信息。
论文:
A Template Is All You Meme地址:
https://arxiv.org/pdf/2311.06649.pdf
介绍
模因是一种现代的交流形式,能够以简洁的方式传达复杂的信息。这么说可能不太好理解,举个例子:像平时我们用的表情包、用来传递信息的网络热梗、甚至对于一个东西的定义这些都是meme的一种表现形式。在这篇文章中,作者通过图片来体现meme的价值。
meme还可以定义为文化传播的单位,或者模仿和复制的单位。但是,所有的meme都具有指一群人共享的文化时刻的特征。尽管它们的内在基础是互联网文化,但它们表现出典型的群体交流的社会语言学特征。因此,对于那些不属于内部群体的人来说,meme的含义可能会变得模糊,这可能会使许多人难以理解,更不用说机器了。
meme模板是常见的模式是文本和图像,它们可以以不同的方式组合,并且每个都有自己独特的含义,其特定语义可以由发布的人定制。模板及其消息可以被图像引用,但不能与该图像直接相关。如果不熟悉所讨论的模板,可能无法理解模因的含义。例如,在图1中,左边的第一个和第二个图这两个模板传达了这样一种想法:男人的主体由于自己的世界观或有限的知识而误解了蝴蝶的客体。换言之,第一张图表示NLP社区认为它可以使用ChatGPT来生成数据;而第二张图表明ChatGPT可以利用NLP社区来获取数据;第三张就是宝可梦的图片。为了理解meme,我们不仅要识别模因中的实体,还要识别模因使用的模板(如果有的话)。
模板meme(模因)指的是一个模因模板,它通常是可重复使用的材料(文本、图像、音频等),以创建一个仍然基于模因模板语义的新实例。非模板模因可以是(视觉上的)双关语、笑话或强调,不涉及模因模板,不了解特定模因模板甚至模因的人也能理解。
Know Your Meme (KYM),互联网模因数据库,是一个与模因相关的有价值的信息资源,特别是模板模因。即使熟悉模因的人也可能不知道特定模板的基本语义。KYM中的模因条目提供了基本模板和有关它的附加信息,如它的含义、来源、各种例子等。通过查看不熟悉的模板条目并查看其使用示例,用户可以学习如何解释和使用模板本身来为其特定的通信需求创建新的实例。
