






摘要
在我们之前的工作中,我们推出了基于有监督式离散语音 token 的多语言语音合成模型 CosyVoice。通过结合两种流行的生成模型——语言模型 (LM) 和流匹配 (Flow Matching),CosyVoice 运用渐进式语义解码,在语音语境学习中展现出极高的韵律自然度、内容一致性和说话人相似度。近年来,多模态大语言模型 (LLM) 取得了显著进展,其中语音合成的响应延迟和实时性对交互体验至关重要。因此,在本报告中,我们提出了一种改进的流式语音合成模型 CosyVoice 2,它包含全面而系统的优化。具体而言,我们引入有限标量量化来提高语音 token 的码本利用率。对于文本语音语言模型 (LM),我们简化了模型架构,允许直接使用预训练的 LLM 作为主干模型。此外,我们开发了一个基于块感知的因果流匹配模型,以支持各种合成场景,从而在单个模型中实现流式和非流式合成。通过在大规模多语言数据集上进行训练,CosyVoice 2 在流式模式下实现了与人类相当的自然度、极低的响应延迟和几乎无损的合成质量。欢迎读者访问 https://funaudiollm.github.io/cosyvoice2 收听演示。
1.介绍
近年来,神经文本转语音 (TTS) 合成模型因超越传统的拼接和统计参数化方法而备受关注。这些模型在预定义特定说话人上实现了高保真度和自然度。最近的研究表明,零样本 TTS 模型能够通过模仿参考语音的音色、韵律和风格,为任何说话人合成语音。除了上下文学习 (ICL) 能力之外,零样本 TTS 模型还受益于大规模训练数据,实现了几乎与人类语音难以区分的合成质量和自然度。
最近的零样本语音合成 (TTS) 模型大致可分为三类:编解码语言模型、特征扩散模型及其混合系统。编解码语言模型利用语音编解码模型提取离散语音表征,并采用自回归或掩蔽语言模型预测语音 token记,然后通过编解码声码器将其合成为波形。[21] 也探索了连续语音表征。基于语言模型的 TTS 可以通过自回归采样生成变化丰富且韵律一致的语音。
受图像生成技术进步的启发,去噪扩散和流匹配模型已被引入非自回归 (NAR) 语音合成。早期基于扩散的 TTS 模型需要对每个文本(音素)进行时长预测,以解决文本和语音特征之间的长度差异。然而,这种僵化的对齐会影响自然度,导致韵律平淡。为了解决这个问题,交叉注意力机制和扩散 Transformer (DiT) 已被引入 NAR TTS 模型。最近的研究表明,在 NAR TTS 模型中,例如 E2 TTS、F5-TTS 和 Seed-TTS 等模型中,存在更简单的文本-语音对齐方法。在这些模型中,输入文本会用特殊 token 填充,以匹配语音总长度,而语音总长度可以由话语时长预测模块自动预测,也可以由用户提前指定。由于 NAR TTS 模型不受编解码器声码器的限制,因此它们可以实现卓越的语音质量。
混合系统结合了文本到编解码器的语言模型和编解码器到特征的扩散模型。语言模型处理文本与语音之间的对齐以及话语时长预测;而编解码器到特征的扩散模型则根据生成的编解码器和其他条件合成语音特征(梅尔谱)。通过结合两种生成模型的优势,混合系统实现了较高的多样性、韵律一致性和语音质量。
