







在深度神经网络中,随着网络层数的增加,模型的性能可能会出现不升反降的现象,这就是网络退化(Network Degradation)问题。具体而言,当网络过深时,模型的训练会变得非常困难,准确率可能在达到某个峰值之后迅速下降,这通常是由于梯度消失或梯度爆炸造成的
残差连接(Residual Connection)的提出正是为了解决这一问题。ResNet(Residual Networks)通过引入残差连接,能够有效避免梯度消失和梯度爆炸问题,同时确保网络的深度不会影响到模型的表现
目录
1 残差连接 Residual Connection
1.1 定义
残差连接的核心思想是跳跃连接,即直接将某一层的输入 x 加上其输出 f(x),并作为该层的最终输出。这样,即使网络变得非常深,网络的效果也不会比浅层网络差
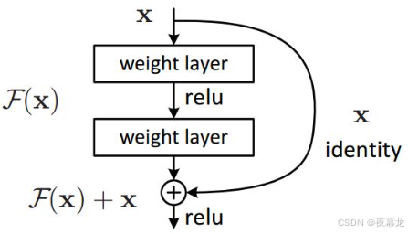
简言之,残差连接通过保持信息流动,使得网络更容易训练,并能在深层网络中保持较好的性能
这种结构的优势在于,它能够帮助网络保持稳定的梯度流动,避免深层网络的退化问题
1.2 Transformer中的残差连接
Transformer 模型中的编码器和解码器都使用了层标准化+残差连接的组合。这种结构的核心思想是,在每个子层之后,先进行层标准化,然后再通过残差连接进行处理。具体而言:
-
编码器部分在经过自注意力层和前馈神经网络之后,都会分别进行层标准化和残差连接。这种设计确保了每一层的输出能够稳定传递,并避免了梯度消失或爆炸的问题
-
解码器部分则分为三个部分:自注意力层、编码器-解码器注意力层和前馈神经网络,每一部分之后都会经过层标准化和残差连接
2 线性层与Softmax层
在 Transformer 模型中,解码器的最终输出是一个浮点向量,但我们希望将这个输出转换为一个词元(Token),即模型最终生成的单词。为此,Transformer 模型使用了一个线性层,该层是一个全连接神经网络,它将解码器的输出向量投影到一个更高维度的向量空间中,称为 logits 向量。logits 向量的维度与词汇表的大小一致,其中每个元素代表了该词元的得分
接下来,需要将这个 logits 向量转化为概率分布,以便选择最有可能的词元。为此,使用了Softmax 层。Softmax 函数将 logits 向量中的每个得分转化为概率值,确保所有概率之和为1。具体地,Softmax函数的计算公式如下:
其中,zi 是 logits 向量中的第 i 个元素,表示第 i 个词元的得分
Softmax 层将这些得分转化为概率,最后通过选择概率最大的元素,来决定该时间步的输出词元
3 损失函数与模型训练
3.1 损失函数
在 Transformer 模型的训练过程中,我们需要一种损失函数来衡量模型的输出与真实标签之间的差异。比较两个概率分布的最常见方法是计算它们的交叉熵(Cross-Entropy)或KL散度(Kullback-Leibler Divergence)。这两者的目标是通过量化预测概率分布与目标分布的差距,帮助模型调整参数,从而逐渐优化预测结果
3.1.1 交叉熵损失函数
在NLP任务中,通常会使用交叉熵损失函数,它可以有效地量化模型输出的概率分布与目标词汇分布之间的差异
具体地,我们在分词阶段创建了一张标准词汇表,其中每个词都由一个固定维度的向量表示。最常见的向量表示方法是 one-hot 编码。在 one-hot 编码中,每个词元都对应一个独立的索引,向量中该词元对应的位置值为1,其他位置值为0
例如,如果词汇表中包含的词是 ["cat", "dog", "fish"],那么"cat"的one-hot编码就是 [1, 0, 0],"dog"是 [0, 1, 0],"fish"是 [0, 0, 1]
在训练过程中,模型的输出是一个 logits 向量,表示每个词元的得分。损失函数通过比较这个输出向量与真实的 one-hot 标签向量之间的差异,来计算损失值。交叉熵损失函数的计算公式为:
其中,yi 是真实标签的 one-hot 向量,pi 是通过 Softmax 层得到的预测概率。通过最小化损失函数,模型可以逐步调整其参数,使得预测的概率分布更接近真实标签
3.1.2 KL散度
KL散度用于衡量一个概率分布与另一个概率分布之间的差异。与交叉熵类似,KL散度越小,模型的预测结果与目标分布越接近。KL散度的公式为:
其中,P 是真实分布,Q 是预测分布。KL 散度的值越小,说明模型输出的概率分布越接近期望的真实分布
3.2 模型训练
在 Transformer 实际应用中,我们的输入通常是多个词的序列。例如,输入可能是“你好世界!”,期望的输出是“Hello World!”。在这种情况下,Transformer模型不仅要预测一个词的概率分布,而是需要连续预测多个词的概率分布
对于每一个输入词,模型将生成一个概率分布序列,每个概率分布对应词汇表的大小。具体而言,模型会为每个词生成一个宽度等于词汇表大小的向量,并将每个词的最大概率位置作为该词的输出。这些概率值代表了每个词元出现的概率,模型通过选择概率最大的位置来确定输出的单词。
例如,假设我们的词汇表中包含“Hello”、“World”、“!”等词元。在翻译“你好世界!”时,模型会生成如下的概率分布序列:
- 对于“Hello”:模型可能输出[0.1, 0.7, 0.05, ..., 0.1],表示“Hello”有较高的概率
- 对于“World”:模型可能输出[0.05, 0.3, 0.5, ..., 0.1],表示“World”有较高的概率
这些概率分布会随着训练的进行逐步调整,最终通过优化损失函数,使得输出的概率分布越来越接近真实标签
在训练过程中,目标是让模型逐步生成与期望输出接近的概率分布。虽然完全一致是不可能的,训练的目标是通过不断调整模型的参数,降低损失函数的值,从而使得模型的输出越来越接近目标输出。最终,训练得到的模型应该能够生成输出概率分布,接近期望的翻译结果或文本生成结果
损失函数的值通过反向传播(Backpropagation)算法被传递回模型,以更新模型的参数。通过反向传播,损失函数的梯度将被计算出来,并通过梯度下降(或其他优化算法)来调整模型的权重。随着训练的进行,模型会越来越准确地生成概率分布,从而提高预测的准确性和输出质量


















 1170
1170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