因此,本文创建并发布KYMKD,一个通用数据库,其中包含从KYM中抓取的Meme模板的图像和信息。作者假设,关于模板模因和KYMKB的知识提供了之前工作中缺失的上下文,可以帮助理解模因。为了证明KYMKB的价值和模板模因产生信号的显著性,他们开发了一种模因分类方法——模板标签计数器(Template-Label Counter, TLC)。TLC是一个基于主体的分类器,它根据模因向量表示之间的距离为模因分配模板。如果一个新模因是该模板的一个实例,我们就可以将其最频繁的标签分配给它。作者发现TLC比与微调预训练模型相比具有竞争力,同时计算效率也高得多。
KYMKB
KYM(Know Your Meme)可以被认为是模因的维基百科。用户创建带有模因模板和关于模因的文档信息的条目,例如,它的起源和含义,并添加它的使用示例(参见图2的示例条目)。创建条目后,社区会对其进行审查并最终批准。这个条目可以随着meme用法的演变而更新。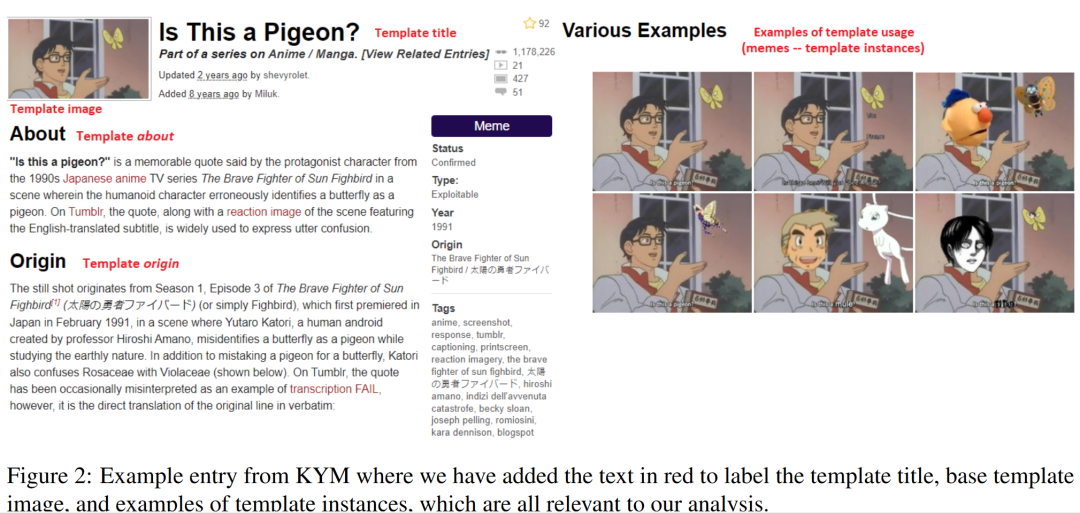 模板实例对于理解模因很重要。在图2中,我们看到可以通过覆盖文本和图像来更改模板,以针对特定语义进行调整。现有的方法依赖OCR来提取文本或命名实体,但这在许多情况下不起作用。为了解决这个问题,我们创建了KYMKB,一个模因模板、示例和有关模因使用的详细信息的集合。为了保证meme条目的质量,我们从KYM抓取了经过社区确认的条目,删除了5,220个基础模板和49,531个示例,总共有54,751张图片。图3显示了我们知识库的结构,其中所有文本数据(如about部分)都链接到模板,并与本地位置一起记录在JSON文件中。然后,该模板位于父目录中,该子目录包含示例。平均而言,每个模板有9.49个示例。
模板实例对于理解模因很重要。在图2中,我们看到可以通过覆盖文本和图像来更改模板,以针对特定语义进行调整。现有的方法依赖OCR来提取文本或命名实体,但这在许多情况下不起作用。为了解决这个问题,我们创建了KYMKB,一个模因模板、示例和有关模因使用的详细信息的集合。为了保证meme条目的质量,我们从KYM抓取了经过社区确认的条目,删除了5,220个基础模板和49,531个示例,总共有54,751张图片。图3显示了我们知识库的结构,其中所有文本数据(如about部分)都链接到模板,并与本地位置一起记录在JSON文件中。然后,该模板位于父目录中,该子目录包含示例。平均而言,每个模板有9.49个示例。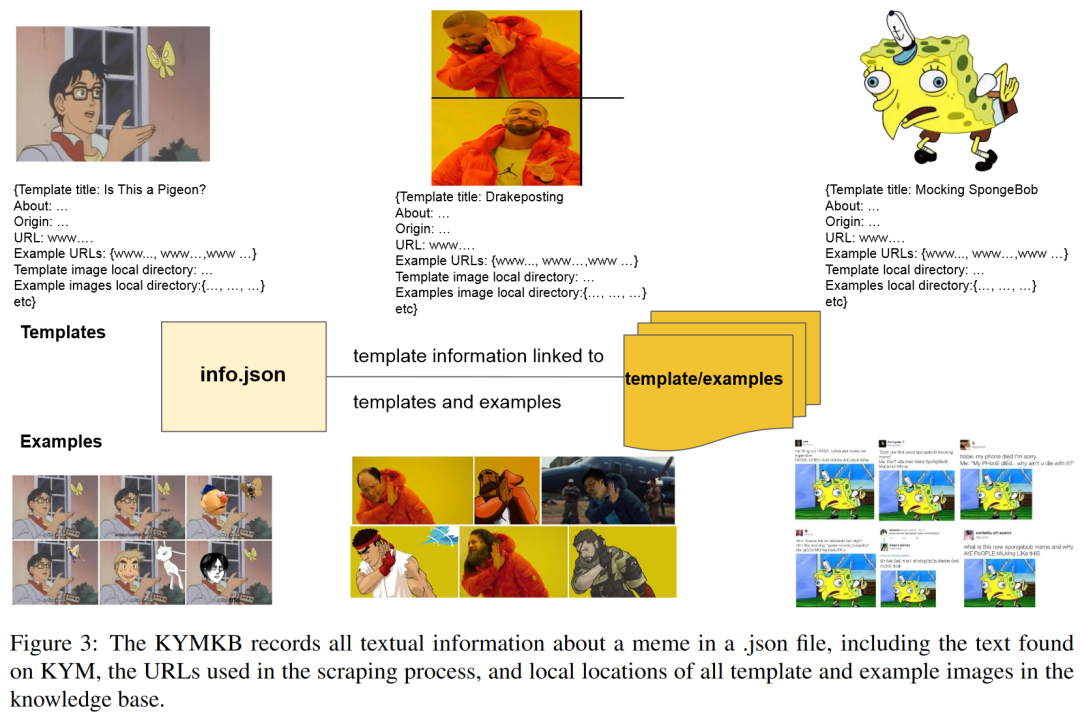
模板模因
