







MetaPortrait
论文
MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
https://browse.arxiv.org/pdf/2212.08062.pdf
模型结构
整体流程
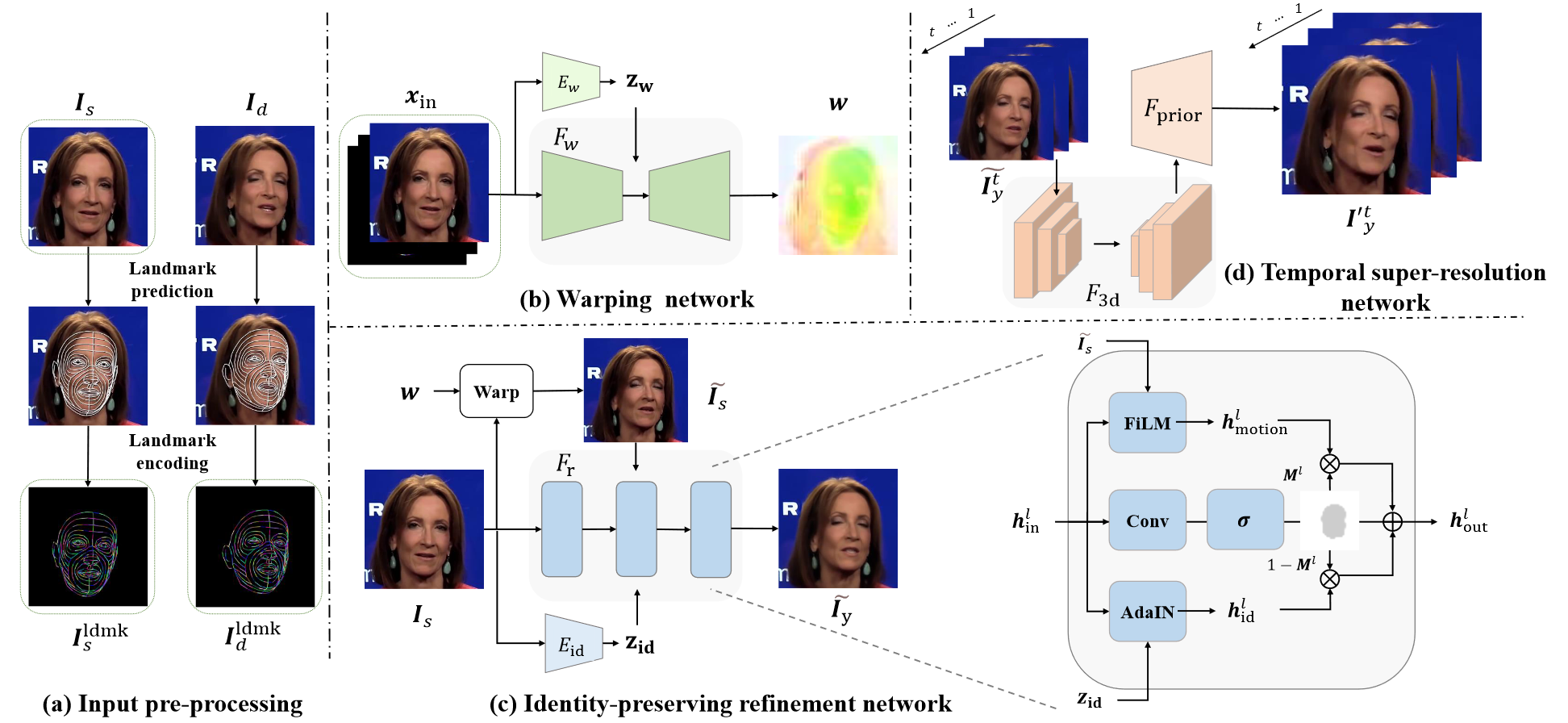
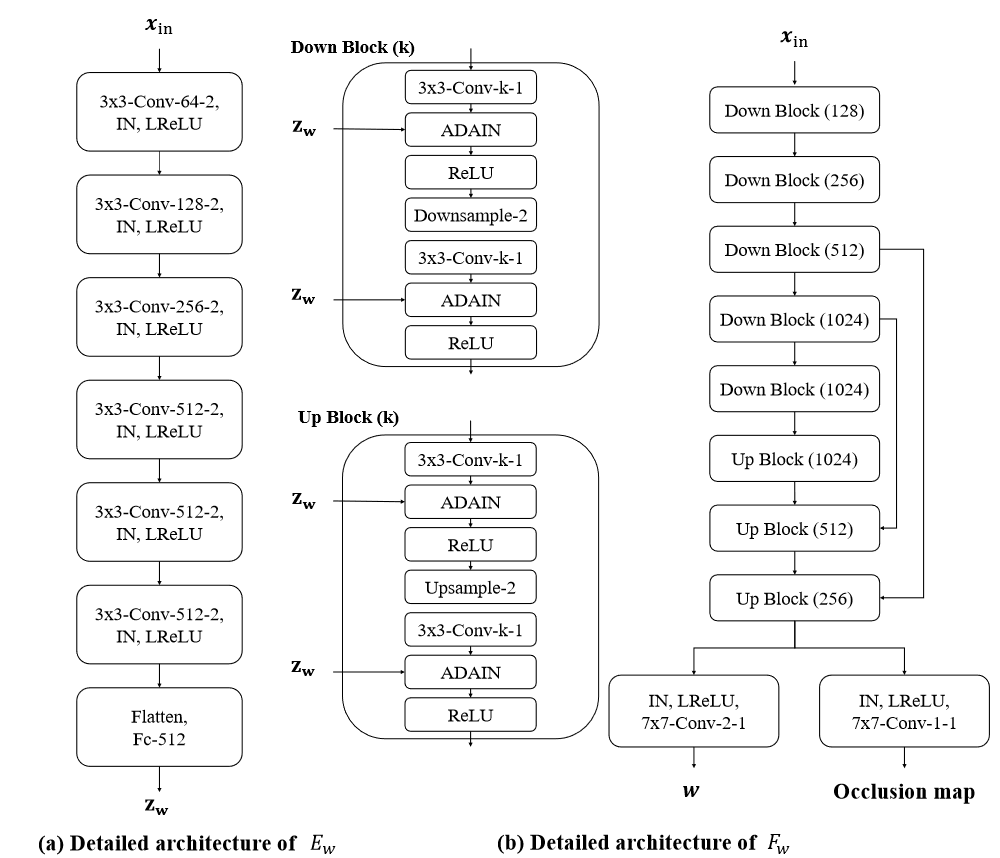
(a)𝐼𝑠表示输入的原始图像,𝐼𝑑表示被模仿的图像(视频中的某一帧),𝐼𝑠𝑙𝑑𝑚𝑘和𝐼𝑑𝑙𝑑𝑚𝑘分别表示两者的dense landmark;(b)𝑥𝑖𝑛=𝐶𝑜𝑛𝑐𝑎𝑡(𝐼𝑠,𝐼𝑠𝑙𝑑𝑚𝑘,𝐼𝑑𝑙𝑑𝑚𝑘)也就是在阶段(a)中的输入𝐼𝑠及两个输出,𝐸𝑤表示CNN