尽管最近的零样本 TTS 模型取得了成功,但它们通常以非流式(离线)模式运行,这需要完整的输入文本,并且需要合成完整的语音才能返回波形。这会导致高延迟,并对语音聊天等应用中的用户体验产生负面影响。为了解决这个问题,人们已经探索了基于语言模型的零样本 TTS 模型的流式合成,但基于扩散的 TTS 模型和混合系统缺乏成熟的流式解决方案。
在 CosyVoice 成功的基础上,我们推出了 CosyVoice 2,这是一款流式零样本 TTS 模型,在韵律自然度、内容一致性和说话人相似度方面均有提升。我们的贡献包括:
- 在单一框架中统一流式和非流式合成,并提出统一的文本语音语言模型和分块因果流匹配模型,与离线模式相比,实现无损流式合成。
- 通过删除文本编码器和说话人嵌入来简化 LM 架构,允许预训练的文本大语言模型 (LLM) 作为主干,增强上下文理解。
- 将语音 tokenizer 中的矢量量化 (VQ) 替换为有限标量量化 (FSQ),从而提高码本利用率并捕获更多语音信息。
- 升级指令式 TTS 容量,以支持更多指令,包括情感、口音、角色风格和细粒度控制。在 CosyVoice 2 中,我们将指令和 zero-shot 容量集成到一个模型中,从而实现更灵活、更生动的合成。
通过上述系统性改进和优化,CosyVoice 2 实现了与真人语音水平相当的合成质量,并且在流式模式下几乎无损。统一的框架降低了部署要求,使单个模型能够同时支持流式和非流式合成。升级后的指令式语音合成 (TTS) 容量为用户提供了更强大、更便捷的语音生成方法。此外,基于分块的 flow-matching 设计也可以应用于 NAR TTS 模型,这预示着流式 NAR 模型的巨大潜力。
2.CosyVoice 2
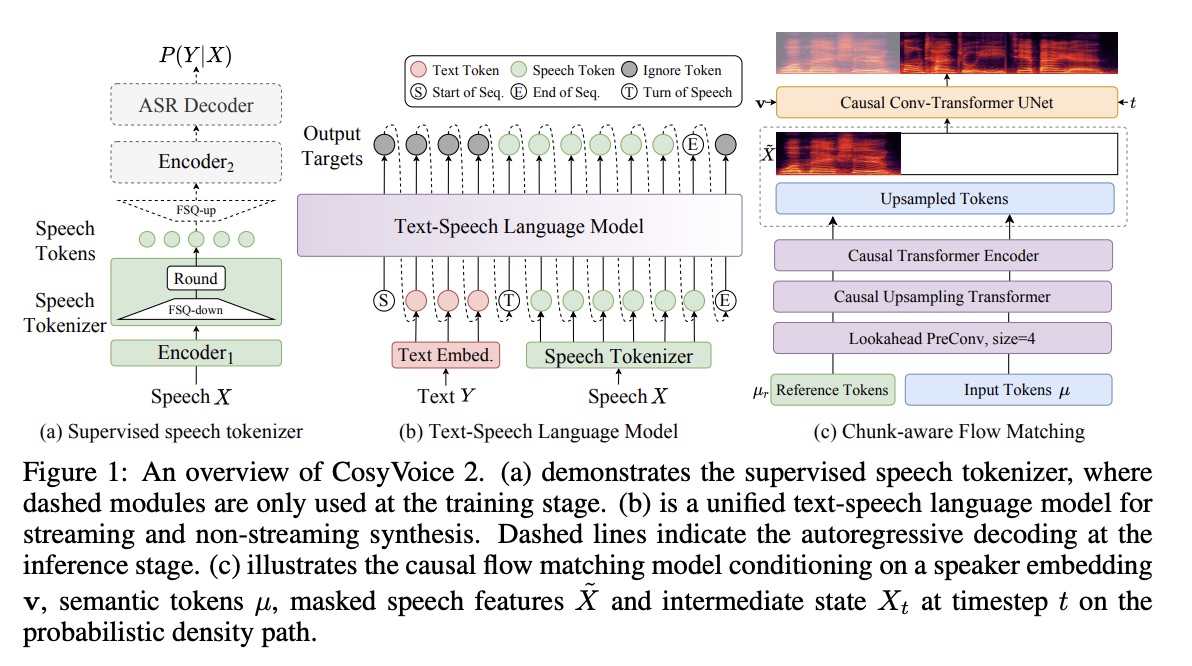
CosyVoice 2 沿用了前代产品的类似设计理念,将语音信号的语义和声学信息分离,并进行独立建模。语音生成过程被重新定义为一个渐进的语义解码过程,其中条件信息被逐步融入。具体而言,文本-语音语言模型 (LM) 专注于语义信息,将高级文本 token 解码为有监督语义语音 token。在流匹配模型中,通过说话人嵌入和参考语音引入音色等声学细节,将语音 token 转换为给定说话人的梅尔频谱。最后,一个预训练的声码器模型恢复相位,将梅尔频谱转换回原始音频信号。以下章节将从五个方面介绍 CosyVoice 2 的细节及其针对流式合成的改进:文本 tokenizer、有监督语义语音 tokenizer 、用于流式/非流式合成的统一文本-语音语言模型以及分块的流匹配模型。图 1 概述了 CosyVoice 2。
2.1 Text Tokenizer
CosyVoice 2 直接使用原始文本作为输入,并使用基于 BPE 的文本 tokenizer 进行分词。这样就无需前端模型通过字素到音素 (g2p) 转换获取音素。这种方法不仅简化了数据预处理流程,还使模型能够以端到端的方式学习不同语境下单词的发音。与文本 LLM 中常用的 tokenizer 不同,CosyVoice 2 会屏蔽掉一对多的分词。这可以防止分词的发音过长,并减少数据稀疏性导致的极端情况。具体来说,如果一个 BPE 分词器编码了多个汉字,则会被屏蔽掉,并在分词过程中对每个汉字进行单独编码。其他语言(例如英语、日语和韩语)无需进行特殊处理。