本文假设基于检索的方法应该允许我们将基模板与真实环境中的模因相匹配,允许我们通过考虑与基模板相连接的文本,如KYMKB中的about部分,来访问有关新模因的信息。为了证实这一点,我们对知识库中编码的模板图像进行了最近邻查找。然后,在五个现有的模因分类任务上查询它(见表1)。具体来说,我们查询了500个最近邻,并手动检查相似性。 我们还研究了FigMemes,使用CLIP作为编码器,因为它是视觉和语言学习问题和模因的常用预训练模型。图4显示了我们的结果示例。FigMemes数据集中的模因可能是基模板或扭曲或裁剪的版本,如图中的前两列;也有可能是调整的模板实例,如第3列。在FigMemes中,与这个模板最接近的例子是海绵宝宝与愤怒的佩佩的融合。使用相似性度量和多个邻居查询KYMKB,可以以about部分的形式检索到足够的信息,将此模因解释为另类愤怒地表达嘲笑,与创建FigMemes的域一致。
我们还研究了FigMemes,使用CLIP作为编码器,因为它是视觉和语言学习问题和模因的常用预训练模型。图4显示了我们的结果示例。FigMemes数据集中的模因可能是基模板或扭曲或裁剪的版本,如图中的前两列;也有可能是调整的模板实例,如第3列。在FigMemes中,与这个模板最接近的例子是海绵宝宝与愤怒的佩佩的融合。使用相似性度量和多个邻居查询KYMKB,可以以about部分的形式检索到足够的信息,将此模因解释为另类愤怒地表达嘲笑,与创建FigMemes的域一致。
模板标签计数器
假设由于KYM由流行的模因模板组成,模因数据集只不过是我们在KYMKB中收集的模板的定制实例。因此,我们能够将一个新的模因与我们的模板进行比较,并选择最相似的模板,以获得之前方法中缺失的模因特定上下文。为了检验我们的假设,我们认为数据集中一个模因的标签可以是其语义的表示,例如有害vs中立。通过将KYMKB模板与数据集训练的模因匹配,我们可以将该标签分配给该模板的任何其他实例,即该数据集测试分割中的一个新的模因。
注入模因知识
TLC的第一步是编码所有的模因模板和可选的示例。我们再次选择通过CLIP编码和最近邻索引作为相似性度量。我们可以将其形式化为一个排名任务,我们首先设置对模板的引用: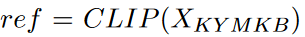 如图5的(1)所示:
如图5的(1)所示: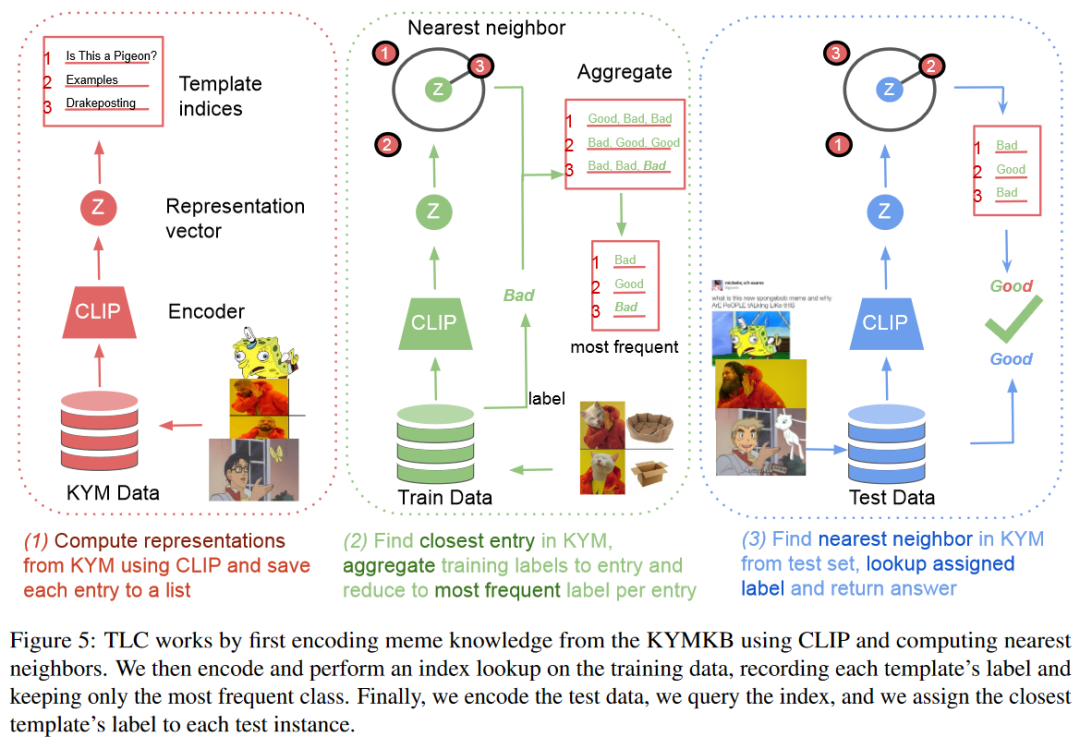