Encoder;(c)𝐸𝑖𝑑为已经预训练的人脸识别模型,FILM表示Feature-wise Linear Modulate,AdaIN表示一种风格迁移方法。
warping network
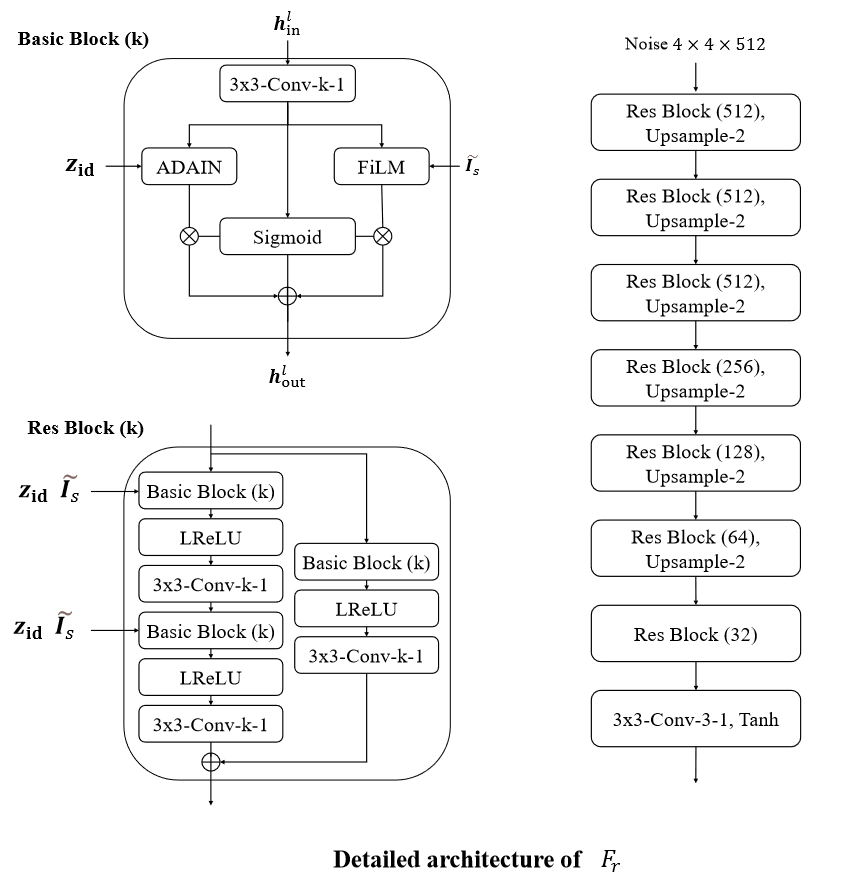
𝐹𝑟
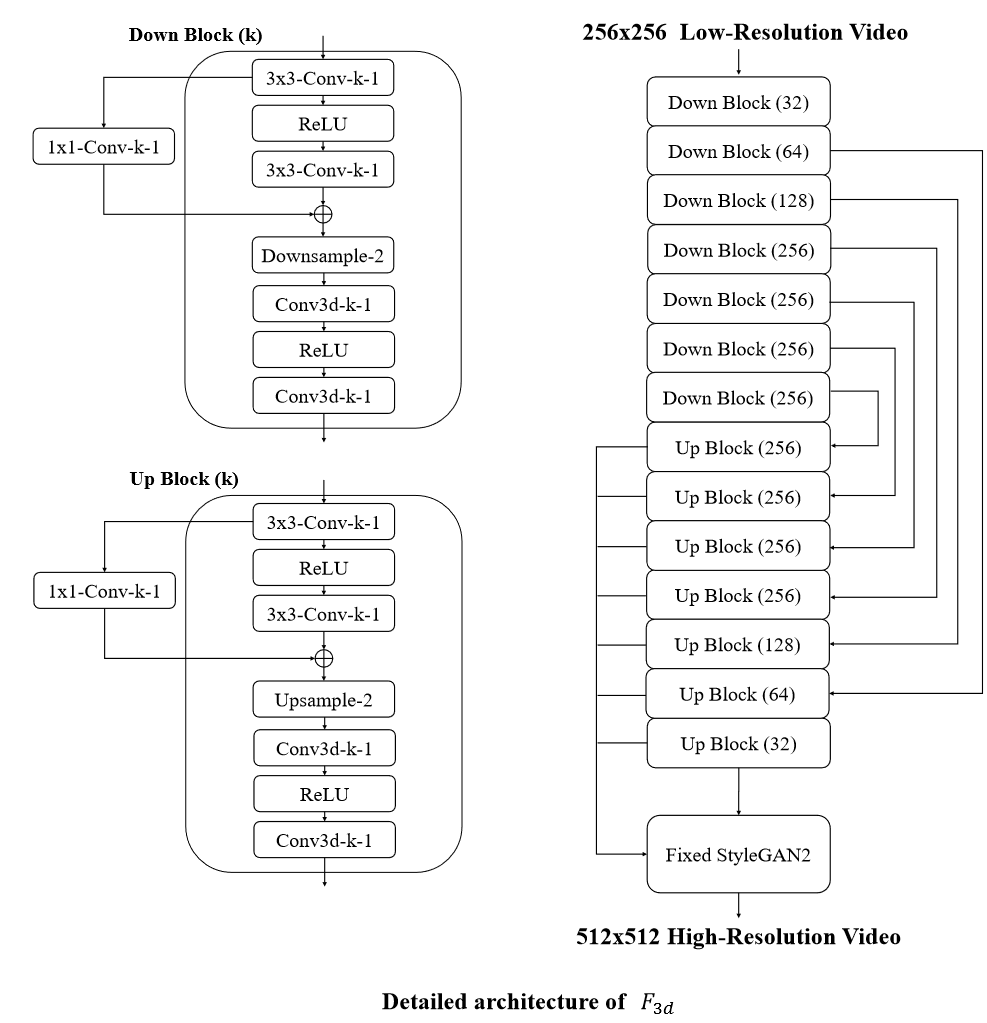
𝐹3𝑑
算法原理
用途:该算法可以用来生成单镜头说话的头部视频
原理:
-
dense landmarks获取几何感知的变形场估计,自适应融合源身份以更好地保持肖像关键特征
-
meta learning加快模型的微调(学习)速度
-
时域一致的超分辨率网络提高图像分辨率
环境配置
Docker(方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk-23.04-py37-latest
docker run --shm-size 10g --network=host --name=metaportrait --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -v 项目地址<绝对路径>:/home/ -it <Image ID> bash
pip install -r requirements.txt
cd sr_model/Basicsr
pip uninstall basicsr
python setup.py develop
pip install urllib3==1.26.15
Dockerfile(方法二)
docker build --no-cache -t MetaPortrait:latest .