2.2 Supervised Semantic Speech Tokenizer
如图 1 (a) 所示,我们将有限标量量化 (FSQ) 模块插入 SenseVoice-Large ASR 模型的编码器中。在训练阶段,输入语音
X
X
X 经过
E
n
c
o
d
e
r
1
Encoder_1
Encoder1 获得中间表示,其中编码器 1 由六个 Transformer 模块组成,并采用旋转位置嵌入 (rotational Positional Embedding)。然后,中间表示被输入到 FSQ 模块进行量化,量化后的表示再经过 SenseVoice-Large 的其余模块(包括
E
n
c
o
d
e
r
2
Encoder_2
Encoder2 和 ASR 解码器),预测相应文本 token 的后验概率。
在 FSQ 模块中,首先将中间表示
H
H
H 投影到
D
D
D 维低秩空间,并通过有界轮询运算 ROUND 将每一维的值量化到
[
−
K
,
K
]
[−K, K]
[−K,K] 空间。然后,将量化后的低秩表示
H
ˉ
\bar H
Hˉ 投影到原始维度
H
~
\tilde H
H~:
H
ˉ
=
R
O
U
N
D
(
P
r
o
j
d
o
w
n
(
H
)
)
H
~
=
P
r
o
j
u
p
(
H
ˉ
)
(1)
\begin{array}{cc} \bar H=ROUND(Proj_{down}(H))\\ \tilde H=Proj_{up}(\bar H) \end{array}\tag{1}
Hˉ=ROUND(Projdown(H))H~=Projup(Hˉ)(1)
在训练阶段,采用直通估计法来近似 FSQ 模块和
E
n
c
o
d
e
r
1
Encoder_1
Encoder1 的梯度。语音token
µ
i
µ_i
µi 可以通过计算量化低秩表示
h
ˉ
i
\bar h_i
hˉi 在 (2K + 1) 进制中的索引来获得:
µ
i
=
∑
j
=
0
D
−
1
h
ˉ
i
,
j
(
2
K
+
1
)
j
(2)
µ_i=\sum^{D-1}_{j=0}\bar h_{i,j}(2K+1)^j\tag{2}
µi=j=0∑D−1hˉi,j(2K+1)j(2)
E
n
c
o
d
e
r
1
Encoder_1
Encoder1、FSQ模块的低秩投影器、有界轮运算和索引计算构成了CosyVoice 2的语音 tokenizer。我们的语音 tokenizer 以25 Hz的 token 速率工作,即每秒25个语音 token。
2.3 Unified Text-Speech Language Model
在 CosyVoice 2 中,我们采用预训练的文本语言模型 Qwen2.5-0.5B 作为文本-语音语言模型,以输入文本为提示,自回归生成语音 token。与其他语言模型类似,文本-语音语言模型也采用下一个 token 预测的方案进行训练,如图 1 (b) 所示。与之前的 CosyVoice 不同,我们移除了说话人嵌入,以避免信息泄露。更重要的是,我们发现这种话语级向量不仅包含说话人身份信息,还包含语言和副语言信息,这会损害文本-语音语言模型的韵律自然度和跨语言能力。此外,我们还放弃了之前 CosyVoice 中的文本编码器,因为我们发现 Qwen2.5-0.5B 模型足以对齐文本和语音 token,因此不再需要文本编码器。