注入数据集知识
下一步是学习数据集的特性,例如标记方案。我们对训练数据进行编码,,并查询近邻索引,选择最近的模板并记录每个训练实例的标签。然后TLC将每个模板索引归约为该模板最频繁的标签,如下所示: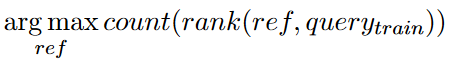 其中rank函数根据它们到查询向量的欧氏距离对KYMKB中的条目进行升序排序(参见图5中的(2))。
其中rank函数根据它们到查询向量的欧氏距离对KYMKB中的条目进行升序排序(参见图5中的(2))。
测试模因和数据集
最后一步就是先用CLIP编码测试数据,,再使用最近邻查找法。然后我们将从训练数据中获得的索引/模板的最频繁的标签分配给测试实例。如果我们发现在训练过程中没有看到模板,我们会退回到训练数据中最频繁的标签(参见图5中的(3))。
超参数
当使用TLC时,我们可以选择忽略模因本身,将模板的about部分与新模因的OCR文本匹配。或者,我们可以选择是考虑基模板,还是考虑编码模因知识的模板和示例。我们也可以考虑多个邻居,并选择其中最常见的模板或标签。不同的编码器,例如不同版本的CLIP,也可以使用。我们还可以使用多种模态,将来自模板/示例和OCR文本的about部分分别与模板和新模因嵌入相结合。我们尝试连接两种模态的片段嵌入,通过Hadamard乘积融合两者,可以对两个向量进行归一化,然后使用两种模态的平均值作为最终输入向量。
实验
我们将不同版本的TLC与五个模因任务报告的结果进行了对比,包括FigMemes、MultiOff、MEMEX和Memotion 3 Task A/B。以Memotion 3为例,用于测试划分的1500个模因标签是不公开的,因此我们在分析中使用了训练集和验证集。以MEMEX为例,在撰写本文时,200个模因的验证分割也未公开。因此,我们只考虑训练集和测试集的划分。
实验结果
TLC优于微调
我们比较了嵌入文本、编码模板、模板和示例。进一步提供了以前工作的最佳结果,其中预训练模型对OCR文本、模因本身或两者的多模态表示进行了微调。我们注意到TLC优于多数类分类器。以Memotion 3 (B)为例,多数分类器与多模态微调模型相比具有竞争力。如表2所示: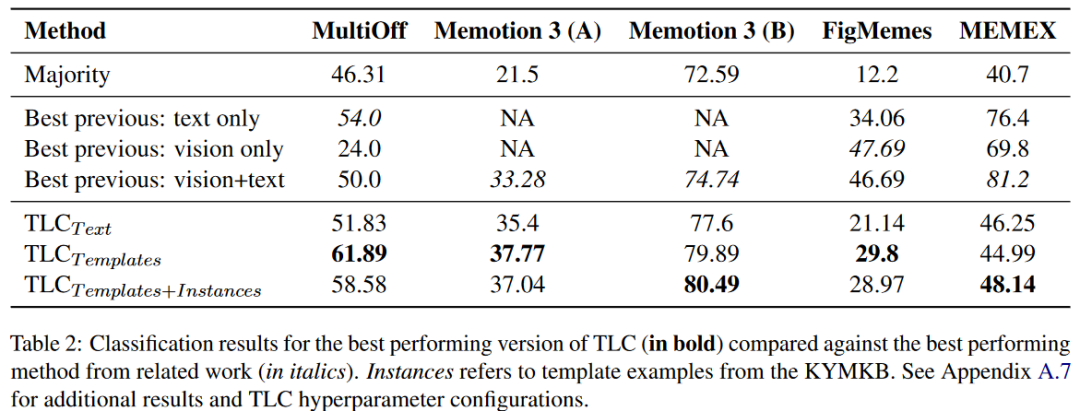
More,more!