docker run --shm-size 10g --network=host --name=metaportrait --privileged --device=/dev/kfd --device=/dev/dri --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -it <Image ID> bash
cd sr_model/Basicsr
pip uninstall basicsr
python setup.py develop
pip install urllib3==1.26.15
# 若遇到Dockerfile启动的方式安装环境需要长时间等待,可注释掉里面的pip安装,启动容器后再安装python库:pip install -r requirements.txt
Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK驱动:dtk23.04
python:python3.7
torch:1.13.1
torchvision:0.14.1
torchaudio:0.13.1
deepspeed:0.9.2
apex:0.1
2、创建虚拟环境并加载
conda create -f meta_portrait_base python=3.7
conda activate meta_portrait_base
pip install -r requirements.txt
cd sr_model/Basicsr
pip uninstall basicsr
python setup.py develop
数据集
下载地址: https://drive.google.com/file/d/166eNbabM6TeJVy7hxol2gL1kUGKHi3Do/view?usp=share_link
base_model
data
├── 0
│ ├── imgs
│ │ ├── 00000000.png
│ │ ├── ...
│ ├── ldmks
│ │ ├── 00000000_ldmk.npy
│ │ ├── ...
│ └── thetas
│ ├── 00000000_theta.npy
│ ├── ...
├── src_0_id.npy # identity_embedding可使用人脸识别模型获取
├── src_0_ldmk.npy # landmarks
├── src_0.png
├── src_0_theta.npy # 将人脸对齐到图像中心的变换矩阵
└── src_map_dict.pkl
下载地址:
(模型)https://github.com/Meta-Portrait/MetaPortrait/releases/download/v0.0.1/temporal_gfpgan.pth
(模型)https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth
sr_model
pretrained_ckpt
├── temporal_gfpgan.pth
├── GFPGANv1.3.pth
...
data
├── HDTF_warprefine
│ ├── gt
│ ├── lq
│ ├── ...
训练
1.训练warping network
cd base_model
CUDA_VISIBLE_DEVICES=0 python main.py --config config/meta_portrait_256_pretrain_warp.yaml --fp16 --stage Warp --task Pretrain
2.联合训练warping network和refinement network,需要修改config/meta_portrait_256_pretrain_full.yaml中的warp_ckpt
CUDA_VISIBLE_DEVICES=0 python main.py --config config/meta_portrait_256_pretrain_full.yaml --fp16 --stage Full --task Pretrain
3.训练sr model
cd ../sr_model
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --nproc_per_node=1 --master_port=4321 Experimental_root/train.py -opt options/train/train_sr_hdtf.yml --launcher pytorch
推理
1.生成256x256的图片
下载模型:https://drive.google.com/file/d/1Kmdv3w6N_we7W7lIt6LBzqRHwwy1dBxD/view (放入checkpoint文件夹中)
cd base_model
CUDA_VISIBLE_DEVICES=0 python inference.py --save_dir result --config config/meta_portrait_256_eval.yaml --ckpt checkpoint/ckpt_base.pth.tar
2.提升图片分辨率
cd ../sr_model
CUDA_VISIBLE_DEVICES=0 python -m torch.distributed.launch --nproc_per_node=1 --master_port=4321 Experimental_root/test.py -opt options/test/same_id_demo.yml --launcher pytorch
result


精度
| psnr | lpips | Ewarp |
|---|---|---|
| 26.916 | 0.1514 | 0.0244 |
应用场景
算法类别
风格迁移
热点应用行业
科研,教育,广媒
源码仓库及问题反馈
ModelZoo / MetaPortrait_pytorch · GitLab
参考资料
How do i try on custom test dataset? · Issue #4 · Meta-Portrait/MetaPortrait · GitHub
GitHub - 1adrianb/face-alignment: :fire: 2D and 3D Face alignment library build using pytorch
#010 How to align faces with OpenCV in Python - Master Data Science
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