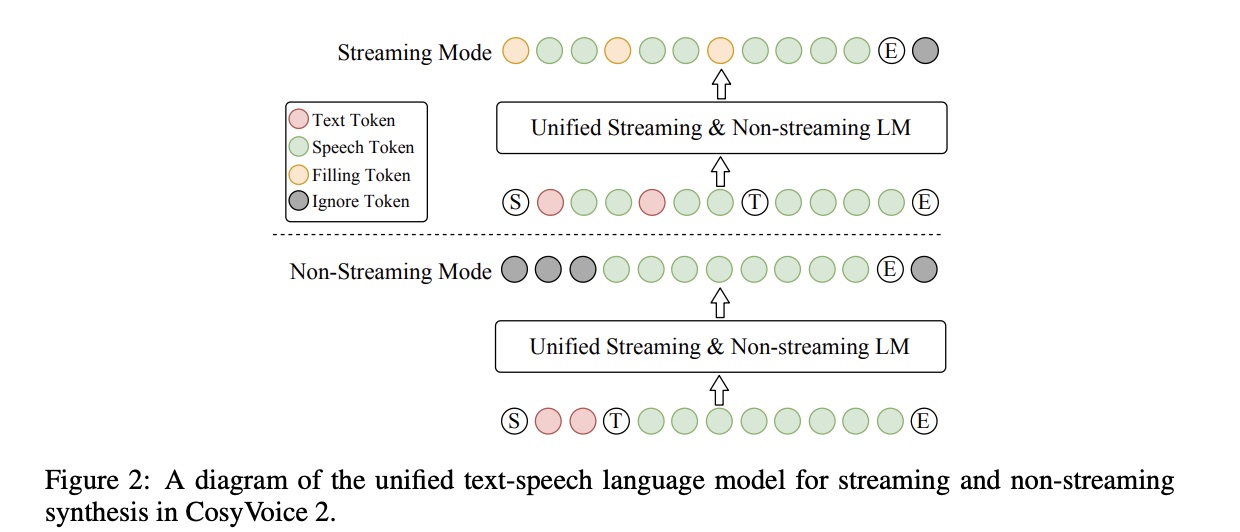
得益于文本语音语言模型 (LM) 的简单性,我们可以为流式和非流式合成构建一个统一的模型。这里的“流式模式”是指输入文本以连续流的形式接收,而不是预先知道完整的句子。在 CosyVoice 2 中,流式和非流式模式的区别仅在于 LM 的序列构建方式:
- 对于非流式模式,“序列开始” S ◯ \textcircled S S◯ 、所有文本 token、“语音轮次” token T ◯ \textcircled T T◯ 、所有语音 token 和“序列结束” E ◯ \textcircled E E◯ 按顺序连接在一起,如图 2 底部所示。忽略 token 意味着在最小化交叉熵目标函数时忽略它们的损失。
- 对于流式模式,我们按照预定义的 N:M 比例混合文本和语音 token,即每 N 个文本 token 后面会跟着 M 个语音 token ,如图 2 上图所示。如果下一个 token 是文本 token ,则模型预计会预测一个填充 token(而不是文本标记),这意味着接下来的 N 个文本 token 应该在推理阶段连接起来。文本 token 用完后,“语序” token T ◯ \textcircled T T◯ 和剩余的语音 token 将按顺序连接起来,在流式传输模式下形成混合文本-语音标记序列。在我们的实验中,N 和 M 分别设置为 5 和 15。
通过同时基于上述两个序列训练文本-语音语言模型 (LM),我们可以在一个统一的模型中执行流式和非流式语音生成。在实际场景中,例如说话人微调 (SFT) 和上下文学习 (ICL),推理序列存在以下差异:
- ICL, Non-Streaming:在 ICL 中,语言模型 (LM) 需要参考音频中的提示文本和语音 token 来模仿口音、韵律、情感和风格。在非流式模式下,提示文本和待合成文本 token 会连接成一个整体,而提示语音 token 则被视为预先生成的结果,并固定为:“ S ◯ , prompt_text, text, T ◯ , prompt_speech \textbf {\textcircled{S}, prompt\_text, text, \textcircled{T}, prompt\_speech} S◯, prompt_text, text, T◯, prompt_speech”。语言模型的自回归生成从该序列开始,直到检测到“序列结束” token E ◯ \textcircled{E} E◯。
- ICL, Streaming:在这个场景中,我们假设待生成的文本是已知的,并且语音 token 应该以流式传输的方式生成。类似地,我们将提示和待生成的文本视为一个整体。然后,我们按照 N:M 的比例将其与提示语音 token 混合:“ S ◯ , mixed_text_speech, T ◯ , remaining_speech \textbf {\textcircled{S}, mixed\_text\_speech, \textcircled{T}, remaining\_speech} S◯, mixed_text_speech, T◯, remaining_speech”。