随着考虑更多模式,TLC的性能不断提高。从一个新模因中编码模板的about部分和OCR文本本身就很强大,当我们添加模板和模因图像时,性能提高了,MultiOff的性能提高了10个百分点以上。将图像和文本连接起来往往是最强的TLC配置。我们将这解释为对我们的假设的支持,即模因的基本语义在about部分中得到了解释,也被模板捕获。通过从OCR中使用额外的模因特定信息,我们可以自然地获得准确含义的更好表示。
I Love Democracy!
只有在同时考虑模板和示例的情况下,多邻居投票才能提高性能。我们在KYMKB中搜索了1到5个邻居来尝试估计一个新模因的模板,我们找到了3到5个邻居,从而为TLCT模板+实例产生最强的分类。这与我们的探索性数据分析是一致的,在KYMKB中查询多个模板为我们提供了足够的信息来解释一个融合了两个模板的新模因。当我们只考虑模板或只考虑文本时,自然会导致多个不同模板的实例,因此会有噪声标签。
Examples? Well yes, but actually no
基本模板足以编码模因知识,并且比嵌入示例更有效。在MultiOff的情况下,当我们只考虑模板而忽略示例时,我们看到得分提高了两个以上。在大多数情况下,TLCT模板值与TLCT模板+实例值的差值不超过1个点。这创建了一个以模因知识为基础的强大模型,只编码了现有图像的十分之一,支持了模因数据集可以是KYMKB中收集的模板实例的说法。
Counting templates: GG EZ
在Memotion 3和MultiOff的情况下,该方法比昂贵的大型模型训练更强大。通过利用模板模因的力量,我们甚至不用尝试就可以获得多语言。对于FigMemes,TLC与原文工作报告中的文本基线和视觉基线相比具有竞争力或更强。不同方法和模态的性能差异很大,强调了任务的难度。
TLC? Sounds good, doesn’t work
TLC在某些任务上表现不佳的原因有很多。可能是由于许多模因数据集是通过爬虫创建的,并没有进行整理以删除非模因,包括模因和图像。TLC假设新的模因属于一个模板,但我们的预测对一张图片(它不是模因)没有意义。MEMEX问了一个只有MEMEX能回答的问题。MEMEX不是把模因和标签配对,而是用一个模因和一个解释配对创建一个新任务,其中标签是解释是否与模因相关。理解模因需要额外的背景,但该方法不能应用于未包含在数据集中的模因,因为它依赖于有一个解释。
Wait it’s more complex? Always has been
TLC的优势和简单性指出了模因数据集创建过程中的一个问题。通过仅为给定模板提供最常见的标签,我们假设模板只能传递固定的消息;例如,在分类任务中,这意味着模板只能是有害的或无害的。这与我们的论点一致,即模板将模因基于基本语义,但与可以调整模因含义的现实相矛盾。通过故意过度拟合大多数类别,TLC是与花销更大的方法相比具有竞争力。这表明了模因模板的力量,但从设计上看,TLC无法解释新颖的模板,而是利用了模因数据集的创建方式。
SOTA meme classifier? I missed the part where that’s my problem
这项工作的目标不是创建一个最先进的模因分类器,而是提供一个资源,以进一步了解模因,并将缺失的模因模板添加到知识库中。TLC在某种意义上,通过利用泄露的信息进行欺骗;它还没有学会解释模因,而是正在利用被忽视的模板信号。
模因里面有什么?
模因不仅仅是图像,有时也有文本。以Leeroy Jenkins为例,这个模板引用了YouTube上一个流行的视频,在这个视频中,《魔兽世界》中的一名玩家在大喊自己的名字Leeroy Jenkins时做出了一个鲁莽的决定,这将导致一组玩家在与怪物的战斗中失败。这个模板的一个实例不仅仅是一些图像,而是大喊Leeroy Jenkins或使用原始模板中的音频,当执行鲁莽的行为时,可能会产生负面后果。
尽管这个模板起源于2005年,但近20年后它仍然被引用,这表明模板的寿命很长。这个视频是模因的汇编,但不是由静态图像(有时是文本)组成,而是由音频和视频组成。这段视频已经有超过660万的观看次数。为了使我们的工作易于理解,我们遵循了AI社区所聚合的模因的概念。例如,TLC依赖于模因是图像的概念来进行分类,但我们的方法旨在证明模板的有用性和知识库的缺陷。模板模因只是理解这种交流形式的冰山一角,KYMKB提供了丰富的知识,我们可以利用它来创建能够解释模因的系统。
总结
主要贡献:
发布了KYMKB,一个拥有54,000张模因相关图像及其信息的知识库
提出了一种高效的基于多数样本的分类器TLC,与更昂贵的方法具有竞争性或更强
对TLC和KYMKB进行实验和分析,以证明它们的潜力。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