如果文本的长度大于提示语音 token 的长度,则 LM 将生成“填充 token”。在这种情况下,我们手动填充 N 个文本 token。如果文本 token用完了,则会添加“语音轮次”token T。在流式传输模式下,我们每 M 个 token返回一次生成结果,直到检测到 E ◯ \textcircled E E◯。
- SFT, Non-Streaming:在 SFT 场景中,LM 针对特定说话人进行微调,不再需要提示文本和语音。因此,初始序列非常简单:“ S ◯ , text, T ◯ \textbf{\textcircled S, text, \textcircled T} S◯, text, T◯”。以此为起点,文本-语音 LM 可以自回归地生成语音 token,直到 E ◯ \textcircled E E◯。
- SFT, Streaming:
2.4 Chunk-aware Flow Matching
2.5 Latency Analysis for Streaming Mode
2.6 Instructed Generation
为了增强 CosyVoice 2 的可控性,我们将指令数据集集成到基础训练集中。我们收集了 1500 小时的指令训练数据,其中包含自然语言指令和细粒度指令,如表 1 所示。对于自然语言指令,我们在待合成的输入文本前添加自然语言描述和特殊的结束 token “<|endofprompt|>”。这些描述涵盖了情绪、语速、角色扮演和方言等方面。对于细粒度指令,我们在文本 token 之间插入 Vocal Bursts,使用“[laughter]”和“[breath]”等 token。此外,我们还为短语添加语音特征标签;例如,“ < s t r o n g > X X X < / s t r o n g > <strong>XXX</strong> <strong>XXX</strong>”表示强调某些词语,而“ < l a u g h t e r > X X X < / l a u g h t e r > <laughter>XXX</laughter> <laughter>XXX</laughter>”表示带笑声说话。
2.7 Multi-Speaker Fine-tuning
针对特定说话人 (SFT) 对预训练模型进行微调可以进一步提升生成质量和说话人相似度。在本报告中,我们引入了多说话人微调 (mSFT),即同时针对多个说话人(而非单个说话人)对预训练模型进行微调。这种方法可确保跨多个说话人全面覆盖韵律和发音,并减轻预训练模型可能出现的灾难性遗忘。为避免不同说话人之间的音色混淆,我们在特定说话人的输入文本前添加说话人提示标签““Speaker A<|endofprompt|>”。如果训练样本未标记说话人,则使用特殊标签““unknown <|endofprompt|>”。在整个多说话人微调过程中,学习率设置为 1e-5。

















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









